Your Comprehensive SEO Guide to Search Engine Indexing
Ever wonder how websites get listed on search engines and how Google, Bing, and others provide us with tons of information in a matter of seconds?
The secret of this lightning-fast performance lies in search indexing. It can be compared to a huge and perfectly ordered catalog archive of all pages. Getting into the index means that the search engine has seen your page, evaluated it, and remembered it. And, therefore, it can show this page in search results. Without this stage, working on your website’s SEO is pointless. If your site’s pages cannot get indexed, they also can’t rank in search results and drive traffic.
Let’s dig into the process of indexing from scratch to understand:
- What search engine indexing is and how to index your website
- How search engines collect and store information from billions of websites, including yours
- Why indexing is important for SEO
- How to manage this process to ensure search engines index your website faster
- How to restrict site indexing
- What you need to know about using various technologies that affect indexing
- How to check your website’s indexing
Key takeaways
- Your page cannot appear in search results without indexing, making it an important first step for any SEO strategy.
- During the indexing process, pages are added to the catalog (search engine index) based on their quality and relevance.
- Search engines employ an inverted index system to store data and quickly retrieve relevant pages for search queries.
- You can monitor indexing status with tools like Google Search Console, SE Ranking, and site: search operator. These tools ensure that all important pages are indexed properly.
- Different web development technologies, such as Flash, JavaScript, AJAX, and SPAs, affect how search engines index website content in various ways.
What is search engine indexing?
Search engine indexing is the process by which a search engine analyzes and stores website pages to build its index (database of content). This allows the search engine to display the pages in SERPs.
To participate in the race for the first position in SERP, your website has to go through a selection process:
Step 1. Web spiders (or bots) scan all the website’s known URLs. This is called crawling.
Step 2. The bots collect and store data from the web pages, which is called indexing.
Step 3. And finally, the website and its pages can compete in the game trying to rank for a specific query.

In short, if you want users to find your website on Google or Bing, it needs to be indexed: information about the page should be added to the search engine database.
Keep in mind that indexing and crawling are two separate processes. Crawling refers to discovering content and indexing refers to storing said content. If your page has been crawled, this doesn’t mean that it is indexed.
Now, let’s look at the methodology behind search indexing.
How does search engine indexing work?
The search engine scans your website to determine its purpose and discern the type of content on its pages. If the search engine likes what it sees, it may store copies of the pages in the search index. The search engine stores each page’s URL and content information. Here is how Google describes this process:
“When crawlers find a web page, our systems render the content of the page, just as a browser does. We take note of key signals—from keywords to website freshness—and we keep track of it all in the Search index.”
Web crawlers index pages and their content, including text, internal links, images, audio, and video files. If crawlers consider the content valuable and competitive, the search engine will add the page to the index. It will then be in the “game” to compete for a position in search results for relevant user search queries.
During indexing, Google determines if the page showing in search is a copy or the original (the canonical). It begins this evaluation by organizing similar pages into groups. It then assigns canonical status to the most representative one. The rest are considered alternative versions and used in other situations, including mobile search results or specific queries. Google also notes details about the canonical page, such as language, location, and user-friendliness. This information helps Google decide on which pages to show in search results.
Keep in mind: Google only adds pages to the index if they contain quality content. Pages engaging in shady activity like keyword stuffing or link building with low-quality or spammy domains will be flagged or ignored. Google algorithm updates, especially core updates, impact indexing in SEO. If Google doesn’t find significant portions of a site valuable for search results, it may decide not to invest time crawling and indexing the entire site.
What is a search engine index?
A search engine index is a massive database containing information about all pages crawled, analyzed, and stored (over time) by the search engine. The index contains brief info and summaries about each page. When you enter a search query, the search engine quickly scans its list of saved content to pull up the most relevant web pages for display in SERPs. It’s like a librarian looking for books in a catalog by their alphabetical order, subject matter, and exact title.
Without an indexed catalog, search engines could not instantly present helpful pages in response to your queries.
What is an inverted index?
An inverted index is a system that helps you store and search textual data as efficiently as possible.
In a traditional index, data is organized by document, with each page listing the terms it contains. An inverted index reverses this, associating each term with a list of documents that contain it.
This inverted structure allows search engines to quickly find relevant documents for a given search query by looking up each term and retrieving the corresponding document list.
This efficient data structure enables search engines to return query results almost instantaneously, even across billions of pages.
Why is indexing important for SEO?
The answer is simple. If search engines don’t index a page, it won’t appear in search results. This page will therefore have zero chance of ranking and getting organic traffic from searches. Without proper (or any) indexing, even an otherwise well-optimized page will remain invisible in search.
In short, getting indexed is the vital first step before any SEO efforts can have an impact on organic search performance.
Getting search engines to index your site faster
Presenting your website (or new pages within it) is a surefire way to get the search engine’s attention. Some popular and effective methods for grabbing the attention of search engines include submitting a sitemap or individual URLs to Google and Bing, internal linking, acquiring backlinks, and engaging on social media.
Let’s explore these methods in more detail:
XML sitemaps
To make sure we are on the same page, let’s first refresh our memories. The XML sitemap is a list of all the pages on your website (an XML file) crawlers need to be aware of. It serves as a navigation guide for bots. The sitemap does help your website get indexed faster with a more efficient crawl rate.
Sitemaps serve as roadmaps for search engine crawlers. They can direct crawlers to otherwise ignored areas of the website. Sitemaps helps you specify which pages are the highest priority for indexing in SEO. They also notify search engines about new and updated content to index. For large sites, sitemaps ensure no pages are missed during crawling.
If you still don’t have a sitemap, read our guide to successful SEO mapping.
Once you have your sitemap ready, go to your Google Search Console and:
Open the Sitemaps report ▶️ Click Add a new sitemap ▶️ Enter your sitemap URL (normally, it is located at yourwebsite.com/sitemap.xml) ▶️ Hit the Submit button.

