Robots.txt setup and analysis: All you need to know
-
The robots.txt file serves as a guideline for robots, informing them which pages should and shouldn’t be crawled. However, a bot can decide not to obey.
-
The robots.txt file cannot directly prevent indexing, but it can influence a robot’s decision to crawl or ignore certain documents or files.
-
While robots.txt, meta robots, and x-robots instruct search engine bots, they differ in application: robots.txt controls crawling, meta robots tags work at the page level, and the X-Robots-Tag offers more granular control over indexing.
-
Hiding website content with the disallow directive saves the crawl budget and prevents unwanted content from surfacing on search.
-
Following syntax rules ensures search bots can read and understand your robots.txt file correctly.
-
Creating a robots.txt file is possible with text editors that support UTF-8 encoding, or through built-in tools in popular CMS platforms like WordPress, Magento, and Shopify.
-
Check your robots.txt file with tools like Google Search Console or SEO platforms like SE Ranking. This helps you identify potential issues and ensures the file works as intended.
-
Common issues include format mismatches, incorrect file placement, misuse of directives, and conflicting instructions.
-
Keep in mind that path values in robots.txt are case-sensitive. Also, make sure each directive is placed on a new line, use wildcards for flexibility, create separate files for different domains, and test your website after updating robots.txt to ensure important URLs aren’t accidentally blocked.
What is a robots.txt file?
A robots.txt file is a text document located in the root directory of a website. The information it contains is intended specifically for search engine crawlers. It instructs them on which URLs, including pages, files, folders, etc., should be crawled and which ones should not. While the presence of this file is not mandatory for a website to function, it must be set up correctly for proper SEO.
The decision to use robots.txt was made back in 1994 as part of the Robots Exclusion Standard. According to Google Search Central, the primary purpose of this file is not to hide web pages from search results, but instead to limit the number of requests made by robots to sites and to reduce server load.
Generally speaking, the content of the robots.txt file should be viewed as a recommendation for search crawlers that defines the rules for website crawling. To access the content of a site’s robots.txt file, simply type “/robots.txt” after the domain name in the browser.
How does robots.txt work?
First of all, it’s important to note that search engines need to crawl and index specific search results displayed on SERPs. To accomplish this task, web crawlers systematically browse the web, collecting data from each webpage they encounter. The term “spidering” is occasionally used to describe this crawling activity.
When crawlers reach a website, they check the robots.txt file, which contains instructions on how to crawl and index pages on the website. If there is no robots.txt file, or it does not include any directives that forbid user-agent activity, search bots will proceed to crawl the site until it reaches the crawl budget or other restrictions.
What is llms.txt, and do you need it for AI bots?
Llms.txt is a proposed standard that aims at directing AI crawlers to a better understanding of your site. Unlike robots.txt that directs crawlers to ignore specific pages, llms.txt provides links to important pages and describes them in human language for the AI crawlers, like an enhanced sitemap.

Despite being around for quite a while and some AI engines proclaiming their interest in the standard, there’s no indication it’s being enforced by anyone. According to SE Ranking research on the matter, llms.txt does not influence AI visibility and number of citations in AI search.
Most of the functions llms.txt tries to standardize are already covered by the sitemap and Schema markup, or are irrelevant because AI can understand the context on its own.
Why do you need robots.txt?
There are two main reasons robots.txt file is an important SEO practice, crawling management and crawl budget optimization.
Manage crawling (including AI bots!)
The primary function of the robots.txt file is to prevent the scanning of pages and resource files that you want to make private. This may include admin panels, duplicate content, pages that are in development, and query parameter pages like filters or results of internal search.
Note: Using the “robots.txt disallow” directive does not guarantee that a particular webpage will not be crawled or will be excluded from SERPs. Google reserves the right to consider various external factors, such as incoming links, when determining the relevance of a webpage and its inclusion in search results. To explicitly prevent a page from being indexed, it is recommended to use the “noindex” robots meta tag or the X-Robots-Tag HTTP header. Password protection can also be used to prevent indexing.
Robots.txt directives are also honored by most popular AI engines like, Gemini, Perplexity, and ChatGPT. If you want to disallow specific AI tools from accessing your site, add the corresponding directive for their User-agent.
There are hundreds of AI User-agent names, and most tools make a distinction between bots used for training, indexing, and user-initiated searches. Training bots look for content the AI model can train on, search/indexing bots create internal indexes for search, and user-initiated bots fetch fresh content on user request if it’s not in the index.
Here are a few examples.
