The SEO guide to finding all web pages of a website
In the SEO world, data drives informed decisions and effective strategies. To succeed, you should focus on two things: market awareness and a thorough understanding of your site.
This article focuses on the second: knowing your site inside and out, as the most important issues and growth opportunities often lie in pages you might overlook.
Let me walk you through some possible reasons why you might need to find all the pages of a website, which tools will help you do this effectively, and exactly how.
-
SE Ranking’s Website Audit:
This tool crawls your site, gathering all URLs that search engines can index. It allows customization for scanning specific site sections and provides metrics like errors, URL structure, and indexing status.
-
Google Search Console:
GSC shows all pages Google has indexed on your site, including those not indexed due to errors. You can export data to track and improve your site’s visibility.
-
Google Analytics:
It records all pages visited by users, offering insights into pages that might be overlooked but are still valuable for SEO or marketing.
-
Bing Webmaster Tools:
This tool reveals all pages indexed by Bing, offering an alternative to Google’s indexing and helping optimize your site for different search engines.
-
Command line:
Using tools like Wget, you can download and list all URLs from a site, including those deep within the site’s structure.
-
Sitemap:
By accessing the sitemap.xml file, you can find all pages a site owner wants indexed.
-
WordPress plugins:
Plugins like List all URLs and Export All URLs simplify the process of extracting all site pages, especially for WordPress users.
Why do I need to find every single page?
Search engines regularly update algorithms and apply manual penalties to pages and sites. So not knowing all your website’s pages puts you at risk.
To avoid major setbacks, you should monitor every page on your site. This will also help you find forgotten or hidden pages you wouldn’t otherwise spot.
There are several possible scenarios when finding all web pages on a site becomes essential:
- Changing website architecture
- Moving to a new domain or changing the URL structure
- Finding orphan pages
- Finding duplicate pages
- Finding 404 pages
- Creating redirects
- Creating a website hreflang file
- Checking for canonical and noindex tags
- Setting up internal linking
- Creating an XML sitemap or robots.txt file
How to find all pages of a website
Now, when it comes down to finding all the web pages that belong to a single website, the following options are available:
- Use SE Ranking’s Website Audit to find all crawlable web pages.
- Use Google Search Console to discover pages that are only visible to Google.
- Use Google Analytics to detect all pages that have ever been visited.
- Use Bing Webmaster tools to catch pages that are only visible to Bing.
- Download the website pages list using command line commands.
- Extract website URLs from Sitemap.xml.
- View all pages of a website via WordPress and other plugins.
Let’s explore how to use these tools to scan a website for all pages.
Finding crawlable pages via SE Ranking’s Website Audit
Let’s start by collecting all the URLs that both people and search engine crawlers can visit by following your site’s internal links. Analyzing such pages should be your top priority as they get the most attention.
To do this, access SE Ranking, open the Website Audit tool and press the New Audit button to start.

Alternatively, you can set up automatic website audits in the advanced settings during project setup.

Note: The 14-day free trial gives you access to all of SE Ranking’s available tools and features, including Website Audit.
Next, let’s configure the settings to make sure we’re telling the crawler to go through the right pages. To access Website Audit settings, click on the Gear icon in the top right-hand corner:

Under settings, go to the Source of pages for website audit tab, and enable the system to scan Site pages, Subdomains, XML sitemap to verify that we’re only scanning what’s been clearly specified, and are including the site’s subdomains along with all their pages:

Then, go to Rules for scanning pages, and enable the Take into account the robots.txt directives option to tell the system to follow the instructions specified in the robots.txt file. Click ‘Apply Changes’ when you’re done:

If you have a JS-based website, go to the Parser settings and enable JavaScript Rendering to ensure the tool scans dynamically loaded content on your site.

You can also enable this when initiating a new audit in the Website Audit wizard.