You can also submit a sitemap in Bing Webmaster Tools. Open the Sitemap section, click the Submit sitemap button, enter your sitemap URL, and push Submit.

The URL Inspection tool in Google Search Console
We described how to add a sitemap with lots of website links. But if you need to add one or more links for indexing, you can use another GCS option. With the URL Inspection tool, you can request a crawl of individual URLs.
Go to your Google Search Console dashboard, click on the URL inspection section, and enter the desired page address in the line:

If a page has been created recently or is experiencing technical issues, it may not be indexed. When this happens, you will receive a message indicating the issue, and you can request indexing of the URL. Simply press the button to start the indexing process:

All URLs with new or updated content can be requested for indexing in the search engine this way through GSC.
Google’s Indexing API
With the Indexing API, you can notify Google of new URLs that need to be crawled.
According to Google, this method serves as an excellent alternative to using a sitemap. By leveraging the Indexing API, Googlebot can promptly crawl your pages without waiting for sitemap updates or pinging Google. However, Google still recommends submitting a sitemap to cover your entire website.
To use the Indexing API, create a project for your client and service account, verify ownership in Search Console, and get an access token. This documentation provides a step-by-step guide on how to do it.
Once set up, you can send requests with the relevant URLs to notify Google of new pages, and then patiently wait until your website’s pages and content are crawled.
Note: The Indexing API is especially useful for websites that frequently host short-lived pages, such as job postings or livestream videos. By enabling individual updates to be pushed, the Indexing API ensures that the content remains fresh and up-to-date in search results.
Submitting URLs in Bing Webmaster Tools
This website indexing tool is similar to Google Console’s URL Inspection tool. It allows you to submit up to 10,000 daily URLs for immediate crawls and indexation.
Click Submit URLs, add one URL per line, and push Submit.

The URLs are immediately evaluated for search indexing. They will also appear in Bing search results if they meet quality standards. This is great for getting important content indexed fast.
Bing’s IndexNow
Bing’s IndexNow is a ping protocol that allows you to instantly notify the search engine about new content changes or updates. You can send up to 10,000 URLs to bypass Bing’s crawlers.
IndexNow is integrated into Wix, Duda, and xenForo. If you are using another CMS, you must install a plugin. Also, you must install your API key file at your website’s root if it is not supported by any of the listed systems. Then, you must also submit the corresponding URLs to Bing by specifying each on a new line.
Find all the instructions here.
This will allow the search engine to crawl and index (or re-index) those specific pages faster, thereby expediting the appearance of these new changes in search results.
All submitted URL data will be displayed in the IndexNow section of Bing Webmaster Tools.