Search/Index Bots (Build indexes for AI-powered search):
- OAI-Searchbot
- Claude-SearchBot
- PerplexityBot
User-Initiated Bots (Fetch content when users ask questions):
- ChatGPT-User
- Claude-User
- Perplexity-User
- Applebot
Note: Some of the user-initiated bots may be used for training as well.
Training Bots (Used to collect data for training AI models):
- Meta-ExternalAgent
- Google-Extended
- GPTBot
- ClaudeBot
- Applebot-Extended
- Meta-ExternalAgent
All AI platforms recommend allowing search/indexing bots to access the site to ensure AI visibility is not impacted. However, behavior of other crawlers may differ. There are also differences between platforms.
For instance, blocking OpenAi’s indexing crawler OAI-Searchbot will prevent your website from apprearing in search results, but it can still be referenced in navigational links. Perplexity’s indexing bot will also avoid going through websites that disallow it, but will index the domain and provide a brief summary for it.
Most training bots will strictly obey robots.txt directives, but some user-initiated bots like ChatGPT’s ChatGPT-User may ignore them.
Optimize Crawl Budget
The crawl budget refers to the number of web pages on a website that a search robot devotes to crawling. To use the crawl budget more efficiently, search robots should be directed only to the most important content on websites and blocked from accessing unhelpful information.
Optimizing the crawl budget helps search engines allocate their limited resources efficiently, resulting in faster indexing of new content and improved visibility in search results. It’s important to keep in mind, however, that if your site has more pages than your allocated crawl budget allows, some pages may be left uncrawled, and consequently unindexed. Unindexed pages can’t appear anywhere on the SERP.
In most cases, you should consider optimizing your crawl budget usage if you run a large website (thousands of pages), a medium website with rapidly changing content, or have a significant percentage of unindexed pages. Optimization will ensure search engines fully cover all your important pages.
Let’s consider a scenario where your website has a lot of trivial content compared to that of its primary pages. In cases like these, you can optimize your crawl budget by excluding unwanted resources from the search crawler’s ‘to visit’ list.
For instance, you can use the “Disallow” directive followed by a specific file extension, such as “Disallow:/*.pdf,” to prevent search engines from crawling any PDF resources on your site.
Another common benefit of using robots.txt is its ability to address content-crawling issues on your server, if any. For instance, if you have infinite calendar scripts that may cause problems when frequently accessed by robots, you can disallow the crawling of that script through the robots.txt file.
Example of robots.txt content
Having a template with up-to-date directives can help you create a properly formatted robots.txt file, specifying the required robots and restricting access to relevant files.
User-agent: [bot name]
Disallow: /[path to file or folder]/
Disallow: /[path to file or folder]/
Disallow: /[path to file or folder]/
Sitemap: [Sitemap URL]
Now, let’s explore a few examples of what a robots.txt file might look like.
1. Allowing all web spider bots access to all content.
Here’s a basic example of a robotx.txt file code that grants all web crawlers access to all websites:
User-agent: *
Allow: /
# Sitemaps
Sitemap: https://www.example.com/sitemap.xml
In this example, the “User-agent” directive uses an asterisk (*) to apply the instructions to all web crawlers. Crawl-delay gives crawlers unprohibited access but asks them to wait 10 seconds between requests. The sitemap declaration doesn’t restrict any access but points crawlers to the sitemap. Lines starting with a sharp sign are comments ignored by crawlers.
2. Blocking a specific web crawler from a specific web page.
The following example specifies access permissions for the “Bingbot” user-agent, which is the web crawler used by Microsoft’s search engine, Bing. It includes a list of website directories that are closed for scanning, as well as a few directories and pages that are allowed to be accessed on the website.

3. Blocking all web crawlers from all content.
User-agent: * Disallow: /
In this example, the “User-agent” directive still applies to all web crawlers. However, the “Disallow” directive uses a forward slash (/) as its value, indicating that all content on the website should be blocked from access by any web crawler. This effectively tells all robots not to crawl any pages on the site.
Please note that blocking all web crawlers from accessing a website’s content using the robots.txt file is an extreme measure and is not recommended in most cases. It may only be useful when your new site is under development and not ready to be open to search engines. In other situations, websites typically use the robots.txt file to control access to specific parts of their site, such as blocking certain directories or files, rather than blocking all content.
4. Giving instructions to AI bots
Robots.txt can also be used to give instructions to AI crawlers. Here’s an example of a set of directives that allow crawling the whole website and block off specific subdirectories.
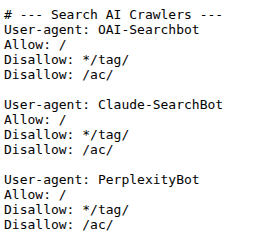
Blocking off the whole website is not recommended as it can hurt your AI visibility. Perplexity recommends allowing their search crawler, PerplexityBot, and user-initiated crawler, Perplexity‑User, to ensure AI visibility, as neither is used for AI training. OpenAI recommends allowing OAI-SearchBot for AI visibility, only GPTBot is used for training the model.
