Understanding JavaScript SEO
If you’re an SEO specialist, and not a developer, then you probably don’t need to tap into all of the intricacies of website development. But you do need to know the basics, since the way a website is coded has a great impact on its performance and therefore SEO potential. In the post on HTML tags, we’ve gone through the HTML basics you need to understand to efficiently do website SEO. This time we offer you to dig into other coding languages developers use to make a website look good and make it interactive.
The language is JavaScript, and in this JavaScript SEO guide, we’ll go through the major JS-related errors you can face when auditing your website. We’ll explain why each of the errors matters and how they can be fixed. The fixing part is something you’ll probably assign to your website developers. It’s just that this time you’ll be speaking with them the same language.
What Is JavaScript SEO?
Before delving into JavaScript SEO and its significance for a successful website performance, let’s first identify the essence of JavaScript itself.
JavaScript is a scripting language that is primarily used to add interactive elements and dynamic content to websites. It was created by Brendan Eich at Netscape Communications in 1995 and has since become one of the most widely used programming languages on the web. Many JavaScript frameworks have also been developed since then. Pop-up forms, interactive maps, animated graphics, websites with continually updated content (e.g. weather forecast, exchange rates) are all examples of implementing JavaScript.
As of March 2025, Javascript is the most widely used client-side programming language, followed by Flash and Java. Some of the most popular JavaScript websites are Google, Facebook, Microsoft, Youtube, and so on.
Learn how to optimize single page apps that heavily rely on JavaScript.
Here at SE Ranking, we use JavaScript as well. Many of the cool effects you see on the SE Ranking platform are also powered by JS. For example, our Page Changes Monitoring landing page now features a JavaScript-powered animation designed to explain how the tool works.
Just to give you a better feel of how JavaScript transforms websites, let me show you the same section of the landing page with JavaScript disabled.
Now that you’re familiar with JavaScript and the role it plays in website development, let’s shift our focus to JavaScript SEO.
JavaScript SEO involves optimizing websites that significantly rely on JavaScript technology. In the past, search engines struggled to properly index and crawl JavaScript sites and pages, as their algorithms focused mostly on parsing and understanding static HTML content. Search engines have made tremendous progress in their ability to interpret and index JavaScript content. Nevertheless, to address the challenges posed by JavaScript and improve your site’s search engine visibility, it’s essential to implement JavaScript SEO best practices.
- If not implemented properly, JavaScript can lead to a part of your content not getting indexed. Google and other search engines need to render JS files to see your page the way users do, and if they fail to do so, they will index your page without the JS-powered elements. This, in turn, can impede your rankings if non-indexed content is crucial for fulfilling user intent;
- Page sections injected with JavaScript may contain internal links. Again, if Google fails at JavaScript rendering it will not follow the links. So whole pages may not get indexed unless they are linked to from other pages or the sitemap. Then, with JavaScript there’s a chance you’ll code your links in a way Googlebot can’t understand, and as a result, it won’t follow the links.
- JavaScript files are rather heavy and adding them to a page can significantly slow down its loading speed. In turn, this can lead to higher bounce rates and lower rankings search engines.
Surely, all these issues can be avoided as long as you understand Google’s JavaScript rendering and how to make your JS code search-friendly.
Is JavaScript good or bad for SEO?
Unfortunately, there is no simple answer to this question. It all depends, really!
When Javascript is implemented thoughtfully, with a focus on page experience, performance optimization, and proper indexing techniques, it can be beneficial for both SEO and users. Most worthy of note is that it can result in improved user experience. JavaScript sites tend to have different types of animations and transitions that are great for increasing user engagement.
Now, if you can’t find a balance between interactivity and search engine friendliness, your website has a higher chance of suffering from issues like limited crawlability, long page load time, and compatibility issues. All of these issues combined can lead to a high bounce rate. We don’t want that either!
And despite the ongoing debate regarding the impact of JavaScript on a website’s visibility and rankings, it wouldn’t be accurate to say that Javascript or JavaScript frameworks are threats to website optimization. Still, using them incorrectly can have a detrimental effect on your ranking potential, so it’s recommended to at least follow some Javascript SEO best practices. We will cover those later on. So don’t worry, you’ll soon be able to harness the power of this scripting language to its fullest.
How Google handles JavaScript
Lately, Google has leaped a hundredfold in JavaScript crawling and indexing. But the process is still rather complicated, and many things can go wrong.
With regular HTML pages, it is all plain and simple. Googlebot crawls a page and parses its content, including internal links. Then the content gets indexed while the discovered URLs are added to the crawl queue, and the process starts all over again. Every time Google crawls your website like this, you sort of spend one point from your crawl budget. Each website has an assigned crawl budget because Google has limited resources for crawling and rendering website pages.
With JavaScript sites, the process gets a bit more cumbersome. To see what’s hidden within the JavaScript that normally looks like a single link to the JS file, Googlebot needs to first parse, compile, and execute it. This is called JavaScript rendering and only after this stage is complete Googlebot can see all the content of a page in HTML tags—the language it can understand. At this point, Google can proceed with indexing the JS-powered elements and adding the URLs hidden within JS to the crawl queue.
