17 common Google indexing issues: How to identify and fix them
Have you ever put all your efforts into creating high-quality content only to find out your web pages aren’t even showing in SERPs? No matter how well you optimize for search engines, your content remains invisible. Frustrating, isn’t it? Website indexing problems could be to blame.
This guide will outline the most common issues preventing search engines from indexing your website’s pages and offer solutions to fix them. Addressing these indexing challenges can ensure your website appears in SERPs and reaches its full potential.
Key takeaways
Page indexing issues prevent search engines from finding and including webpages in their search index. These webpages therefore cannot show up or rank in SERPs.
Still, there is a list of pages that shouldn’t be indexed. These include duplicate/alternate content pages, private pages (login pages/account pages/pages with confidential information), sorting/filtering pages, and so on.
Here are some possible causes of indexing issues:
- Bad content quality (thin or duplicate content).
- Technical issues (robots.txt blocking, incorrect canonical tags, or HTTP status code issues like 404s).
- Site structure & speed (poor internal linking, slow site loading, or blocking of essential resources like JavaScript, CSS, and images).
- Penalties (manual penalties from Google can block indexing altogether).
- Other factors (suspicious code, exceeded crawl budget, new website, or indexing problems on Google’s side).
The most common indexing issues are caused by:
- Server Errors (5xx)
- Redirect Errors
- Hidden Pages (URL marked “noindex”; URL blocked by robots.txt)
- Missing Content or Access Permission (Soft 404; Blocked due to unauthorized request (401); Not Found (404); Blocked due to access forbidden (403); URL blocked due to other 4xx issues; Server Errors (5xx)).
- Conflicting Indexing Signals (Duplicate without user-selected canonical; Duplicate, Google chose different canonical than user; Page with redirect; Indexed, though blocked by robots.txt; Page indexed without content).
SEO pros detect indexing issues by combining the use of Google Search Console (GSC) with dedicated SEO tools like SE Ranking.
Understanding website indexing problems
Let’s begin with the basics and explore the ins and outs of the indexing process.
Indexing is how search engines discover, analyze, and store information about your website’s content. But how does Google find these pages?
Google’s web crawlers follow external links from existing web pages and check the sitemaps website owners provide on those sites. This ensures Google can build an index of web pages across the web.
If you haven’t set up a sitemap yet (or aren’t sure if yours is optimized), check out our guide to creating a sitemap. It covers what to include, how to structure it, and how to submit it properly to search engines.
If your website has indexing problems, it becomes invisible to search engines. This means potential visitors will not be able to find your website through organic searches.
When deciding whether to index a page, Google’s algorithms analyze each webpage for relevancy and quality. Google observes a wide range of factors, including the content’s goal, freshness, clarity, and alignment with E-E-A-T criteria, as well as internal linking, loading speed, canonical tags, robots meta tag and X-Robots-Tag.
Content quality is a major factor. Low-quality content is the most likely to be ignored. Some examples of low-quality content include content that provides little to no value, content generated solely to manipulate rankings, or content that lacks originality/credibility/clarity/expertise. On the other hand, you can improve your indexability and ranking potential by creating high-quality content that aligns with E-E-A-T criteria and has backlinks from relevant websites.
Technical SEO issues also often cause Google indexing problems. Robots.txt files that block important pages, incorrectly configured sitemaps (or no sitemap at all) can confuse search engines and affect their ability to crawl and index your site. Unethical SEO practices like keyword stuffing can get your site penalized and removed from SERPs altogether.
In this article, we’ll explore the most common causes of indexing issues in detail.
Why some pages shouldn’t be indexed
Now that we’ve clarified that Google indexing issues harm the website’s overall presence, visibility, and rankings, let’s also consider that not all pages need to be indexed by search engines. In fact, some pages will benefit more if they are intentionally hidden from search engines.
Here are some page types that you can exclude from search engine indexing without harming your SEO:
1. Pages hidden behind a login.
Think of your online shopping cart or account page. These pages are meant for your eyes only; search engines have no business crawling them. They are often hidden behind a login and password, which results in Google receiving the “401 Unauthorized” status code response and ignoring the page content.
2. Duplicate or alternate pages.
Some websites contain multiple versions of the same content resulting from filters or sorting options. Search engines prefer unique content, so they might index only one version (the canonical URL) and leave the rest out. This is perfectly normal behavior, and the warning you see in GSC for these pages confirms that Google found the right page.
3. Website search.
Websites typically create search pages dynamically from user searches. These user-generated search pages generally are not worth indexing, as they function more like a map and help users find specific content within the website. Use a “noindex” tag to block these pages from search engines. This helps search results focus on your unique and valuable content.
4. Administrative pages.
The backend of your website is meant for managing content and settings, and not for public view. Admin pages are often blocked by robots.txt files, which tell search engines not to crawl them. Warnings for these are nothing to worry about.
The bottom line is that if a page is intentionally blocked from search engines for a valid reason, Search Console warnings are a good sign. They confirm that search engines are respecting your instructions and focusing on the parts of your website that deserve to be seen in SERPs.
Possible causes of indexing issues
Many factors can prevent search engines from indexing your pages. In this section, we’ll explore the most common causes.
Duplicate content
Having identical or similar content on multiple pages leads to ranking and traffic losses. This happens because Google can’t tell which pages are most relevant and valuable for a specific search. It doesn’t know which ones to prioritize. Even worse, if Google thinks you’re producing duplicate content to manipulate SERP results, it might completely remove your pages from its search index.