Internal linking
Implementing a thoughtful internal linking strategy across your website architecture provides clear paths for crawlers to discover and index your pages.
When a search engine crawler lands on your website, internal links act as routes guiding the crawler to discover new pages. A well-structured internal linking (i.e., website structure) system makes it easier for crawlers to find and crawl all the pages on your site.
Without internal links from your core pages, search crawlers may struggle to find and index pages that are several clicks away from the homepage or without links leading to them.
Consider the following when optimizing a website’s internal linking structure:
- Confirm that all links on your pages bring value to users and work properly.
- Provide descriptive and relevant anchor texts for the pages they lead to.
- Double-check your page content for 404 links and update them with the correct ones.
External links
Backlinks are integral to how search engines determine a page’s importance. They signal to Google that the resource is useful and worth ranking at the top of the SERP.
John Mueller said, “Backlinks are the best way to get Google to index content.” He asserts that submitting a sitemap with URLs to GSC is good practice. For new websites with no existing signals or information available to Google, providing the search engine with URLs via a sitemap is a good way to get started. Still, it’s important to note that this does not guarantee Google will index the included URLs.
John Mueller also advises webmasters to cooperate with different blogs and resources to get links pointing to their websites. This method is far more effective and ethical than going to Search Console and saying I want this URL indexed immediately.
Here are some ways to get quality backlinks:
- Guest posting
- Creating press releases
- Writing testimonials
- Utilizing the other popular backlink acquisition strategies in this article
Social signals
Search engines aim to deliver high-quality content that matches users’ search intent. Google achieves this by evaluating social signals, including likes, shares, and social media post views.
These signals inform search engines whether the content meets users’ needs and is relevant and authoritative. Search bots won’t pass by your content if users actively share your page, like it, and recommend it for reading. This highlights the importance of being active on social media. Also, Google says that social signals are not a direct ranking factor but can indirectly help with SEO.
Social signals include all activity on Facebook, Twitter, Pinterest, LinkedIn, YouTube, etc. With Facebook, you can create a post for your important links. On YouTube, you can add a link to the video description. You can also use LinkedIn to raise the credibility of your website and company. Understanding how to use each platform you’re targeting helps you adjust your approach to maximize your website’s effectiveness.
As a rule of thumb, the more social buzz you create around your website, the faster it will get indexed.
How do you check your website’s indexing?
You have submitted your website pages for indexing. How do you know that the indexing was successful and that the necessary pages have already been ranked? Let’s look at some methods you can use to check this.
Analyze Indexing reports in GSC
Google Search Console allows you to monitor which of your website pages are indexed, which are not, and why. We’ll show you how to check this.
Begin by clicking on the Indexing section and going to the Pages report.

On the Indexed tab, you’ll find information about all pages on the site that have been indexed. Click on the View data about indexed pages button.
You’ll see all submitted in the sitemap and indexed pages under the All submitted pages row.

Scroll down to see the list of all indexed pages. From here, you can even find out when Google last crawled the page.

Next, choose the Unsubmitted pages only option from the drop-down menu. You’ll see indexed pages that were not submitted in the sitemap. You may want to add them to your sitemap because Google considers them to be high-quality pages.

Now, let’s move on to the next stage.
The Not Indexed tab shows pages that could not be indexed due to various reasons, such as indexing errors.

In the Why pages aren’t indexed table, you can find specific details about each issue and try to fix it.
Look through all these pages carefully because you may find URLs that can be fixed. This will ensure that Google indexes them, leading to improved rankings. Use the Google website rank checker to see if your efforts worked and if your rankings improved.

Scroll down to the tab showing the pages that have been indexed, but there are some issues that can be intentional on your part. Click on the warning row in the table to see details about the issue and then try to fix it using this new info. This will help you rank better.

The same type of indexing data can also be obtained for videos. Simply go to the Video pages report within the Indexing section.

Use the “site:” search operator
Another popular way to check website indexing is through the site: command. This Google search operator displays the website’s page list. However, there is no guarantee that Google will provide the full list.
Most SEO specialists use it because it’s the easiest way to check websites or pages for indexation. This is especially useful after Google’s March 2024 core update, seeing that many sites with AI content were deindexed.
Type this command in the Google search bar and enter the website’s domain name.
site:yourdomain.com

You’ll see website pages currently being displayed in Google’s SERP. The URL list returned, however, is not always broad. Larger sites shouldn’t expect to see all of their URLs in the results.
You can also verify the indexing status of individual URLs. Just enter site:yourpage.com into the search engine.

If the URL doesn’t show in a site: query, you can use the URL Inspection tool to see if the URL is indexed.
Use SE Ranking’s tools
Using SE Ranking, you can run a website SEO audit and find information about indexing.
Go to the Overview and scroll to the Page Indexability block.