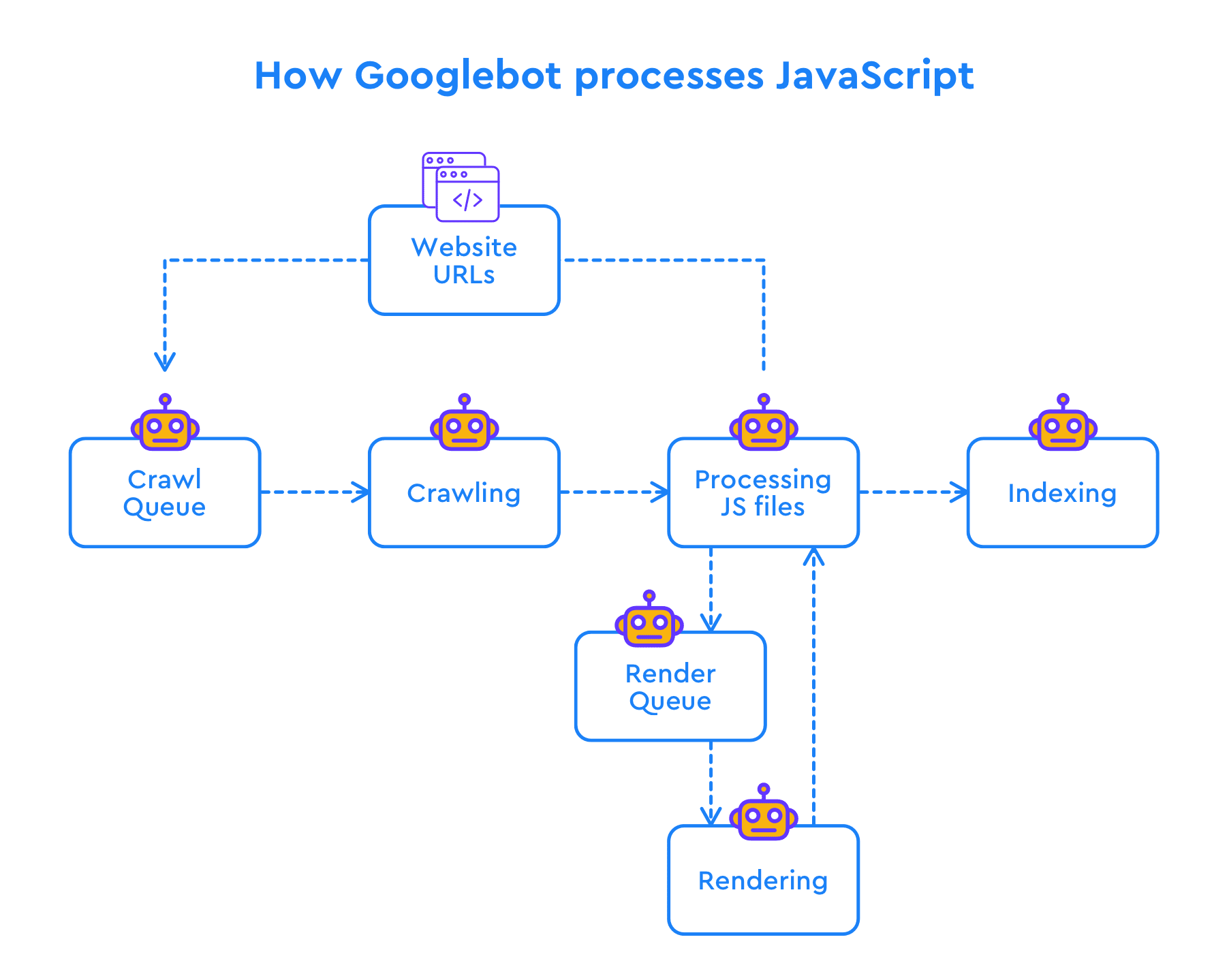
Now, are these complications something you should worry about SEO-wise? Just one year ago they were.
JavaScript rendering is very resource-demanding and costly, and until recently Google wouldn’t immediately render JavaScript. It would first index the readily-available plain HTML parts of the page and then during the so-called second wave of indexing Googlebot would get the JavaScript processed. Back in 2018, John Mueller claimed that it took a few days to a few weeks for the page to get rendered. Therefore, JavaScript sites could not expect to have their pages indexed fast. Besides, they could have issues with new pages making their way into the crawl queue because Googlebot couldn’t follow internal links immediately.
In one of the JavaScript SEO office hours, Martin Splitt reassured webmasters that the rendering queue is now moving way faster and a page is normally rendered within minutes or even seconds. Nevertheless, making JavaScript code search-friendly is still rather tricky, and weekly JavaScript SEO office hours sessions evidently prove this. The cases users share demonstrate that things can go terribly wrong if JavaScript is not coded properly. Let us illustrate our point with a few common issues.
Google Doesn’t Interact With Your Content
Google can see and index hidden content as long as it appears in the DOM—this is where the source HTML code is sent before it gets rendered by the browser. At this stage, JavaScript can be used to modify the content.
Now, let’s say your initial HTML contains the page’s content in full and then you use CSS properties to hide some parts of the content and JS to let users reveal these hidden parts. In this case, you’re all good as the content is still there within the HTML code and only hidden for users—Google can still see what’s hidden.
If, on the other hand, your initial HTML does not contain some content pieces, and they get loaded into the DOM by click-triggered JavaScript, Google won’t see this kind of content because Googlebot can’t click. This problem may be solved, however, by implementing server-side rendering—this is when JS is executed on the server-side and Google gets the ready-made final HTML code. Dynamic rendering can also be a way out.