Keep in mind that there isn’t a single user agent name for all AI crawlers. If you want to give directives to them, you’ll have to reference each user agent name separately.
How to find robots.txt
When it comes to locating the robots.txt file on a website, there are a couple of methods you can use:
To find the robots.txt file, add “/robots.txt” to the domain name of the website you want to examine. For example, if the website’s domain is “example.com,” you would enter “example.com/robots.txt” into your web browser’s address bar. This will take you directly to the robots.txt file if it exists on the website.
Another less frequently used, but still common method for CMS users, is to find and edit robots.txt files directly within the system. Let’s go through some popular ones.
A robots.txt in WordPress
To find and modify a robots.txt file in WordPress, you can create one manually or use a plugin.
To create one manually:
- Create a text file named “robots.txt”
- Upload it to your root directory via FTP client
Using a Yoast SEO plugin:
- Go to the Yoast SEO > Tools
- Click on File Editor (make sure you have file editing enabled)
- Click on the Create robots.txt file button
- View or edit the robots.txt there
Using an All in One SEO plugin:
- Go to the All in One SEO > Tools
- Click on the Robots.txt Editor
- Click the toggle to enable Custom Robots.txt.
- View or edit the robots.txt there
A robots.txt in Magento
Magento automatically generates a default robots.txt file.
To edit:
- Login to the Magento admin panel
- Go to Content > Design > Configuration
- Click on Edit for the Main Website
- Expand the Search Engine Robots section
- Edit the content in the Edit custom instruction of robots.txt file field
- Save the configuration
A robots.txt in Shopify
Shopify automatically generates a default robots.txt file.
To edit:
- Login to your Shopify admin panel
- Сlick Settings > Apps and sales channels
- Go to Online Store > Themes
- Click the … button next to your current theme and select Edit code
- Click Add a new template > robots
- Click Create template
- Edit the content as needed
- Save your changes
1. Analyze your website using automated tools like SE Ranking’s Site Audit.
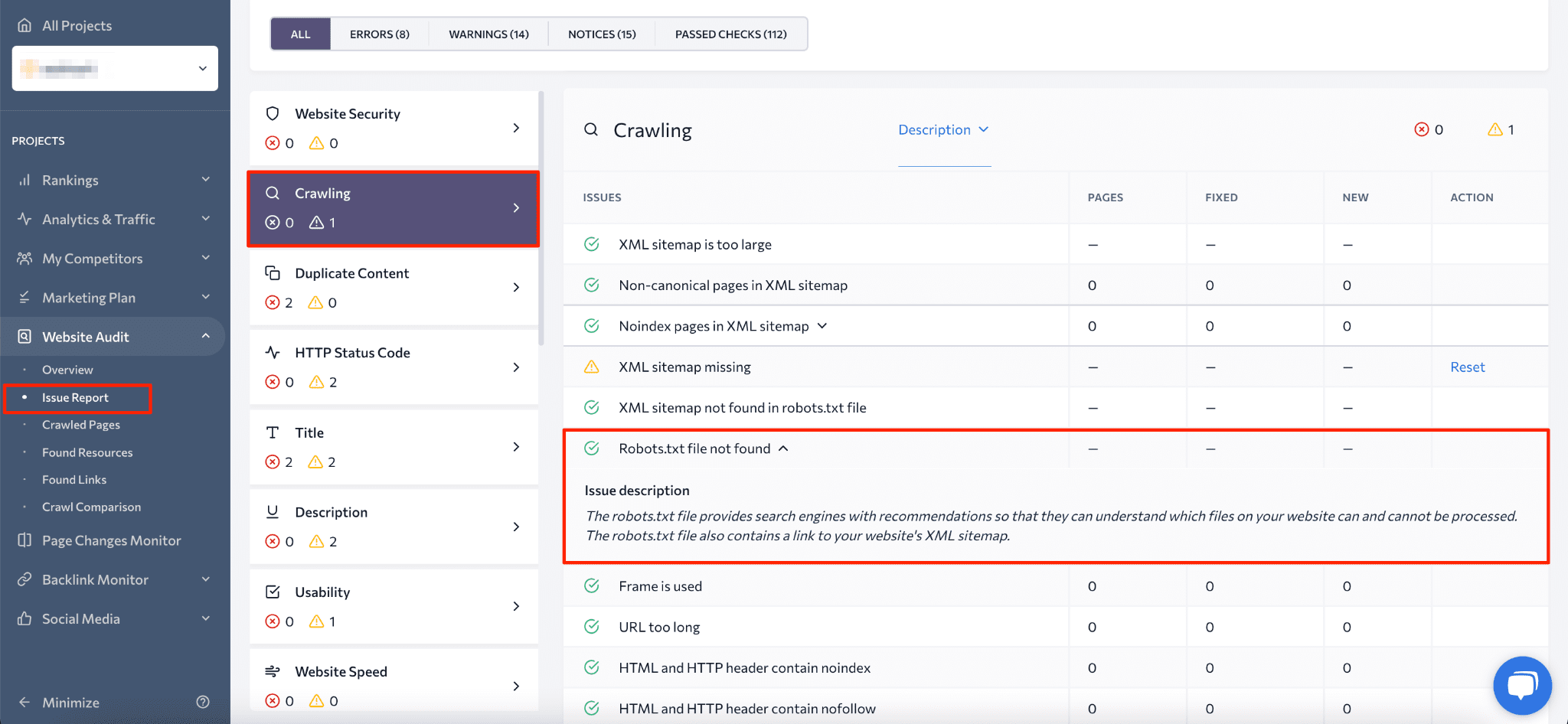