Low-quality content
Content quality has been a significant ranking factor for many years, but the introduction of the Helpful Content system has greatly increased its importance. As of now, content lacking originality or relevance is less likely to rank well, or even get indexed. So, be sure to reduce unoriginal, irrelevant content that provides little to no value to users and/or is created with the primary goal of improving rankings. In particular, this includes AI-generated content or content translated from another language that doesn’t add unique value.
Blocked by robots.txt
The primary function of the robots.txt file is to instruct search engines which parts of your site they can and cannot crawl. When you disallow crawling, search engine bots cannot access and index your content. You can check whether your URLs have or haven’t been blocked by your robots.txt file by using the robots.txt tester.
Blocked by noindex tag or header
You can also instruct search engines to index a specific page using a robots meta tag and the X-Robots-Tag HTTP header. This is useful for certain pages with private information, admin areas, duplicate content, and other low-value pages. Be careful though. If you add these tags to important pages, they will disappear from SERPs entirely.
Incorrect canonical tags
Canonical tags are typically used to tell search engines which page (out of those with similar or identical content) to prioritize for indexing purposes. Google will make the decision on its own if you don’t specify which URL to prioritize. This can occasionally result in severe canonical tag issues. For example, it may index the wrong version of the webpage.
HTTP status code issues
HTTP status codes in the 4xx and 5xx classes usually mean there are problems accessing content. When Google encounters a 4xx error, it ignores that page’s content. This includes any content on already indexed URLs that now show 4xx errors. 5xx errors (server problems) might temporarily slow down Google’s crawling. But if these issues persist, Google may remove previously indexed pages from its search results.
Internal linking issues
A solid website structure with good internal linking not only enhances user experience but also helps Google crawl and index the site’s pages. Internal linking issues like broken links or orphaned pages (pages with no internal links pointing to them) can confuse search engines, making it harder for them to find and understand your content.
Slow-loading pages
Since Google constantly aims to provide a positive user experience, the fact that slow-loading pages lead to indexing issues is not surprising. Slow loading times frustrate users, increasing the chance that they will leave before taking an important action for your business. High bounce rates signal to Google that your content lacks value or relevance. Slow website loading times also hurt your Core Web Vitals scores, which directly impact search ranking. To check the speed of your website, you can use PageSpeed Insights or SE Ranking’s Website Speed Test.
Blocked JavaScript, CSS, and image files
JavaScript, CSS, and image files provide crucial information on visual layout, interactive features, and even content itself (like images). Blocked resources can make the webpage appear broken to search engines. This prevents Google from fully rendering the page. This can lead to inaccurate indexing and lower search rankings.
Exceeded crawl budget
Each site has a dedicated crawling budget (the number of pages bots can crawl within a specific timeframe). Exceeding your crawl budget may prevent some of your pages from being crawled and indexed. Large websites (10,000 pages or more) are the most likely to face this problem.
To remain under the limit, manage your URL inventory by consolidating duplicate content, marking removed pages with a 404 or 410 status code, keeping your sitemaps up to date, and avoiding long redirect chains. You should also optimize your website for fast loading times, constantly monitor its crawling for availability issues, and prioritize existing pages by setting priority levels in XML sitemaps.
Brand new website
Even if you have finished setting up your new website, Google may still need time to crawl and index it. Since Google has a wide backlog and crawls websites at different speeds, it could take anywhere from hours to weeks for the search engine to find your new website.
In the meantime, focus on three key strategies. First, keep adding relevant content to your site. After that, follow the best SEO practices in all your optimizations. The last strategy involves building quality backlinks from trusted, high-authority websites. These quality backlinks can signal your site’s importance to Google, potentially speeding up the crawling and indexing process.
Suspicious code
To understand what your site is about, Google must be able to see all of its content, including text, links, and formatting. Google cannot index it properly otherwise. If you intentionally or unintentionally make it difficult for Google’s bots to access your files (e.g., through aggressive cloaking), this could discourage Google from indexing your site effectively. The problem becomes even more serious if hackers tamper with your website’s code, such as injecting malicious scripts or adding hidden links.
Always prioritize website security and keep your code clean and easy to read. Neglecting this can hurt your search rankings or even get your pages dropped from the search index.
Manual action penalty
While Google penalties don’t directly remove your site from SERPs, severe manual actions (e.g., those related to spam or deceptive practices) can cause temporary or permanent de-indexing. This is because Google prioritizes user experience and aims to protect users from potentially harmful content. Plus, restricting indexing during a review allows Google to gather evidence and prevent manipulation of search results by the website owner.
Google index problems
Technical glitches on Google’s end can delay indexing. This increases the time it takes for your content to appear in SERPs. Keep in mind that GSC gets its data from Google’s index. So during indexing issues, GSC might show incomplete or inaccurate information. When this happens, stay informed by checking Google’s announcements about the problem.
How to detect website indexing issues
There are several methods that you can use to check for indexing issues on your website. The most effective ones include using GSC or a reliable SEO platform. Let’s explore each method in detail.
Google Search Console
GSC can provide insightful SEO information about your website’s indexing status. Its index coverage report (Page Indexing) helps you track which of your website’s URLs Google has successfully crawled and indexed. It also outlines a list of issues that might be preventing other pages from being indexed.