Also note we now offer Website Audit 2.0 you can switch to in the Report Setup section if you have older audit versions. This update includes:
- Improved Health Score calculation that considers both error severity and number of affected pages
- New integrated checks with dedicated categories for Crawling & Indexing, Sitemaps, Meta tags, Content, Speed and Performance, Links, and more
- Updated analysis algorithms that better prioritize issues based on their actual impact on your website performance and overall health score

Now, go back to Overview tab and launch the audit with the new settings applied by hitting ‘Restart audit’:

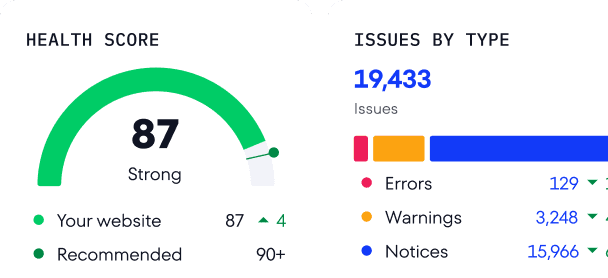
Once the audit is complete, go to Crawled Pages to view the full list of all crawlable pages:

Together with a list of all URLs found, you’ll see all of the site’s essential SEO metrics, including:
- Referring pages: the number of pages on your website that link to the specific URL.
- Number of technical issues on each page.
- Total traffic for each page.
- Total number of keywords each page ranks for.
- Indexability status.
- Number of characters in the page’s URL.
- Type and version of URL protocol.
- Whether the page is in the sitemap.
- Server response code on the page.
- Whether the page is blocked by robots.txt.
- And more.
The above metrics will appear as default columns in the Crawled Pages tab. However, you can customize the report to meet your specific requirements by adding other parameters. Simply go to the Columns section above the table on the right and enable or disable any metric as desired.

Crawled pages can be sorted by the errors, warnings, and notices that they contain. This will enable you to prioritize pages when fixing issues. You can also compare reports once you have audited your website at least twice. This helps you observe the changes in your crawled pages over time.

It’s also possible to use filters to sort out pages by different parameters. For instance, if you only want to see 200-status-code pages, as in those that are working correctly, add a filter like so:
Now it’s time to export the results. Go to Export and choose to save the data either in .xls or .csv format.

Finding all pages via Google Search Console
Another tool that you can use to find all pages on a website is Google Search Console. Keep in mind, however, that GSC will only show you pages that Google can access.
Start by opening up your account and going to the Indexing tab. Choose the Pages report and select ‘All known pages’ instead of ‘All submitted pages’.

The green box labeled “Indexed” will give you the number of URLs indexed by Google. Click on ‘View data about indexed pages’ below the graph. From here, you can find all URLs on a domain that Google indexed, as well as the date of their last crawl. You can export them in Google Sheets or download them as .xls or .csv files.

Now, let’s go back to check the Not Indexed pages (pages that were not indexed and won’t appear in Google). Get ready to roll up your sleeves and do a lot of manual work.
As you scroll down, you’ll see a list of reasons why some of the pages on your website aren’t indexed.

You can view different categories, such as redirect errors, pages excluded by ‘noindex’ tag, those blocked by robots.txt, and so on.
By clicking on the error category, you’ll see a list of affected pages. Going through each one of them will give you unfiltered access to every single page that Google has discovered on your site.

Another useful report in GSC for finding all website pages is the Search Results report. This report displays all pages that have received at least one impression in search results. To access it, go to Search Results in the Performance tab, set up the largest possible period, and choose Pages. Finally, export your report.

You can also use the Search Analytics for Sheets add-on to retrieve data from GSC on demand and create automatic backups in Google Sheets.
Finding all pages with pageviews via Google Analytics
You can also find all website pages by carefully studying the data in your Google Analytics account. There is only one condition: your website must be linked to your Google Analytics account from the get-go, so that it can collect data behind the scenes.
The logic here is simple: if someone has ever visited any page of your website, Google Analytics will have the data to prove it. And since these visits are made by people, we should ensure such pages serve a distinct SEO or marketing purpose.
Start by going to Reports → Engagement → Pages and Screens and click on Page path and screen class.