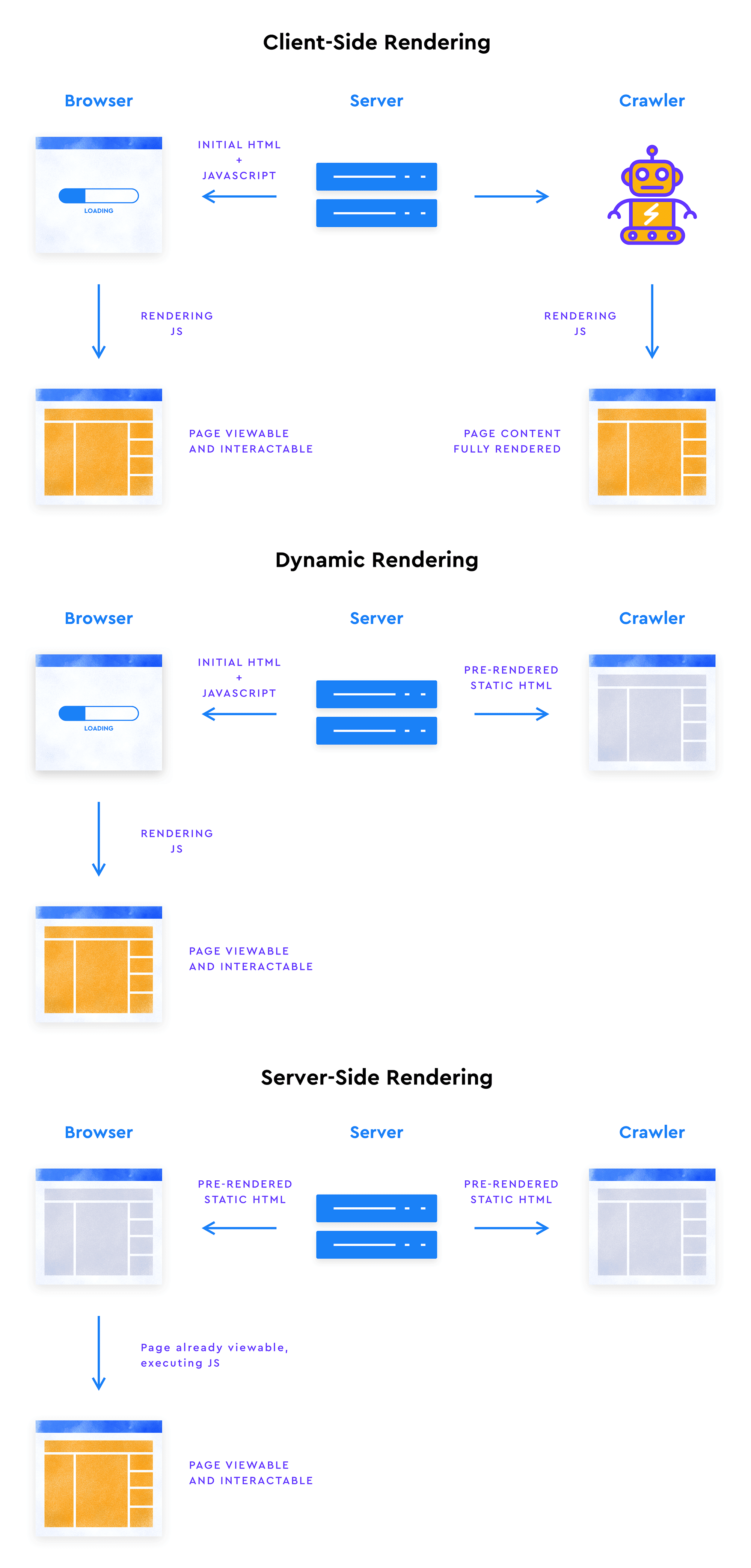
Google Doesn’t Scroll
JavaScript is often used to implement an infinite scroll or to hide some content for the UX sake and let users reveal additional info upon clicking the button.
The problem here is that Googlebot doesn’t click or scroll the way users do in their browsers.
Google surely has its own workarounds, but they may work or not depending on the technology you use. And if you implement things in a way Google can’t figure out, you’ll end up with a part of your JS-powered content not getting indexed.
For infinite scroll, overscrolls events are to be avoided as they require Googlebot to actually scroll the page to call the JavaScript code—something Google cannot handle. Instead, you can implement infinite scroll and lazy loading using Intersection Observer API or enable paginated loading alongside infinite scroll.
How JS and CSS work together
While Javascript is mainly used to add interactivity and dynamic behavior to web pages, CSS (which stands for Cascading Style Sheets) makes it possible to create websites in style. It allows developers to define the layout, colors, fonts, and other visual aspects of the site’s HTML elements. A plain HTML web page would look like this minus the set width and left-side alignment.

In the past, Google only interpreted the HTML markup of the page. This all changed with the mobile-friendly update back in 2015 when Google decided to reward websites with mobile-friendly pages that offered a seamless user experience on mobile devices. This change also impacted Google’s Page Layout Algorithm, which assesses content accessibility on both desktop and mobile. CSS played a key role in both cases.
Now, to understand how CSS and Javascript work together, let’s use a simple analogy. Imagine you’re planning an impressive party. In this case, the former will play the role of a party decorator, making everything visually appealing, while the latter is akin to a party planner, managing interactive elements and ensuring everything runs smoothly. Both enhance web development, similar to how they improve a party experience.
JavaScript SEO Best Practices
Since we’ve gone over most of the fundamentals of JavaScript, let’s move on to some best practices to follow when optimizing JavaScript sites.
Ensure Google can discover all your content
Since Google’s web crawler, Googlebot, is currently able to analyze JavaScript, there’s no need to block its access to any resources necessary for crawling and rendering, even for the sake of preserving the crawl budget.
Still, if you want to ensure the content on JavaScript sites is effectively indexed, adhere to the following guidelines:
- Make essential information within your web pages visible in the page source code. This ensures that Google and other search engines don’t need to depend on user interactions to load content (e.g., clicking a button).
- Even though Google doesn’t recommend it, you can still use JavaScript to inject a rel=”canonical” link tag. Google Search will recognize the link tag when it loads your page. Just make sure it’s the only one on the page. If it isn’t, you may end up creating multiple rel=”canonical” link tags or changing an existing rel=”canonical” link tag, which can lead to some unexpected consequences.
- Javascript frameworks, such as Angular and Vue, commonly generate hash-based URLs (e.g., www.example.com/#/about-us) for client-side routing. Although these kinds of URLs offer seamless navigation, they can hinder SEO and confuse users. Make sure to use regular URLs to improve user experience, SEO, and overall website visibility.
Follow on-page best practices
When it comes to Javascript SEO, following common on-page SEO guidelines should be on your priority list. It’s especially important to optimize content, title tags, meta descriptions, alt attributes, and meta robot tags. Some key JavaScript and SEO best practices include but are not limited to:
- Content Optimization: Ensure your JS content is valuable and keyword-optimized. Use proper heading tags and include relevant keywords.
- Title Tags and Meta Descriptions: Generate unique and descriptive title tags and meta descriptions for each page using JavaScript. Pay special attention to this if you use JavaScript frameworks, as many of them are based on templates and you can easily find yourself in a situation where the same title or meta description is used for different pages. Include keywords within the character limits.
- Alt Attributes for Images: Add concise, keyword-rich alt attributes to your JavaScript-based images for improved accessibility and SEO.
- Meta Robot Tags: Include meta robot tags to guide search engines on indexing and following links. Choose “index” and “follow” for desired content or use “noindex” and “nofollow” for sensitive or duplicate content.
- JavaScript Loading and Performance: Optimize JavaScript loading to improve page speed and user experience. Compress file size to reduce loading time, leverage caching, and avoid blocking critical page elements.
Use proper <a href> links
What you need to remember when implementing JS is that Google and other search engines will only follow JavaScript links if they are coded properly. An HTML <a> tag with a URL and a href attribute pointing to the proper URL is the golden rule you need to follow. As long as the tag is there, you’re all good even if you add some JS to the link code.