Focus on URLs with the Not Indexed status when exploring this report. Scroll down to see the Why Pages Aren’t Indexed section. This will give you an understanding of why Google decided not to index certain URLs.

The following reasons are the most common:
1. Drop in total indexed pages without corresponding errors
If you notice your website has fewer indexed pages and no new error message, you might have accidentally blocked Google’s access to some of your existing content.
Try out this trick: Look for a jump in Not Indexed URLs that coincides with the drop in indexed pages. This spike could be a sign that something is preventing Google from seeing your content.
2. More non-indexed than indexed pages
You may come across some instances where more pages don’t appear in search results (not indexed) than ones that do. This usually happens for two reasons. The first is that your site has a rule that accidentally blocks search engines from crawling important sections. The second is that your site has duplicate content (e.g., from filtering or sorting options) that search engines consider less valuable.
3. Error spikes
You may occasionally encounter a sudden jump in errors. This results from the two following instances:
- If you have recently updated your website’s design, there might be a bug in the new template causing these errors.
- If you have recently submitted a sitemap, it might contain pages that Google can’t access (since they are blocked by robots.txt, hidden with a “noindex” tag, require a login, etc).
4. 404 errors
Googlebot may struggle to reach your web page. This typically happens after the page has been removed from the website or when the internal link pointing to it has become broken (directing to a non-existent page). Because of this, Googlebot couldn’t process your page and was forced to abandon the request.
5. Server errors
Search bots need smooth interaction with your server to efficiently index your website. If server errors occur, crawlers might see them as a sign of a low-quality or unstable site. This can lead to your website being de-prioritized for indexing or even dropped entirely from the search index.
Although the URL Inspection Tool can help you diagnose server errors reported by the Page Indexing report, these errors could be temporary. This means that your test has the chance to succeed even if Google encountered server issues earlier.
6. Missing pages or sites
Here are some instances that could prevent your page from being featured in the Page Indexing report:
- Google might not be aware of the new pages yet (it takes time to discover them).
- Google needs to find a link to your page or have a sitemap submitted to know it exists.
- Google might not be able to reach your page (login required, blocked access, etc.).
- The page might have a “noindex” tag specifically telling Google not to index it.
Apart from the Page Indexing report, SEOs regularly check the Security & Manual Actions section. Why? Because any penalties found there, like spammy tactics or site reputation abuse, can lead to lowered rankings or even removal from search results altogether.