Another way to identify the presence of a robots.txt file is by utilizing a website audit tool. This tool, for example, checks your site and provides information on whether you have a robots.txt file and which pages it blocks. Review the blocked pages to determine if they should be blocked or if access was accidentally restricted.
To start the audit, simply initiate the process and wait for it to complete (you’ll receive a notification in your inbox). Then, go to the Issue Report, select the Crawling block, and check for the Robots.txt file not found problem.
2. Generate robots.txt for your CMS
In case your website doesn’t have a robots.txt file, you can create one from scratch or generate one using SE Ranking’s free robots.txt generator. You can add directives and paths manually or generate the file automatically. Indicate your CMS, and the tool will add all subdirectories that typically should be blocked from crawling.
Here’s an example for WordPress.
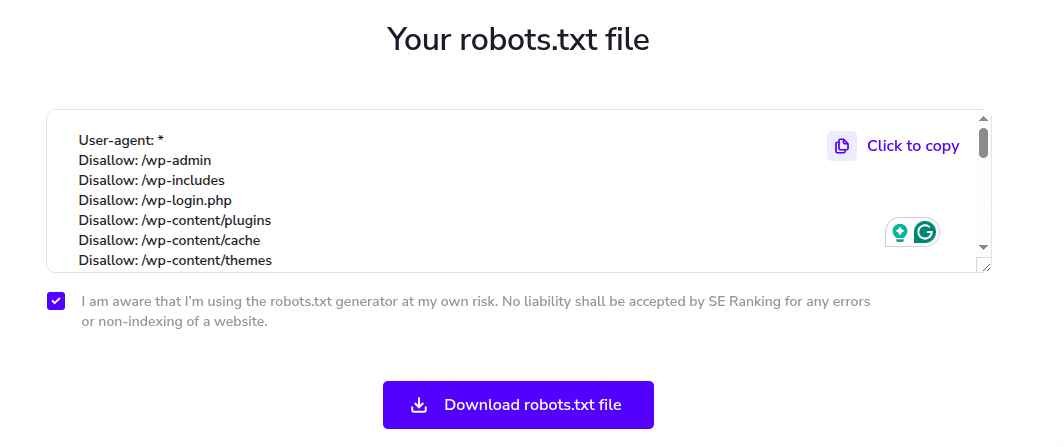
If there are any other directories you want to block from crawling, add them afterward.
How search engines find your robots.txt file
Search engines have specific mechanisms to discover and access the robots.txt file on your website. Here’s how they typically find it:
1. Crawling a website: Search engine crawlers continuously traverse the web, visiting websites and following links to discover web pages.
2. Requesting robots.txt: When a search engine crawler accesses a website, it looks for the presence of a robots.txt file by adding “/robots.txt” to the website’s domain.
Note: After successfully uploading and testing your robots.txt file, Google’s crawlers will automatically detect it and begin using its instructions. There is no need to take further action. However, if you have made modifications to your robots.txt file and want to promptly update Google, you’ll need to learn how to submit an updated robots.txt file.
3. Retrieving robots.txt: If a robots.txt file exists at the requested location, the crawler will download and parse the file to determine the crawling directives.
4. Following instructions: After obtaining the robots.txt file, the search engine crawler follows the instructions outlined within it.
Robots.txt vs meta robots vs x-robots
While the robots.txt file, robots meta tag, and X-Robots-Tag serve similar purposes in terms of instructing search engine spider bots, they differ in their application and area of control.