<a href=”/page” onclick=”goTo(‘page’)”>your anchor text</a>
Meanwhile, all other variations like links with a missing <a> tag or href attribute or without a proper URL will work for users but Google won’t be able to follow them.
<a onclick=”goTo(‘page’)”>your anchor text</a> <span onclick=”goTo(‘page’)”>your anchor text</span> <a href=”javascript:goTo(‘page’)”>your anchor text</a> <a href=”#”>no link</a>
Surely, if you use a sitemap, Google should still discover your website pages even if it can’t follow internal links leading to these pages. However, the search engine still prefers links to a sitemap as they help it understand your website structure and the way pages are related to each other. Besides, internal linking allows you to spread link juice across your website. Check out this in-depth guide on internal linking to learn how it works.
Use meaningful HTTP status codes
Ensuring that HTTP status codes are relevant and meaningful is an essential SEO practice that plays a crucial role in facilitating good communication with Googlebot. JavaScript can simplify this process. For example, if a 404 code or any other error is encountered, users will automatically be directed to a separate/not-found page. By utilizing JavaScript to manage HTTP status codes, websites can provide a more intuitive user experience, reducing frustration and assisting visitors in navigating through potential errors.
Avoid blocking important JavaScript files in your robots.txt file
Don’t block essential JS files in your website’s robots.txt file. If you do, Google as well as other search engines won’t be able to access, process, or even interact with your content. This can drastically hamper Google’s ability to understand and rank your website effectively.
Let’s say that you’ve generated high-quality JS content by incorporating dynamically loaded text, interactive elements, and crucial metadata. But let’s also say that you have blocked it from crawling by search engines for some reason. Because of this, your content may go unnoticed or be underrepresented in search engine indexes. This would then lead to reduced organic traffic, visibility, and overall search performance.
Implement pagination correctly
When SEO experts deal with a vast amount of website content, they tend to use on-page optimization techniques like pagination and infinite scrolling. Despite the fact that these practices can bring a variety of benefits, they can also hinder your SEO efforts when implemented improperly.
One common problem with pagination is that search engines tend to only view the first part of the paginated content, unintentionally hiding the pages that follow as a consequence. This means that some of the valuable content pieces you created may go unnoticed and unindexed.
To solve this problem, implement pagination with correct <a href> links, in addition to user actions. With the help of < a href> links, search engines can easily follow and crawl every paginated page, ensuring that all content is found and indexed.
Use server-side or static rendering
Web crawlers, as mentioned above, tend to have difficulty executing JavaScript. This is why search engines may occasionally ignore this type of content altogether. Page crawlers may simply refuse to wait for the dynamic content to be fully rendered before indexing the page.
To assist search engines in crawling and indexing, it’s recommended to use server-side rendering. This process involves rendering the web page on the server before sending it to the user’s browser. This practice ensures that the search engines receive fully populated web pages and, as a result, drastically reduces processing time and effort.
Testing JS for SEO
As you might have guessed, the way JavaScript is coded can make or break your website. For example, you can use Google’s tools such as the Mobile-Friendly Test to see how Google renders your pages.
Preferably, testing should be done at the early development stage when things can get fixed easier. Using Google’s Mobile-Friendly Test, you can catch every bug early on—just ask your developers to create a URL to their local host server using special tools (e.g. ngrok).
Now, let’s explore other ways which you can use to test Javascript for SEO.
Inspect in Chrome
To examine how search engines interpret your JavaScript, you can use Chrome browser’s developer tools. Open your website in Chrome, right-click on any element, and select “Inspect”. This will open the developer console, where you can view the page’s HTML structure and check if the desired JS content is visible. If the content is hidden or not rendered correctly, it may not be accessible to search engines.
Alternatively, you can press Command+Option+J (Mac) or Control+Shift+J (Windows, Linux, Chrome OS) to run the tool.
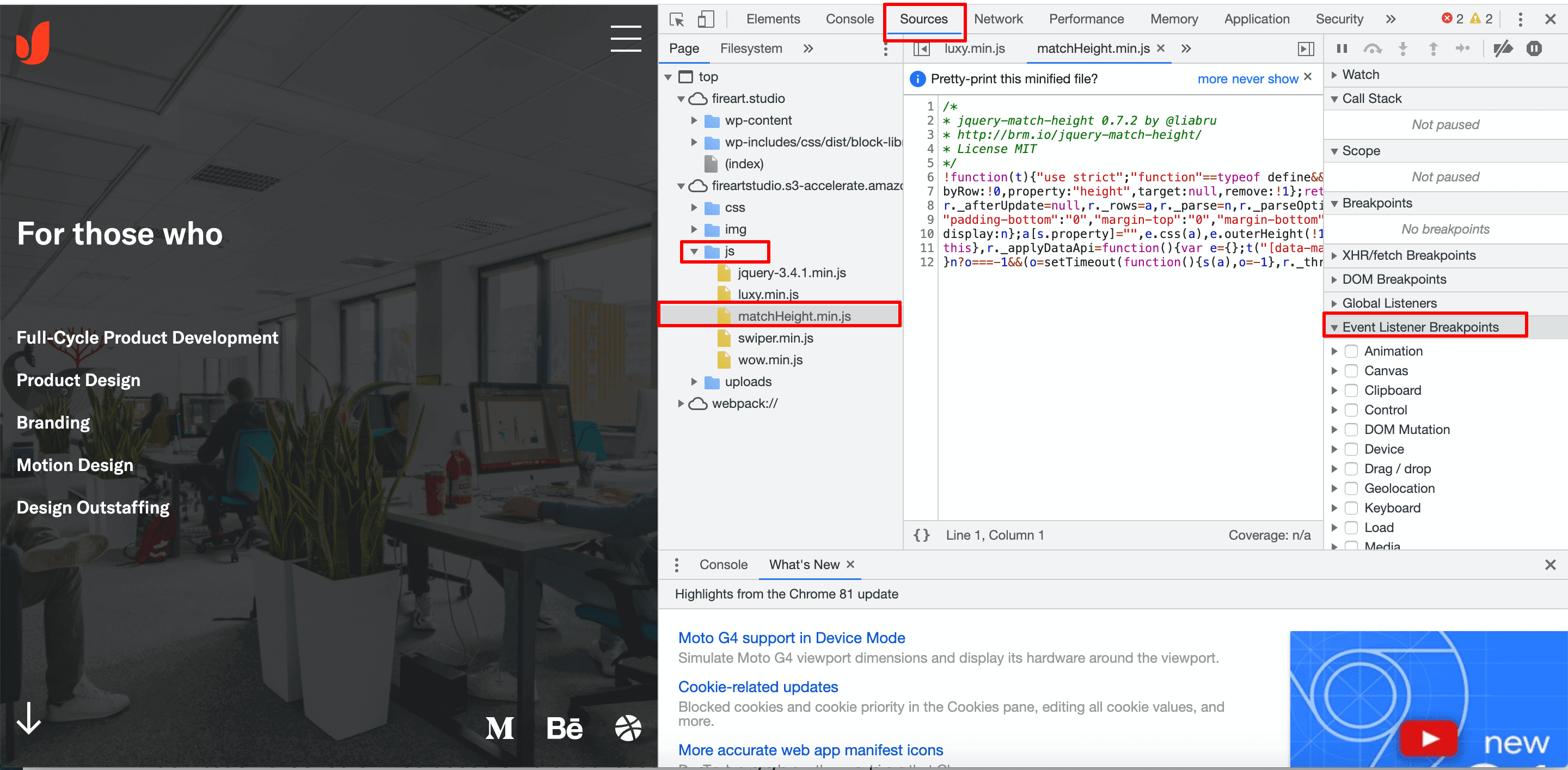
Here in the Sources tab, you can find your JS files and inspect the code they inject. Then you can pause JS execution at a point where you believe something went wrong using one of the Event Listener Breakpoints and further inspect the piece of code. Once you believe you’ve detected a bug, you can then edit the code live to see in real time if the solution you came up with fixes the issue.
