Data for search and AI visibility that goes beyond the surface
Visibility is multilayered. So should the data you build your analysis on. Get that depth across multiple dimensions




AI visibility data structured for patterns, trends, and insights
25.5M+ prompts tracked across 5 AI engines
Prompt-level data on mentions, cited sources, and links
Competitor benchmarking across all supported engines
Monthly data refresh and historical trends
Full data access via AI Search API
Keyword data at scale to support cross-market analysis

Proprietary crawlers
We continuously crawl search results pages, building data from the source rather than relying on third-party feeds.

Individual search volume
Keywords aren’t grouped. Each term’s search volume is calculated independently, giving you cleaner data for analysis.

Growing database
Coverage across 188 locations, with depth at each. 5.4B keywords across with 2.2 billion domain profiles.
Now let the numbers speak for themselves




























































































































































































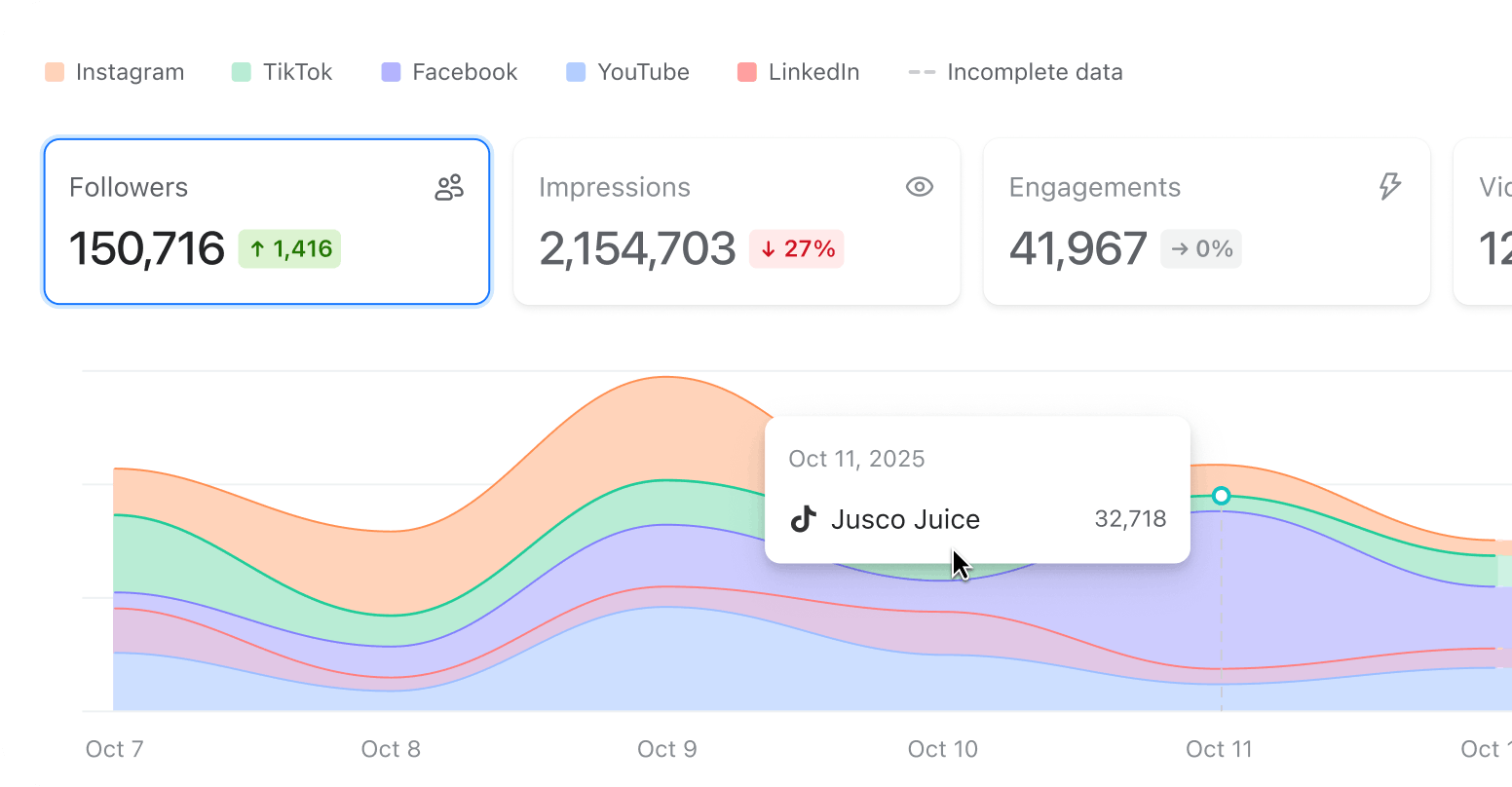
Add social to your data picture
Bring social analytics into the mix with Planable to better prove the value of your visibility. Get one more layer alongside search and LLMs