When it comes to hiding site content from search results, relying solely on the robots.txt file may not be enough. As mentioned above, the robots.txt file is primarily a recommendation to web crawlers. It informs them about which areas of a website they are allowed to access. However, it does not guarantee that the content will not be indexed by search engines as links to it can be discovered on other websites. To prevent indexing, webmasters should employ additional methods.
Robots meta tag
One effective technique is using the robots meta tag, which is placed within the <head> section of a page’s HTML code. By including a meta tag with the “noindex” directive, webmasters explicitly signal search engine bots that the page’s content should not be indexed. This method provides more precise control over individual pages and their indexing status compared to the broad directives of the robots.txt file.
Here’s an example code snippet for preventing search engine indexing at the page level:
<meta name=“robots” content=“noindex”>
Similar to robots.txt, this meta tag allows for restricting access to specific bots. For example, to restrict a specific bot (e.g., Googlebot), use:
<meta name=“googlebot” content=“noindex”>
X-Robots-Tag
You can also utilize the X-Robots-Tag in the site’s configuration file to further limit page indexing. This method offers an additional layer of control and flexibility with managing indexing at a granular level.
To learn more about this topic, read our complete guide on the robots meta tag and X-Robots-Tag.
Pages and files that are usually closed off via robots.txt
1. Admin dashboard and system files.
Internal and service files that only website administrators or webmasters should interact with.
2. Auxiliary pages that only appear after specific user actions.
Pages that clients are sent to after successfully completing an order, client forms, authorization or password recovery pages.
3. Search pages.
Pages displayed after a website visitor enters a query into the site’s search box are usually closed off from search engine crawlers.
4. Filter pages.
Results that are displayed with an applied filter (size, color, manufacturer, etc.) are separate pages and can be looked at as duplicate content. SEO experts typically prevent them from being crawled unless they drive traffic for brand keywords or other target queries. Aggregator sites, some ecommerce sites, and properly configured filter pages that can drive traffic may be an exception.
5. Files of a certain format.
Files like photos, videos, .PDF documents, JS files. With the help of robots.txt, you can restrict the scanning of individual or extension-specific files.
Robots.txt syntax
Webmasters must understand the syntax and structure of the robots.txt file to control the visibility of their web pages on search engines. The robots.txt file typically contains a set of rules that determine which files on a domain or subdomain can be accessed by crawlers. These rules can either block or allow access to specific file paths. By default, if not explicitly stated in the robots.txt file, all files are assumed to be allowed for crawling.
The robots.txt file consists of groups, each containing multiple rules or directives. These rules are listed once per line. Each group begins with a User-agent line that specifies the target audience for the rules.
A group provides the following information:
- The user agent to which the rules apply.
- The directories or files that the user agent is allowed to access.
- The directories or files that the user agent is not allowed to access.
When processing the robots.txt file, crawlers follow the most specific path. For instance, if the file allows crawling all website content, disallows one directory, and allows a single subdirectory of it, the user agent will access all content and the specified subdirectory, ignoring the rest of the disallowed subdirectory.
A user agent can only match one rule set. If there are multiple groups targeting the same user agent, these groups are merged into a single group before being processed. In case of conflicting directives, Google will choose the least restrictive one.
Here’s an example of a basic robots.txt file with two rules:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml
Since crawlers look for the most specific set of rules, this file will disallow Googlebot from accessing the /nogooglebot/ folder and allow every other crawler to access the entirety of the site.
When providing paths in directives, the path is interpreted as all paths that start with it. In this example, this would include paths like.
- https://www.example.com/nogooglebot/
- https://www.example.com/nogooglebot/folder/
- https://www.example.com/nogooglebot/folder/content.html
- https://www.example.com/nogooglebot/folder/content.html?parameter=0
It will not include this path, however, https://www.example.com/folder/nogooglebot/.
Now, let’s look at different elements of robots.txt syntax in more detail.
Wildcard Symbols
If you want more precise control over web crawler behavior, you can use wildcard characters. There are two of them in robots.txt — * and $.
The asterisk wildcard represents any sequence of symbols. Here are a few examples of how it can be used.
- User-agent: * — Includes all user agents.
- User-agent: googlebot* — Includes user agents that start with “googlebot” like “googlebot-news” or “googlebot/1.2.”
- Disallow: */folder/ — Disallows all instances of this folder name, whether it’s in the root folder or in another folder.
- Disallow: /*.png — Disallows all paths contain “.png” anywhere in the URL path. This includes paths that have symbols after the extension, like “/image.png?scr=site.com.”