The Manual Actions report lists issues found by human reviewers at Google, usually related to attempts to trick Google’s search system rather than directly harming users. The Security Issues report, on the other hand, warns about potential hacking or harmful content on your site, such as phishing attacks, malware installations, or unwanted software on the user’s computer.
Anyway, being listed in any of these reports can cause significant Google indexing issues for your website.
SE Ranking
Tracking your indexing status with tools like GSC is useful, but there are faster ways to find and fix indexing issues than Googlebot.
For example, SE Ranking’s Website Audit tool can run an SEO audit on demand and provide an in-depth indexing report within minutes, allowing you to start fixing detected issues immediately.
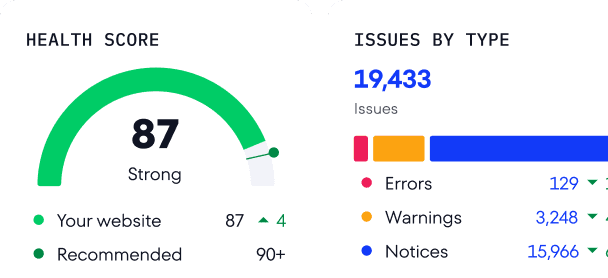
Once the audit report is ready, navigate to the Overview section and scroll to the Page Indexability block.

You will see a dashboard with a graph showing the number and percentage of your pages that can be indexed compared to those that can’t. The dashboard also provides insights into why pages might not be indexed, such as robots.txt blocking, meta noindex tags, non-canonical URLs, and more. Click on the graph to explore a detailed Crawled Pages report.

This report breaks down individual pages with parameters like referring pages, number of detected issues, status codes, robots.txt directives, canonical URLs, and more.

SE Ranking’s functionality allows you to easily filter pages Blocked by noindex and Blocked by X-Robots-Tag. Since these pages shouldn’t even be indexed in the first place, you can remove them from the “fix” list.

The Crawling section of the Issue Report provides similar indexing information.

You can also use this report to sort identified insights by errors and review a categorized list of problems that may affect indexing on your website, such as duplicated content, HTTP status code issues, and issues with redirects, site speed, CWV, etc.

For a quick indexing status check across different search engines, use SE Ranking’s Index Status Checker.