Backlink data for deep analysis across client portfolios
Fresh backlink data to work on, with new links identified continuously
Rapid updates to filter irrelevant backlinks and calculate accurate Domain Trust
Continuously expanding index, actively crawled at scale across the web
Toxicity scores, dofollow/nofollow ratios, and quality metrics at the link level
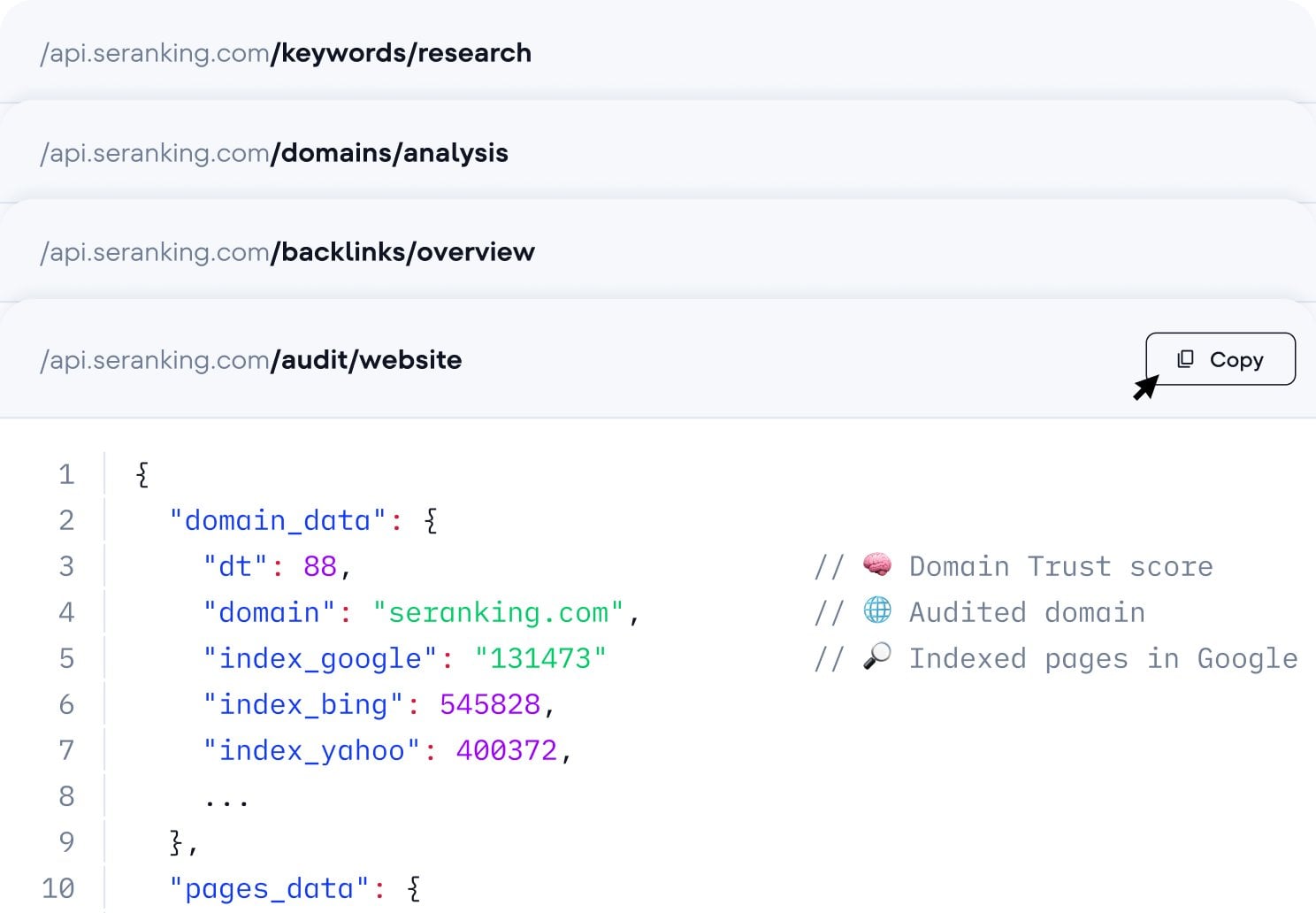
Integrate SE Ranking data into your own stack to scale your efforts
Query across 5 data categories, including keywords, domains, backlinks, AI search, and site audit
Quickstarts for AI visibility analysis, competitive research, link building, and reporting
Pull historical data and trend analysis directly into your own reporting environment
Connect with the tools your team is already using: Data Studio, Make.com, n8n, and MCP
What makes SE Ranking data reliable?
Reliability comes down to how data is collected and maintained. The data you’re working with is collected and maintained directly. SE Ranking runs its own crawlers across all core datasets, applies AI and ML algorithms to calculate accurate metrics, and continuously expands coverage.
How large is SE Ranking’s keyword database?
The keyword database currently spans 5.4 billion keywords across 188 geographic databases, with 2.2 billion domain profiles indexed. Coverage varies by market. For example, the US database holds 584M keywords, the UK 755M, Germany 667M. The full breakdown by country is available in the table above. The database is actively maintained and continues to grow.
How large is the backlinks index?
The backlink index currently covers 2.7T backlinks across 420M indexed domains, with 6B pages crawled daily. Beyond scale, the index is structured around four data quality dimensions: freshness (58% of backlinks updated within 90 days), relevance (fast update cycles), completeness (expanding coverage), and granularity (metrics and scores at the link level).
Does SE Ranking provide AI search data?
Yes. SE Ranking tracks AI search visibility across five engines (ChatGPT, Google AI Overview, Google AI Mode, Perplexity, and Gemini) with 25.5 million prompts tracked monthly. The data is collected at the prompt level, covering mention rates, citation presence, cited sources, links, and traffic signals. You can also run competitive analysis and track trends.
What can I do with the Data API?
The Data API provides programmatic access to the same data layers available in the platform. It’s designed for teams building custom dashboards, integrating search and AI visibility data into proprietary reporting workflows, or running analysis at a scale that requires direct data access rather than platform UI. Quickstarts are available for common use cases, including AI visibility analysis, competitive research, link building, and reporting.
Can I use SE Ranking data in my own dashboards?
Yes. The Data API is specifically designed for this. Endpoints cover all core data categories, and the API returns structured data formatted for integration into external systems. For teams with custom infrastructure, direct API integration is documented in full, including authentication, rate limits, and endpoint-level credit costs.