The dollar sign wildcard represents the end of the line. This specifies that only paths that end with the given string are included in the directive. Here are a few examples of its usage.
- Disallow: /folder/$ — Disallows the exact /folder/ path, while allowing crawling paths that contain it.
- Allow: /*.pdf$ — Allows crawling paths that end in .pdf. In this case, crawling paths likes “/file.pdf?parameters” is excluded from the directive.
The User-Agent Directive
The user-agent directive is mandatory and defines the search robot to which the rules apply. Each rule group starts with this directive if there are several bots.
Google has several bots responsible for different types of content.
- Googlebot: crawls websites for desktop and mobile devices
- Googlebot Image: crawls site images to display in the “Images” section and image-depending products
- Googlebot Video: scans and displays videos
- Googlebot News: selects useful and high-quality articles for the “News” section
- Google-InspectionTool: a URL testing tool that mimics Googlebot by crawling every page it’s allowed access to
- Google StoreBot: scans various web page types, such as product details, cart, and checkout pages
- GoogleOther: fetches publicly accessible content from sites, including one-off crawls for internal research and development
- Google-CloudVertexBot: crawls sites on site owners’ request when building Vertex AI Agents
- Google-Extended: a standalone product token used to manage whether sites help improve Gemini Apps and Vertex AI generative APIs and future models
There’s also a separate group of bots, or special-case crawlers, that includes AdSense, Google-Safety, and others. These bots may have different behaviors and permissions compared to common crawlers.
The complete list of Google robots (user agents) is available in the official Help documentation.
Other search engines also have similar roots, such as Bingbot for Bing, Slurp for Yahoo!, Baiduspider for Baidu, and many more. There are over 500 various search engine bots.
Example
- User-agent: * applies to all existing robots.
- User-agent: Googlebot applies to Google’s robot.
- User-agent: Bingbot applies to Bing’s robot.
- User-agent: Slurp applies to Yahoo!’s Robot.
The Disallow Directive
Disallow is a key command that instructs search engine bots not to scan a page, file or folder. The names of the files and folders that you want to restrict access to are indicated after the “/” symbol.
Example 1. Specifying different parameters after Disallow.
Disallow: /link to page disallows access to a specific URL.
Disallow: /folder name/ closes access to the folder.
Disallow: /*.png$ closes access to the PNG format images.
Disallow: /. The absence of any instructions after the “/” symbol indicates that the site is completely closed off from scanning, which can be useful during website development.
Example 2. Disabling the scanning of all .PDF files on the site.
User-agent: Googlebot
Disallow: /*.pdf$
The Allow Directive
In the robots.txt file, the Allow directive functions opposite to Disallow by granting access to website content. These commands are often used together, especially when you need to open access to specific information like a photo in a hidden media file directory.
Example. Using Allow to scan one image in a closed album.
Specify the Allow directive with the image URL and, in another line, the Disallow directive along with the folder name where the file is located. The order of lines is important, as crawlers process groups from top to bottom.
Disallow: /album/
Allow: /album/picture1.jpg
The “robots.txt Allow All” directive is typically used when there are no specific restrictions or disallowances for search engines. However, it’s important to note that the “Allow: /” directive is not a necessary component of the robots.txt file. In fact, some webmasters choose not to include it at all, relying solely on the default behavior of search engine crawlers.
The Allow directive is not part of the original robots.txt specification. This means it may not be supported by all bots. While many popular crawlers like Googlebot recognize and respect the Allow directive, others might not.
According to a Standard for Robots Exclusion,”Unrecognized headers are ignored”. This means that for bots that don’t recognize the “Allow” directive, the result can be different from what the webmaster expected. Keep this in mind when creating your robots.txt files.
The Sitemap Directive
The sitemap directive in robots.txt indicates the path to the sitemap. This directive can be omitted if the sitemap has a standard name, is located in the root directory, and is accessible through the link “site name”/sitemap.xml, similar to the robots.txt file.
Example
Sitemap: https://website.com/sitemap.xml
While the robots.txt file is primarily used to control the scanning of your website, the sitemap helps search engines understand your content’s organization and hierarchical structure. By including a link to your sitemap in the robots.txt file, you provide search engine crawlers with an easy way to locate and analyze the sitemap, leading to more efficient crawling and indexing of your website. So it’s not mandatory but highly recommended to include a reference to your sitemap in the robots.txt file.
Comments
You can add comments to the robots.txt file that explain specific directives, document changes or updates to the file, organize different sections, or provide context to other team members. Comments are lines that start with the “#” symbol. Bots ignore these lines when processing the file. They help you and other team members understand the file, but don’t affect how bots read it. Here’s an example from the Wizzair robots.txt file.