After addressing indexing problems, the next step is to monitor your website’s search engine performance. This will help you understand how your improvements contributed to increased rankings, visibility, and organic traffic. This is where Rank Tracker can come in handy. This tool features precise daily ranking updates on search engines like Google (desktop & mobile), Bing, Yahoo, and even YouTube.
Indexing errors in Google Search Console (+ simple fix tips)
Now that you understand how to detect website indexing issues, let’s review the most common problems you might face and quick tips for fixing each one.
Server error (5xx)
Server errors typically occur when Googlebot fails to access a webpage. This results from issues like crashes, timeouts, or server downtime.
How to fix:
First, use the GSC Inspect URL tool to see if the error persists. If it’s resolved, request reindexing. If the error remains, the solution will depend on the specific error. You will frequently need to accomplish tasks like reducing excessive page loading for dynamic page requests, verifying your server health (check if it is down, overloaded, or misconfigured), and ensuring you’re not accidentally blocking Google crawlers.
After addressing the issue, request reindexing to prompt Google to recrawl the page.
Redirect error
Here is a list of redirect errors Google might detect on your website:
- Redirect chain is too long
- Redirect loop
- Exceeded redirect URL length
- Broken or incomplete URL in the redirect chain
How to fix:
To detect and fix redirect issues, use dedicated tools like SE Ranking’s Free Redirect Checker. This tool lets you see the number of redirects your URLs have, identify redirect types, find redirect chains, and discover where short encrypted URLs lead.
URL blocked by robots.txt
This error means that search engines can’t access a specific page on your site. It occurs when instructions within your robots.txt file restrict access to the page. It could either be intentional or a mistake in the file itself.
How to fix:
Confirm that only the intended pages are listed for blocking. If you find pages you want indexed that are blocked, modify the rules in your robots.txt file to allow access to those pages. This can be done by removing or editing specific lines or adding allow directives.
URL marked “noindex”
Google encountered a “noindex” directive, so it didn’t include the page in its index. If this is what you intended, then everything is working as expected. Remove this directive if you want Google to index the page.
How to fix:
Remove any “noindex” tags for important pages that you want crawlers to find and index. Conversely, for pages you don’t want search engines to discover, leave them as they are (with the “noindex” tags).
Soft 404
A soft 404 error occurs when a user lands on a URL that displays a message saying the page is missing. In this scenario, the page technically exists according to the success code (200) sent by the server. This can happen for various reasons, including missing server files, connection issues, internal search result pages, problems with JavaScript files, and more.
How to fix:
Check if the URLs are actually missing content and if so, return a proper 404 code. If the content is still relevant, make sure the page reflects that and isn’t misleading both search engines and users.
Blocked due to unauthorized request (401)
A 401 error means that Googlebot has failed to reach a particular webpage and requires authorization.
How to fix:
If you want these pages to be found in SERPs, either grant Googlebot access or make the pages publicly accessible.
Not found (404)
This error means that Google discovered webpages on your site that return a 404 Not Found (they no longer exist). These URLs might have been linked from other websites or previously existed on your site.
How to fix:
If any key pages return this error, you must either restore the original content or use a 301 redirect to send the URL to a relevant alternative.
Blocked due to access forbidden (403)
This error code means that the user agent provided credentials but lacked permission to access this resource. Since your website’s security settings are accidentally blocking Googlebot from seeing your content, it can’t get indexed or included in SERPs.
How to fix:
If you want this page to be indexed, grant access to all public users or just Googlebot (but double-check its identity).
URL blocked due to other 4xx issue
This error means that your webpage is affected by one of the 4xx HTTP response codes other than 401, 403, 404, or Soft 404.
How to fix:
Use a URL Inspection Tool to see if you can reproduce the error. If these are important pages and you want search engines to find them, you must investigate the cause of the error (e.g., bugs in your website’s code or temporary problems with your web server) and fix it.
Crawled – currently not indexed