Here, you’ll see the number and percentage ratio of indexed and not indexed pages. This dashboard also shows issues that won’t let search engines index pages of the website.
By clicking on the green line, you’ll see the list of indexed pages and their parameters: issues, total traffic, status code, blocked by robots.txt, referring pages, x-robots-tag, title, description, etc.
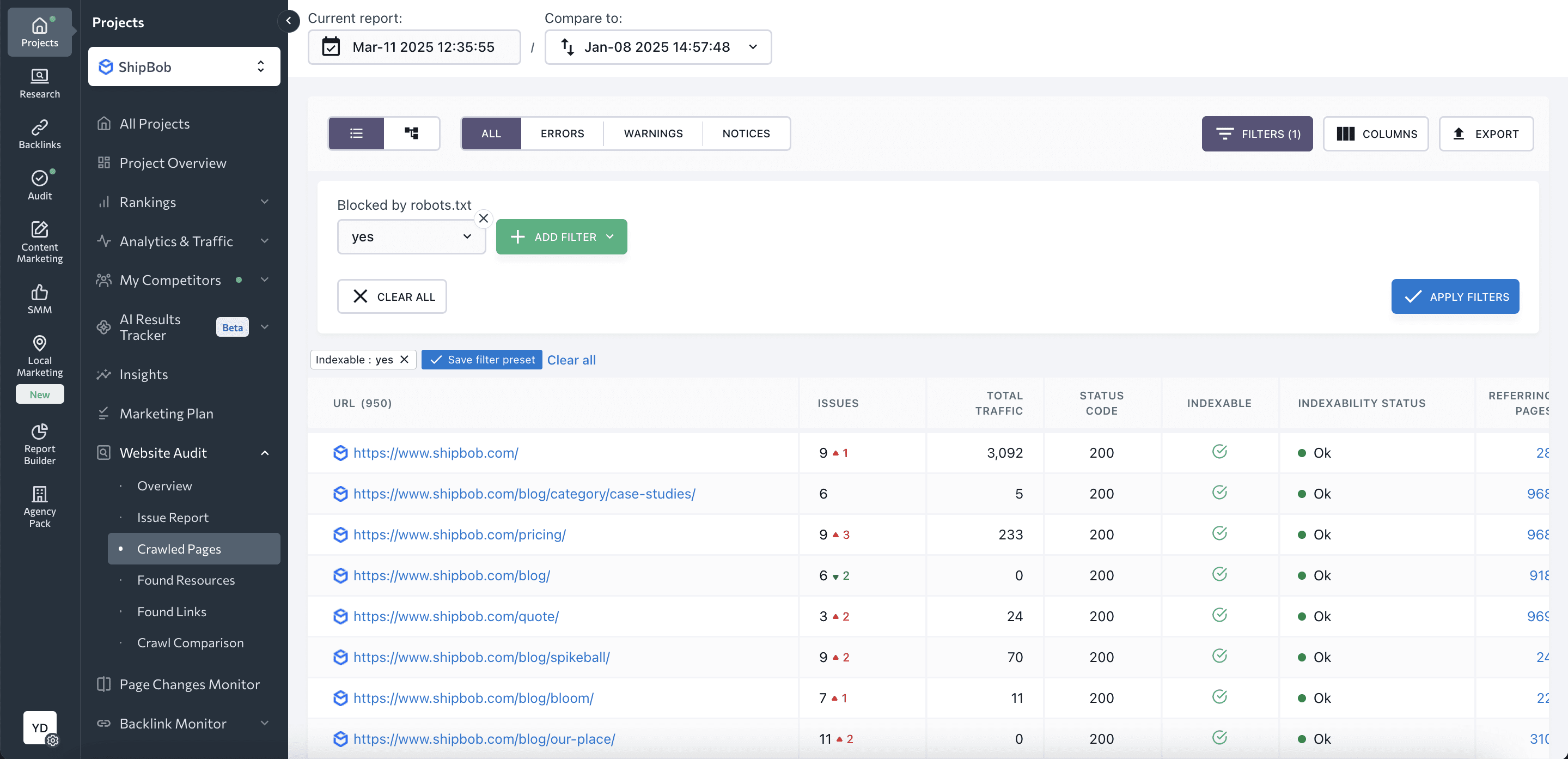
You can also check page indexing with SE Ranking’s Index Status Checker. Just choose the search engine and enter a URL list.