The great thing about Chrome developers tools is that all the changes are applied in the user browsers and don’t affect other users. They’ll be gone once you hit the Refresh button. The tool can be used to debug any code error, not just those related to JavaScript. So, should you have any issues with your website’s CSS, the tool will come in handy as well.
Google Search Console
Google Search Console is a powerful tool that allows you to monitor and optimize your website’s presence in Google search results. It provides valuable insights into how Google crawls and indexes your site. For this, go to the “URL Inspection” section of Google Search Console. From here you can submit individual URLs and see how Google renders them, including any JS content. This will help you identify if Google is able to access and index your JavaScript content effectively.
Click on the “URL Inspection” and then use the “Test Live URL” feature. Then, click on View Tested Page > More Info > Javascript Console Messages.

Searching Text in Google
To determine if Google is indexing the content dynamically generated by your JavaScript code, perform a specific search for the unique string of text generated by the JavaScript. Now check if Google returns any relevant results. If your JavaScript-generated content is not appearing in the search results, this could indicate that Google is not indexing it properly.
Run a Site Audit
An easy way to test Javascript for SEO and discover all JS-related errors on your site is to launch a technical SEO audit. If you are an SE Ranking user, you’ll need to check several sections of the Website Audit’s Issue Report: JavaScript and HTTP Status Codes.
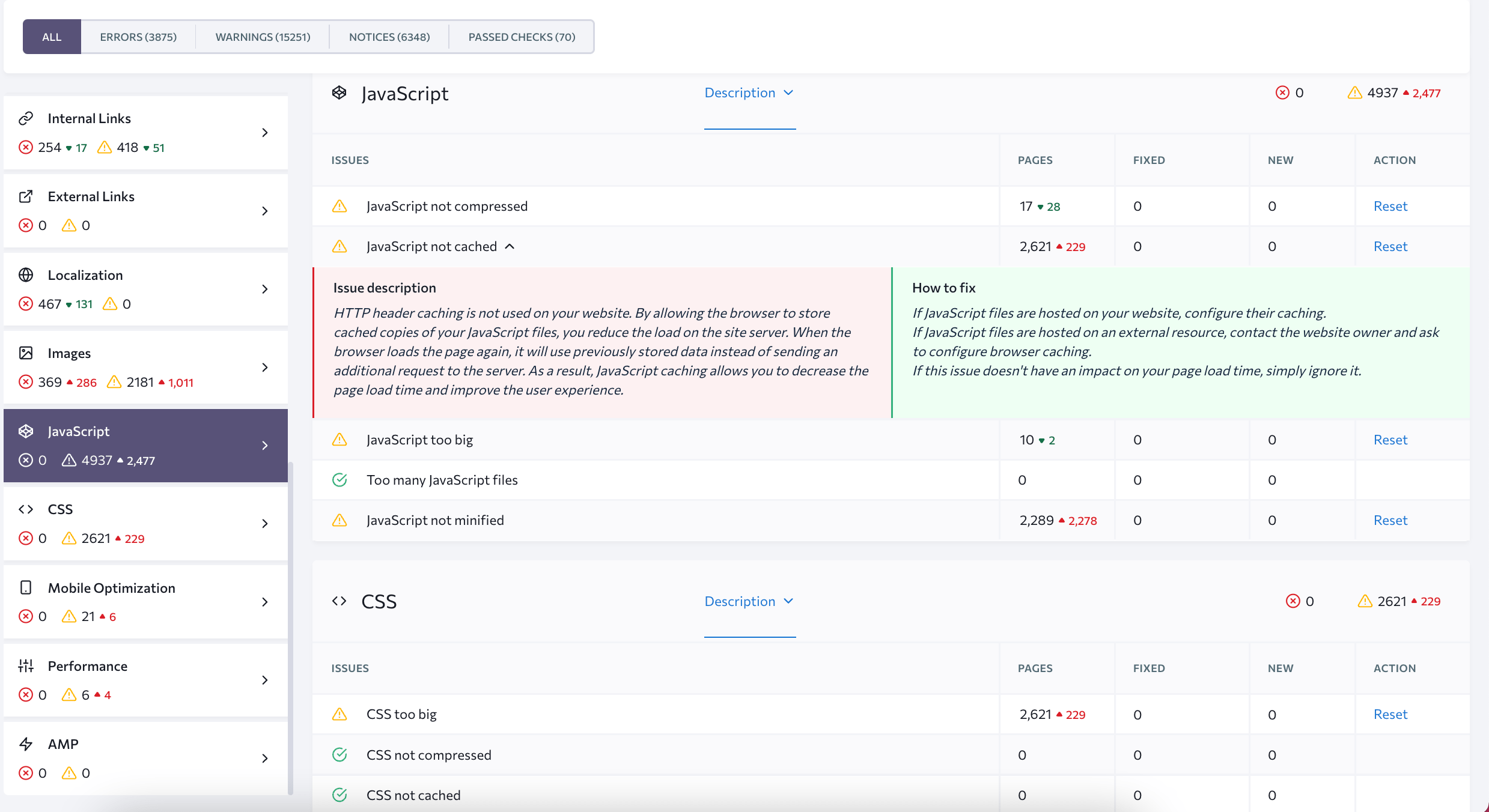
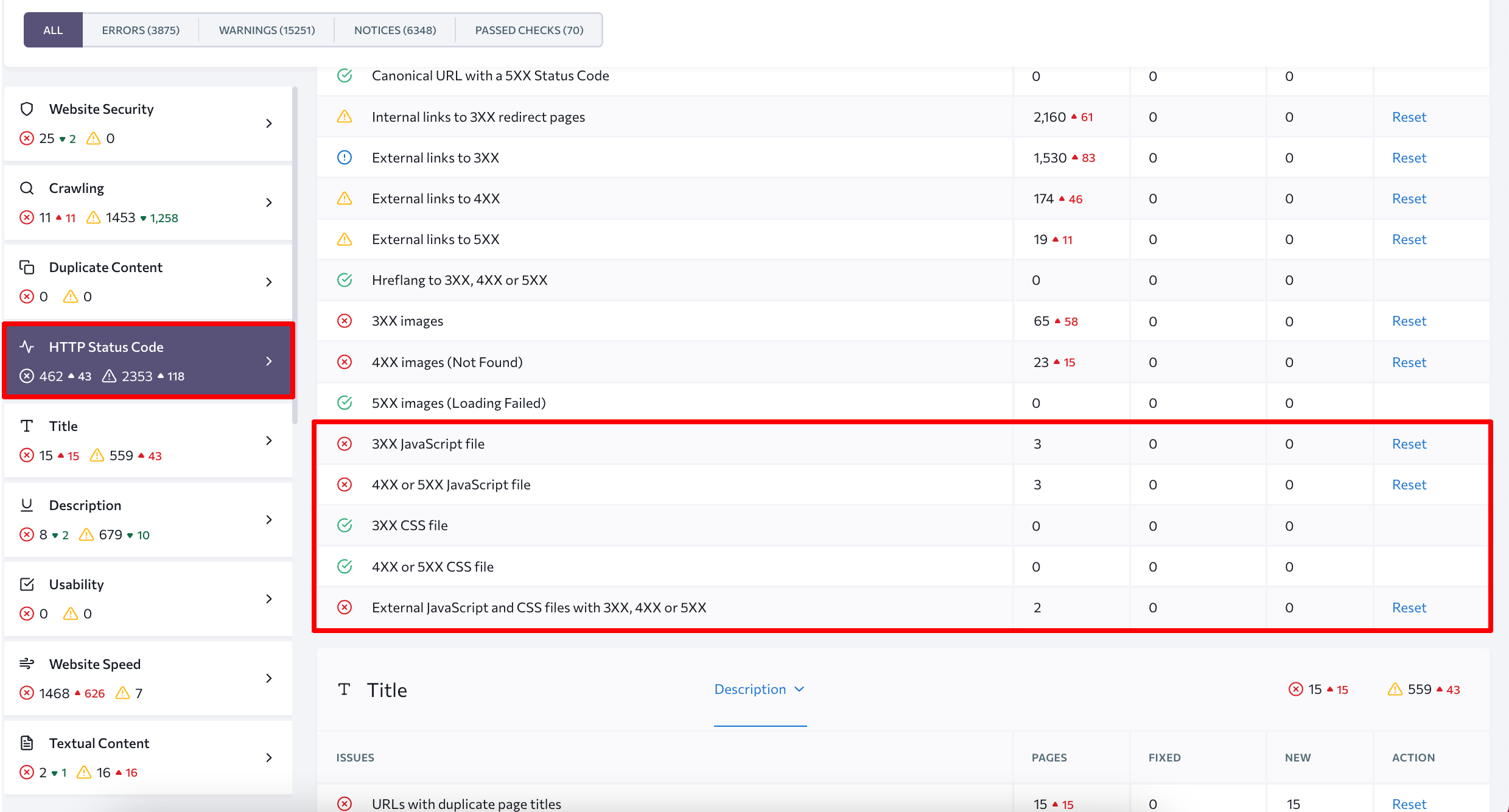
SE Ranking not only lists all the errors detected on your site but provides tips on how to fix them.
It points at the exact files that caused an error so that you know which files to adjust to make things right. A single click on the column with the number of pages, where the error occurs, opens a complete list of files’ URLs.