As the name of this error suggests, the URL has been crawled but not added to Google’ssearch index yet. Google takes time to prioritize which pages to index, so your page may simply be waiting its turn.
How to fix:
There’s no need to ask for reindexing. Just wait while Google works on indexing your webpage (assuming no blocking instructions prevent it).
Discovered – currently not indexed
This error suggests that Google has discovered your webpage but hasn’t yet crawled or indexed it. This error typically occurs when Google reschedules the crawl, often to avoid overloading the website.
How to fix:
As in the previous case, you’ll need to wait patiently for Google to crawl and index your webpage.
Alternate page with proper canonical tag
The URL returning this message doesn’t get indexed as it’s a duplicate of a canonical page.
How to fix:
This page points to the canonical page, so there is nothing you need to do.
Duplicate without user-selected canonical
This URL is a duplicate of another webpage on your site. Since you didn’t specify the canonical page, Google has selected another version for you.
How to fix:
If you disagree with Google’s pick for the canonical URL, tell search engines which URL you prefer. Some commonly used methods to specify a canonical URL are described in Google’s documentation. If you believe this page deserves its own space in search results and isn’t a copy of another page chosen by Google as canonical, rewrite the content on both pages to make it unique.
Duplicate, Google chose different canonical than user
This message means you marked this page as the preferred version, but Google chose a different one. It indexed the non-preferred version.
How to fix:
Use the URL Inspection Tool to check which URL Google considers the main version of this webpage.
Page with redirect
This is a non-canonical URL that sends visitors to a different page that may or may not be included in SERPs. Google will not index the webpage returning this message.
How to fix:
To identify the indexing status of the canonical URL associated with this webpage, analyze it using the URL Inspection Tool. Still, keep in mind that not all redirects are treated equally by search engines. Using a 301 when a 302 is needed (or vice versa) can affect whether a page is indexed and how link equity is passed. Learn the difference in our 301 vs. 302 redirect guide.
Indexed, though blocked by robots.txt
Even though you blocked this URL using the robots.txt file, it still appears in SERPs. While search engines usually follow robots.txt instructions, they can still find your page if it is linked by other websites. Google may not directly crawl the blocked page, but it can use information from sites linking to it to understand what your blocked page is about and include it in SERPs.
How to fix:
To prevent this page from showing up in SERPs, add a “noindex” tag to the page instead of robots.txt. To get Google to index this page, edit your robots.txt file to allow access to it.
Page indexed without content
This error means that the URL has been listed in Google’s search index, but Google couldn’t find any information on it. This error can occur due to the following reasons:
- Сloaking
- Not enough content
- Render-blocking content, which doesn’t load properly
How to fix:
To see how Google views your URLs, manually review the webpage and use the URL Inspection Tool in GSC. Fix any issues like missing or render-blocking content. Once fixed, ask Google to reindex the URL.
How to ask Google to validate fixed indexing issues
Let’s say you’ve fixed an issue and want to inform Google that your webpage is ready to be reindexed. Here’s how to do it:
- Open the Page Indexing report and select the issue details page.
- Click Validate Fix to let Google know you’ve addressed the issues listed on the pages.

Validation can take some time (usually around two weeks, but sometimes longer). Google will notify you once the process is completed. If validation succeeds, congratulations! Your desired URLs can now be indexed and appear in SERPs.
If validation fails, you can see which URLs are to blame. Just click on the See Details button on the issue details page. Then, fix indexing issues again to ensure all changes are applied to each listed URL. Now you can try to restart validation.
To sum up
It can be nerve-wracking to see your webpages returning indexing errors, especially for URLs crucial to your SEO strategy. The good news is that most indexing issues detected by GSC are a simple fix.
The bottom line? Understanding which pages should and shouldn’t be indexed is key. Only then should you use robots.txt and “noindex” tags to guide search engines to your preferred webpages for indexing.
If you encounter indexing issues, don’t panic. Review the brief descriptions of each issue and follow the fix tips described in this guide to resolve them quickly.