If your robots.txt file is rather large and includes nonstandard directives, it’s best to leave comments explaining what the directives try to achieve.
Nonstandard extensions
Apart from these, there are a few nonstandard directives that can be used in robots.txt.
Sitemap indicates the path to the sitemap file.
Example
Sitemap: https://website.com/sitemap.xml
This directive can be omitted if the sitemap has a standard name, is located in the root directory, and is accessible through the link “site name”/sitemap.xml, similar to the robots.txt file.
It’s an optional directive as Google and other search engines will search for a sitemap unprompted, but it’s best to use it anyways as a best practice to ensure they find it faster. Especially if your site has multiple sitemaps like in the example below.
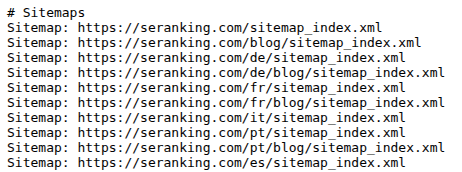
Crawl-delay specifies delay between requesting pages. Initially it was meant to ease server load, but it’s rarely used now. Google crawlers don’t honor this directive, while Bing, Yahoo, and Yandex still do.
Use Google Search Console to submit a report for overcrawling if you find it to be an issue.
Content-signal is a directive proposed by Cloudflare to specify AI behavior on your website. It allows you to allow and disallow AI input, AI training, and AI search.
User-Agent: *
Content-Signal: ai-train=no, search=yes, ai-input=no
Allow: /
In this example, searching the site is allowed, but using its content for training and AI input is forbidden.
It’s a relatively new directive, and many crawlers will disregard it. Google doesn’t have an official stance on it yet. For now, it’s best to avoid using it unless Google officially adopts it.
How to сreate a robots.txt file
A well-crafted robots.txt file serves as the foundation for technical SEO.
Since the file has a .txt extension, any text editor that supports UTF-8 encoding will suffice. The simplest options are Notepad (Windows) or TextEdit (Mac).
As we already mentioned earlier, most CMS platforms also provide solutions for creating a robots.txt file. For instance, WordPress creates a virtual robots.txt file by default, which can be viewed online by appending “/robots.txt” to the website’s domain name. However, to modify this file, you need to create your own version. This can be done either through a plugin (e.g., Yoast or All in One SEO Pack) or manually.
Magento and Wix, as CMS platforms, also automatically generate the robots.txt file, but it contains only basic instructions for web crawlers. This is why it’s recommended to make custom robots.txt instructions within these systems to accurately optimize the crawling budget.
You can also use tools like SE Ranking’s Robots.txt Generator to generate a custom robots.txt file based on the specified information. You have the option to create a robots.txt file from scratch or to choose one of the suggested options.
If you create a robots.txt file from scratch, you can personalize the file in the following ways:
- By configuring directives for crawling permissions.
- By specifying specific pages and files through the path parameter.
- By determining which bots should adhere to these directives.
Alternatively, pre-existing robots.txt templates, including widely used general and CMS directives, can be selected. It is also possible to include a sitemap within the file. This tool saves time by providing a ready-made robots.txt file for download.
Document title and size
The robots.txt file should be named exactly as mentioned, without the use of capital letters. According to the Google guidelines, the file size should not exceed 500 KiB. Content that appears after this limit will be ignored by the search engines.
Where to place the file
The robots.txt file must be located at the root directory of the website host and can be accessed via FTP. Before making any changes, it is recommended to download the original robots.txt file in its original form.
How to check your robots.txt file
Errors in the robots.txt file can lead to important pages not appearing in the search index or render the entire site invisible to search engines. Conversely, unwanted pages that should be private might also get indexed.
You can easily check your Robots.txt file with SE Ranking’s free Robots.txt Tester. Simply enter up to 100 URLs to test and verify if they are allowed for scanning.
Alternatively, you can access a robots.txt report within Google Search Console. To do this, go to Settings > Crawling > robots.txt.

Opening a robots.txt report reveals the robots.txt files Google found for the top 20 hosts on your site, when it last checked them, the fetch status, and any problems found. You can also use this report to ask Google to recrawl a robots.txt file quickly if the need to do so is urgent.

Common robots.txt issues
While you’re managing your website’s robots.txt file, several issues can impact how search engine crawlers interact with your site. Some common issues include:
- Format mismatch: Web crawlers can’t detect and analyze the file if it is not created in .txt format.
- Wrong placement: Your robots.txt file should be located in the root directory. If it is located, for instance, in a subfolder, search bots may fail to find and access it.