Once you’ve resolved any indexing issues, you can use a rank checker to monitor your website’s performance and track the improvements.
You can also check out an extended hand-picked list of the best rank tracker software.
Check out our guide on tracking search engine rankings to learn effective techniques for analyzing your website’s performance on search engines and optimizing your SEO strategy accordingly.
How different technologies affect website indexing
Now that we’ve puzzled out how Google and Bing index websites, how to submit pages for indexing, and how to check whether they appear in SERPs, let’s move on to an equally important issue: how web development technology affects website content indexing.
Flash content
Flash was once used to make both games and full-blown websites, but Flash is no longer active. Over its 20-year development, Flash has had many shortcomings, including a high CPU load, flash player errors, and indexing issues.
In 2019, Google stopped indexing flash content, making a statement about the end of an era.
Not surprisingly, search engines recommend not using Flash on websites. But if your site is designed with this technology, create a text version of the site. This will be useful for users who haven’t installed Flash (or installed outdated Flash programs) and mobile device users (these devices do not display Flash content).
JavaScript
Before JavaScript began dominating web development, search engines only crawled text-based content like HTML. As JS grew in popularity, search engines improved their ability to index this type of content.
However, JavaScript rendering is a resource-heavy process. There can be a delay in how search engines process JavaScript on web pages. Until rendering is complete, the search engine may struggle to access all JS content loaded on the client side. To reveal what is within the JavaScript, which normally looks like a single link to the JS file, bots need to render it first. Only after this step can the search engine see all the content in HTML tags and scan it fast.
Google is getting faster at indexing JavaScript-rendered content. 60% of JavaScript content is indexed within 24 hours of HTML indexing. However, that still leaves the remaining 40% of JS content, which can take longer.
Note that page sections injected with JavaScript may contain internal links. And if the search engine fails to render JavaScript, it can’t follow the links. This means search engines can’t index those pages unless they are linked to other pages or included in the sitemap.
If you have a JavaScript-heavy site, try restructuring the JavaScript calls so that the content loads first, and then see if doing so improves web indexing. Read our comprehensive guide for more tips about improving JS website indexing.
AJAX
AJAX enables pages to update serially by exchanging a small amount of data with the server. One of the signature features of websites using AJAX is that content is loaded by a single continuous script, without dividing it into separate pages with unique URLs. As a result, the website’s pages often have a hashtag (#) in the URL.
Pages like these have historically not been indexed by search engines. Instead of scanning the https://mywebsite.com/#example URL, the crawler would go to https://mywebsite.com/ and not scan the URL with #. As a result, crawlers could not scan all of the website’s content.
From 2019 onward, websites with AJAX have been rendered, crawled, and indexed directly by Google. This means that bots can scan and process #! URLs, mimicking user behavior. Now, webmasters no longer need to create the HTML version of every page, but you should still check if your robots.txt allows for AJAX script scanning. If they are disallowed, just open them for search indexing.
SPA
Single-page applications (SPAs) are a relatively new trend that incorporates JavaScript into websites. Unlike traditional websites that load HTML, CSS, and JS by requesting each from the server when needed, SPAs only require a single initial load. Since they don’t engage with the server beyond that pointt, all further processing is left to the browser. However, while SPA websites load faster, the technology behind them can hurt your SEO.
While scanning SPAs, crawlers fail to recognize that the content is being loaded dynamically. Search engines will then see it as an empty page yet to be filled.
SPAs also don’t follow the traditional logic behind the 404 error page and other non-200 server status codes. While rendering content by the browser, the server returns a 200 HTTP status code to each request. Search engines therefore can’t tell whether certain pages are (or aren’t) valid for indexing.
To learn how to optimize single-page applications, read our blog post about SPA.
Frameworks
JavaScript frameworks are used to promote dynamic website interactions. Websites built with React, Angular, Vue, and other JavaScript frameworks are all set to client-side rendering by default. This often results in frameworks riddled with the following SEO challenges:
- Crawlers can’t see what’s on the page. Search engines have trouble indexing content that requires you to click it to load.
- Speed is a major hurdle. Google crawls pages un-cached. First loads can be cumbrsome and problematic.
- Client-side code adds increased complexity to the finalized DOM. It requires more CPU resources from both search engine crawlers and client devices.
How to restrict site indexing
There may be certain pages that you don’t want search engines to index. It is not necessary for all pages to rank and appear in search results.
What content is most often restricted?
- Internal and service files: those that should be seen only by the site administrator or webmaster, for example, a folder with user data specified during registration: /wp-login.php; /wp-register.php.
- Pages that are not suitable for display in search results or for the first acquaintance of the user with the resource: thank you pages, registration forms, etc.
- Pages with personal information: contact information that visitors leave during orders and registration, as well as payment card numbers;
- Files of a certain type, such as pdf documents.
- Duplicate content: for example, a page you’re doing an A/B test for.
So, you can block information that has no value to the user and does not affect the site’s ranking, as well as confidential data from being indexed.
You can solve two problems with it:
- Reduce the likelihood of certain pages being crawled, including indexing and appearing in search results.
- Save crawling budget—a limited number of URLs per site that a robot can crawl.
Let’s see how you can restrict website content.
Robots meta tag
Meta robots is a tag where commands for search bots are added. They affect the indexing of the page and the display of its elements in search results. The tag is placed in the <head> of the web document to instruct the robot before it starts crawling the page.