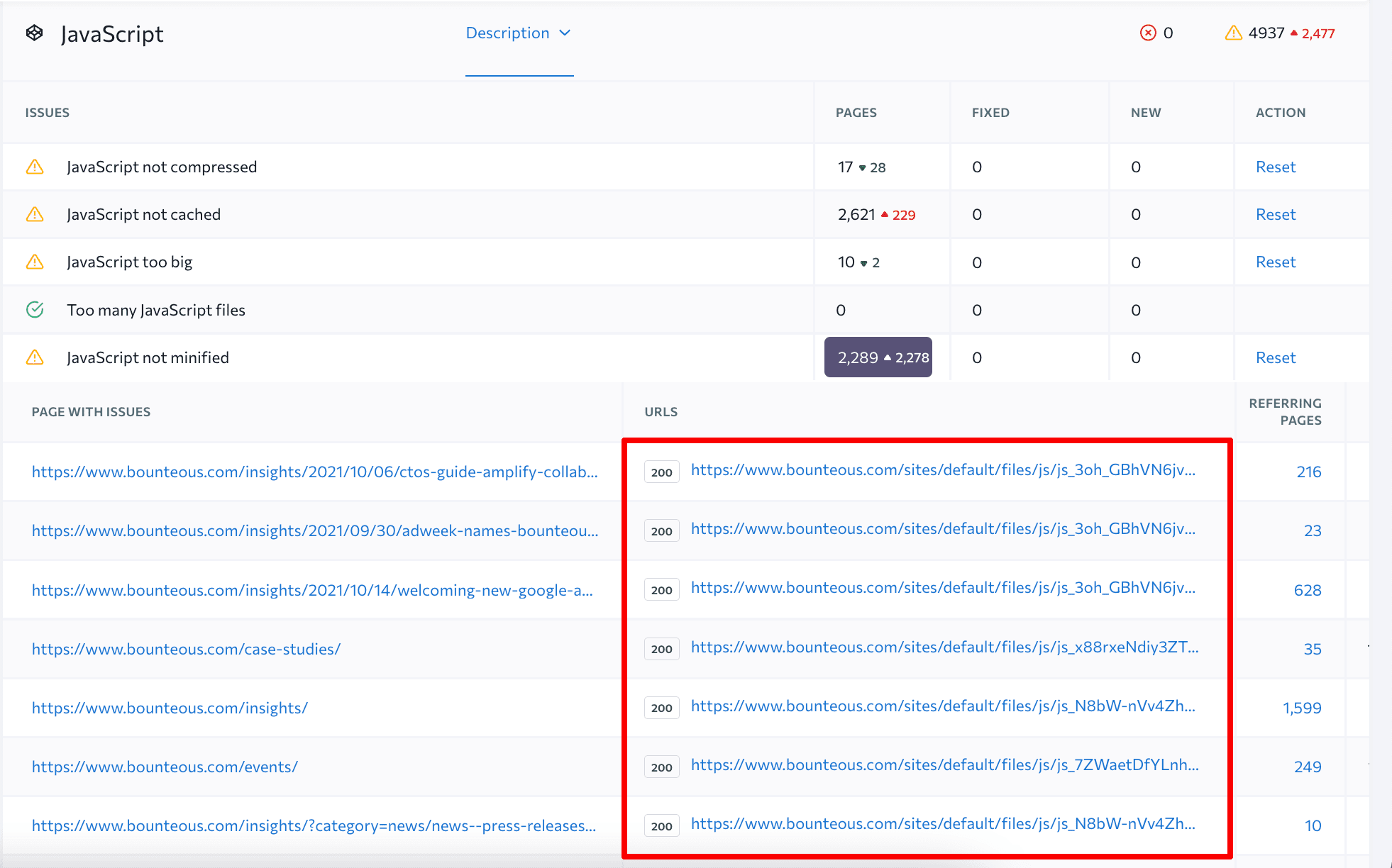
Read our article on how to do a website audit and prioritize fixes and test the tool on your own by launching a comprehensive website audit.
And if you’re up to studying every error type in greater detail, keep on reading.
Common JavaScript SEO Issues & How to Avoid Them
Now, you may be wondering which common SEO issues are associated with this programmatic language. And the first thing worth mentioning is that Javascript is stored separately as files and linked to the page from the <head> section.

Browsers and Google need to fetch these resources to fully render the content of the page. Sometimes, Google and browsers—or just Google—fail to load the files, and the reasons for this happening are common both for CSS and JavaScript.
In less drastic cases, Google and browsers can fetch the files, but they load too slowly, which negatively affects the user experience and can also slow down website indexing.
Google can’t crawl JS files
To fetch your JS files, Googlebot needs to have permission to do so. In the past, it was common practice to block Google from accessing these files with the robots.txt file since Google wouldn’t use them anyway. Now that the search giant relies on JavaScript to understand website content, it encourages webmasters to “allow all site assets that would significantly affect page rendering to be crawled: for example, CSS and JavaScript files that affect the understanding of the pages.” If you don’t unblock the files, Google won’t be able to render them and index JavaScript-powered content.
Blocking JS files isn’t a negative ranking factor per se. But if it is only used for embellishment or if for some reason you don’t want to have the JS-injected content indexed, you can keep JS files blocked. In all other cases, let Google render your files.
Google and browsers can’t load JS files
After reading the robots.txt file to check if you allow crawling, Googlebot makes an HTTP request to access your JavaScript URLs. For it to proceed with rendering the files, it should get the 200 OK response code. Sometimes though, other status codes like 4XX or 5XX are returned. If you need a quick recap of what different status codes, mean this guide is for you.
JavaScript with 4XX status
4XX response codes mean that the requested resource does not exist. Speaking of JS files, it means that Googlebot followed the URLs indicated in the <head> section of the page, but did not find your files at the designated locations. When a page returns a 4XX, it usually means that the page was deleted. With JavaScript, the error often occurs because the path to the file is not indicated correctly. It may also be a permission issue.
The bad thing about 4XX response codes is that Google’s not the only one experiencing issues rendering your JS files. Browsers won’t be able to execute such files either which means your website won’t look that great and will lose its interactivity.
If JS is used to load content to the website (e.g. stock exchange rates to a respective website), all the dynamically rendered content will be missing if the code isn’t running properly.
To fix the error, your developers will have to first figure out what’s causing them, and the reasons will vary depending on the technologies used.
JavaScript with 5XX status
5XX response codes indicate that there’s a problem on your web server’s end. It means that a browser or Googlebot sends an HTTP request, locates your JavaScript file but then your server fails to return the file.
In the worst-case scenario, the error occurs because your whole website is down. It happens when your server cannot cope with the amount of traffic. The abrupt increase in traffic may be natural, but in most cases, it is caused by aggressive parsing software or a malicious bot flooding your server with the specific purpose to put it down (DDoS).
The server may also fail to deliver a JavaScript file if the browser fails to fetch them during the set time span causing a 504 timeout error. This can happen if the file bundle was too big or if a user had a slow Internet connection.
To prevent this, you can configure your website server in a way to make it less impatient. But making the server wait for too long is not recommended either.
The thing is, loading a huge JS bundle takes a lot of server resources and if all your server resources are used for loading the file, it won’t be able to fulfill other requests. As a result, your whole website is put on hold until the file loads.
JS files are not loading fast enough
In this section, let’s dig deeper into the issues that make your JS files load for ages or just a bit longer than desired. Even if both browsers and Googlebot manage to load and render your JS files, but it takes them a while to do so, you should feel concerned.
The faster a browser can load page resources, the better experience users get, and if the files are loading slowly, users have to wait for a while to have the page rendered in their browser.
JavaScript with 3XX status
The 3xx status code indicates that the requested resource has been rerouted, and is essential to redirecting the URLs in your website code to the new location. This is true not only for the domain and the path but also for the HTTP/HTTPS protocol used to retrieve the resource.