- Misusing “/” in the Disallow directive: A Disallow directive without any content implies that bots have permission to visit any pages on your website. A Disallow directive with “/” closes your website from bots. It’s always better to double-check your robots.txt file to ensure the Disallow directives accurately reflect your intentions.
- Blank lines in the robots.txt file: Ensure there are no blank lines between directives. Otherwise, web crawlers might have difficulty parsing the file. The only case where blank links are allowed is before indicating a new User-agent.
- Blocking a page in robots.txt and adding a “noindex” directive: This creates conflicting signals. Search engines may not understand the intent or ignore the “noindex” instruction altogether. It’s best to use either robots.txt to block crawling or “noindex” to prevent indexing, but not both simultaneously.
Additional tools/reports to check for issues
There are many ways to check your website for possible robots.txt file-related issues. Let’s review the most widely used ones.
1. Google Search Console Pages report.
The Pages section of GSC contains valuable information about your robots.txt file.
To check if your website’s robots.txt file is blocking Googlebot from crawling a page, follow these steps:
- Access the Pages section and navigate to the Not Indexed category.

- Look for the error labeled Blocked by robots.txt and select it.

- Clicking on this section will show you a list of pages currently blocked by your website’s robots.txt file. Make sure these are the intended blocked pages.

Also, check if you have the following issue in this section: Indexed, though blocked by robots.txt.

You can also check if individual URLs are indexed by pasting them into the search box in Google Search Console’s URL Inspection tool. This can help you detect potential indexing issues caused by conflicting directives or misconfigured robots.txt rules.
Here’s a complete Google Search Console guide on detecting and addressing indexing-related problems.
2. SE Ranking’s Website Audit
SE Ranking’s Website Audit tool (and others like it) provides a comprehensive overview of your robots.txt file, including information about pages that are blocked by the file. It can also help you check indexing and XML sitemap-related issues.
To gain valuable insights into your robots.txt file, start by exploring the Issue Report generated by the tool. Among the over 120 metrics analyzed, you’ll find the Blocked by robots.txt parameter under the Crawling section. Clicking on it will display a list of webpages blocked from crawling, along with issue descriptions and quick fix tips.
This tool also makes it easy to identify whether you have added a link to the sitemap file in the robots.txt file. Simply check the XML sitemap not found in robots.txt file status under the same section.

When navigating to the Crawled Pages tab on the left-hand menu, you can analyze the tech parameters of each page individually. Apply filters to focus on solving critical issues on the most important pages. For example, applying the filter Blocked by robots.txt > Yes will show all pages blocked by the file.

3. SE Ranking’s Robots.txt Generator and Robots.txt Tester
SE Ranking’s Robots.txt Generator makes it easy to create the file without risking a typo interfering with your intentions. To create robots.txt manually, add paths that you want to allow or disallow, specify the bots this ruleset should apply to, and add your sitemap. You can also add all image and file formats to the rule.

You can make this process even faster by using one of the robots.txt presets. Use ready-made robots.txt files for most popular CMS platforms or add popular rulesets like disallowing everything to the most blocked bots.

You can add custom rules to these files later.
If you want to test your robots.txt file, use SE Ranking Robots.txt Tester. Type in your website, and it will show you the file and check it for inconsistancies. You can also use it to check the directives for a specific website URL on the site. The tool will indicate whether it’s allowed or not for a chosen User-agent.
SEO best practices
To ensure web crawlers index your website’s content accurately and that it performs well, follow these SEO best practices:
- Ensure correct case usage in robots.txt: Web crawlers interpret folder and section names with case sensitivity, so using appropriate case usage is crucial to avoid confusion and ensure accurate crawling and indexing.
- Begin each directive on a new line, with only one parameter per line.
- Avoid using spaces, quotation marks, or semicolons when writing directives.
- Use the Disallow directive to block all files within a specific folder or directory from crawling. This technique is more efficient than listing each file separately.
- Employ wildcard characters for more flexible instructions when creating the robots.txt file. The asterisk (*) signifies any variation in value, while the dollar sign ($) acts as a restriction and signifies the end of the URL path.
- Create a separate robots.txt file for each domain. This establishes crawl guidelines for different sites individually.
- Always test a robots.txt file to make sure that important URLs are not blocked by it.
Conclusion
We’ve covered all important aspects of the robots.txt file, from its syntax to best practices to common issues. Now you know why a well-configured robots.txt file is crucial for effective SEO and website management. It optimizes crawl budgets, guides search engines to important content, and protects sensitive areas.
Remember to regularly review and update your robots.txt file as your website evolves. Use the tools and techniques we’ve discussed to ensure your file works as intended.