Meta robot is a more reliable way to manage indexing, unlike robots.txt, which works only as a recommendation for the crawler. With the help of a meta robot, you can specify commands (directives) for the robot directly in the page code. It should be added to all pages that should not be indexed.
Read our ultimate guide to find out how to add meta tag robots to your website.
X-Robots-Tag
Since not all pages have the HTML format and <head> section (e.g., PDF documents), some content can’t be blocked from indexing with the robots meta tag. This is when X-Robots Tag comes in handy.
The X-Robots-Tag is used as an element of the HTTP header response for a given URL. When instructing crawlers not to index a page, your HTTP response with an X-Robots-Tag will look like this:

This is where you would need to use a noindex rule, similar to a robots meta tag. Refer to this Google guide for more information.
Server-side
You can also restrict the indexing of website content server-side. To do this, find the .htaccess file in the root directory of your website and add the necessary code to restrict access for specific search engines.
This rule allows you to block unwanted User Agents that may pose a potential threat or simply overload the server with excessive requests.
Set up a website access password
Another method to prevent site indexing is by setting up a website access password through the .htaccess file. Set a password and add the code to the .htaccess file.
The password must be set by the website owner, so you will need to identify yourself by adding a username. This means you will need to include the user in the password file.
This will result in the bot will no longer being able to crawl the website and index it.
Removals tool in Google Search Console
You can also use the Removals tool to block your site’s URLs from appearing in Google Search results. However, it only temporarily removes pages from Google search results (for six months) and does not affect their presence on other search engines.
To clean up unnecessary content with this tool, go to Google Search Console ▶️ go to the Removals tool ▶️ click the New request button ▶️ and submit pages.

Note: When trying to block pages from indexation, do not rely on the robots.txt file, as it only instructs bots not to crawl those pages. This file doesn’t guarantee that your pages won’t appear in search results. For example, if the pages were already crawled previously, they may still appear in SERPs.
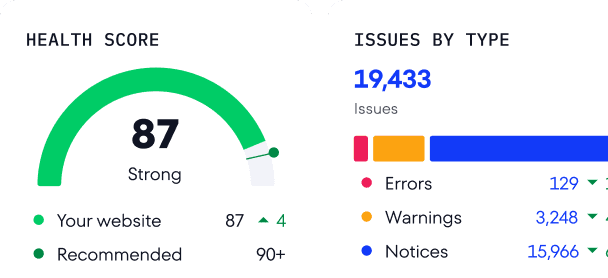
Conclusion
While it’s essential to get your site crawled and indexed, it can take a long time before your pages appear in the SERP. Knowing the ins and outs of search engine indexing can help you in avoiding detrimental mistakes that can harm your website’s SEO.
Set up your sitemap correctly by optimizing your internal linking and creating only high-quality, useful content. This will prevent the search engine from overlooking your website.
Now, let’s do a quick recap of the search engine indexing aspects we covered:
- Notifying the search engine of a new website or page by creating a sitemap, using features in GSC and Bing Webmaster Tools, and leveraging internal and external links.
- The specifics of indexing websites that use Ajax, JavaScript, SPA, and frameworks.
- Restricting site indexing with the help of the robots meta tag, X-Robots-Tag, the Removals tool, and access password.
Note that while a high indexing rate does not equal high search engine rankings, it’s the basis for further website optimization. Before taking further steps, check your pages’ indexing status to verify their indexability.