In the example below, the JavaScript file is initially referenced using an HTTP URL:
<script nomodule type="text/javascript" src="http://static.files.bbci.co.uk/orbit/7c43b78b94b8ed38e941a5a5336425e5/js/polyfills.js"></script>
However, the correct and up-to-date URL for the file should use HTTPS:
<script nomodule type="text/javascript" src="https://static.files.bbci.co.uk/orbit/7c43b78b94b8ed38e941a5a5336425e5/js/polyfills.js"></script>
Googlebot and browsers will still fetch the files since your server will redirect them to the proper address. The caveat is that they’ll have to make an additional HTTP request to reach the destination URL. This is not good for loading time. While the performance impact might not be drastic for a single URL or a couple of files, at a larger scale, it can significantly slow down the page loading time.
The solution here is evident—you simply need to replace every old JavaScript URL in the website code with up-to-date destination URLs.
Caching is not enabled
A great way to minimize the number of HTTP requests to your server is to allow caching in a response header. You surely have heard about caching—you’d often get a suggestion to clear your browser cache when information on a website is not displayed properly.
What cache actually does is it saves a copy of your website resources when a user visits your site. Then, the next time this user comes to your website, the browser will no longer have to fetch the resources—it will serve users the saved copy instead. Caching is essential for website performance as it allows for reducing latency and network load.
Cache-control HTTP header is used to specify caching rules browsers should follow: it indicates whether a particular resource can be cached or not, who can cache it, and how long the cached copy can last. It is highly recommended to allow caching of JS files as browsers upload these files every time users visit a website, so having them stored in cache can significantly boost the page loading time.
Here’s an example of setting caching for JS files to one day and public access.
<filesMatch ".(css|js)$"> Header set Cache-Control "max-age=86400, public" </filesMatch>
It is worth noting though that Googlebot normally ignores the cache-control HTTP header because following the directives website set would put too much load on the crawling and rendering infrastructure.
Therefore, whenever you update your JavaScript file and want Google to take notice of it, it is recommended to rename your file and upload it using a different URL. That way, Google will refetch the file because it will treat it as a totally new resource it hasn’t encountered before.
The number of files matters
Using multiple JavaScript files may be convenient from the developer’s perspective, but it is not great performance-wise. Browsers send a separate HTTP request to load every file, and the number of simultaneous network connections a browser can process is limited. Therefore, all the JS resources of a page will be loading one by one decreasing the rendering speed.
For this reason, it is recommended to bundle your JavaScript file to keep the number of files a browser will have to load down to the minimum.
From Google’s perspective, too many JS files is not a problem meaning that it will render them anyway. But the more files you have, the more you spend your crawl budget on having JS files loaded. For huge websites with millions of pages, it may be critical as it would mean Google will not timely index some pages.
File size matters as well
The problem with bundling JS files is that as your website grows, new lines of code are added to the files and eventually they may grow large enough that it will become a performance issue.
Depending on the way your website is structured it may be reasonable to not bundle all your JS files together, but instead to group them in several smaller files, like a separate file for your blog JavaScript, another one for the forum JavaScript, etc.
Another reason for splitting one huge JavaScript bundle is caching. If you have it all in one file, every time you change something in your JavaScript code, browsers and search engines will have to recache the whole bundle. This is not great both for indexing and for the user experience.
In terms of indexing it can go two ways depending on the caching technologies used: you’ll either force Googlebot to constantly recache your JavaScript bundle or Google may fail to notice in time that the cache is no longer valid and you will end up with Google seeing outdated content.
Speaking of user experience, whenever you update some JS code within the bundle, browsers can no longer serve cached copies to any of your users. So, even if you only change the JS code for your blog, all your users including those who never visited your blog will have to wait for the browsers to load the whole JS bundle to access any page on your website.
Compressing and minifying CSS and JavaScript
To keep your JS files light, you’ll want to compress and minify them. Both practices are meant to reduce the size of your website resources by editing the source code, but they are distinctly different.
Compression is the process of replacing repetitive strings within the source code with pointers to the first instance of that string. Since any code has lots of repetitive parts (think of how many <script> tags your JavaScript contains) and pointers use less space than the initial code, file compression allows to reduce the file size by up to 70%. Browsers cannot read the compressed code, but as long as the browser supports the compression method, it will be able to uncompress the file before rendering.
The great thing about compression is that developers don’t need to do it manually. All of the heavy lifting is done by the server provided that it was configured to compress resources. For example, for Apache servers, a few lines of code are added to the .htaccess file to enable compression.
Minification is the process of removing white space, non-required semicolons, unnecessary lines, and comments from the source code. As a result, you get the code that is not quite human-readable, but still valid. Browsers can render such codes perfectly well, and they’ll even parse and load it faster than raw code. Web developers will have to take care of minification on their own, but with plenty of dedicated tools, it shouldn’t be a problem.
Speaking of reducing the file size, minification won’t give you the staggering 70%. If you already have compression enabled on your server, further minifying your resources can help you reduce their size by an additional few to 16% depending on how your resources are coded. For this reason, some web developers believe minification is obsolete. However, the smaller your JS files are, the better. So a good practice is to combine both methods.
Using external JavaScript files
Many websites tend to use external JavaScript files hosted on third-party domains. Reusing an open-source code that solves your problem perfectly well may seem like a great idea—after all, there’s no point in reinventing the wheel. There’s really nothing wrong with using a ready-made solution as long as it is copied and uploaded to the website’s server. At the same time, using third-party JS files hosted externally is associated with numerous risks.
First and foremost, we’re talking about security risks. If a website that hosts the files you use gets hacked, you may end up running a malicious code injected into the external JS file. Hackers may steal private data of your users including their passwords and credit card details.
Performance-wise, think of all the errors discussed above. If you have no access to the server where the JS files are hosted, you won’t be able to set up caching, compression, or debug 5XX errors.
If the website that hosts the files at some point removes the file and you fail to notice it in a timely manner, your website will not work properly and you won’t be able to quickly replace a 404 JS file with a valid one.
Finally, if the website hosting JS files sets a 3XX redirect to a (slightly) different file, your webpage may look and work not exactly as expected.
If you do use third-party JS files, our advice is to keep a close eye on them. Still, a way better solution is not to use external JS at all.