You can also click on ‘Views’ to get the arrow pointing up and sort the page URLs from least to most pageviews. Ultimately, the least visited pages will be seen at the top of the list.
Then, share or export the data into a .csv file.
Finding all website pages by using Bing Webmaster Tools
Google is considered a search giant, but Bing is still the second most popular search engine to date. As of January 2025, its global search market is 4.04%, making properly optimizing your website for Bing a smart strategy.
You can also make use of Bing Webmaster Tools to find all pages on a website that are indexed by Bing. The process is straightforward, but before getting started, make sure that you have added and verified your website.
Once your site is set up, go to Site Explorer in the left-hand navigation bar and choose to filter by ‘All URLs’. The report will display all the pages that Bing sees on your site. Click on the Download button to export the data.

Finding all pages on a website using the command line
A more techie approach to finding the list of all pages on a website is to use the command line. This method involves interacting with a computer through text commands.
To get all URLs from a website via the command line, you’ll first need to install Wget. This command line tool allows you to retrieve files from the web. The installation process varies depending on the OS you’re using. For instance, macOS requires that you install the Homebrew package manager first before installing command line tools like Wget.
To install Wget, open a terminal window and type in the following command:
brew install wget
Next, download your website. Enter:
wget -r www.examplesite.com
Wget will download your website recursively. It will start with the main page of the website and all its linked pages, images, and other files. From there, it will follow the links on those pages and download the pages they link to, and will continue this process until it has downloaded the entire website.
Once the website is downloaded, you can ask Wget to list out the URLs by typing:
find www.examplesite.com
Finding all website pages via Sitemap.xml
XML sitemap is also a great way to find all pages on a website because it provides a list of all the pages on it that the owner wants search engines to index. It works like a roadmap, guiding search engine bots through the site’s structure and making it easier for them to understand how everything is organized.
The get the list, follow these steps:
- Locate your sitemap.
The sitemap can usually be found in the website’s root directory or by typing “/sitemap.xml” at the end of the website’s URL, like in http://sitename.com/sitemap.xml. If the website has multiple sitemaps, they will be listed in the main sitemap file, which is typically named sitemap-index.xml. Here, you can find a list of sitemaps and choose the most relevant one to get a list of the website’s pages.
- Extract URLs from your sitemap into Google Sheets.
Though this is another tech-heavy method, it will save you tons of time and effort by importing all URLs into Google Sheets in just a few seconds. However, you will need to do some preparatory work first. Begin by creating a new sheet and then go to Extensions. Next, choose ‘Apps Script’.

Now you’ll need to copy and paste the following custom JavaScript code into script editor to create a new function:
function sitemap(sitemapUrl,namespace) {
try {
var xml = UrlFetchApp.fetch(sitemapUrl).getContentText();
var document = XmlService.parse(xml);
var root = document.getRootElement()
var sitemapNameSpace = XmlService.getNamespace(namespace);
var urls = root.getChildren('url', sitemapNameSpace)
var locs = []
for (var i=0;i <urls.length;i++) {
locs.push(urls[i].getChild('loc', sitemapNameSpace).getText())
}
return locs
} catch (e) {
return e
}
}

From here, save and run the test. The editor will ask for access permission. If the script is implemented successfully, no error messages will appear Instead, you’ll see that the execution has started and completed.

Now you can get back to your Google Sheet and enter the following formula:
=sitemap("Sitemap Url","Namespace Url")
Once you have located your sitemap, you should have the sitemap URL at hand, from which you can directly copy the Namespace URL. In the screenshot below, you can see how this works with SE Ranking’s sitemap:
- Sitemap URL is in the browser address bar.
- Namespace URL is in the first line of sitemap content.

Copy these addresses and paste them as links into the formula. This is what you should get in the end:
=sitemap("https://seranking.com/sitemap.xml","http://www.google.com/schemas/sitemap/0.9")
Paste this formula into your Google Sheet, and press Enter to get all the URLs extracted from your sitemap.

Finding all website pages via WordPress plugins
If your website runs on WordPress, there are plugins that can help you find all of its pages. The two most commonly used options are:
To use these plugins, download and install them to your ‘/wp-content/plugins/’ directory. Once installed, activate them from your Plugins page in WordPress. Once you’ve completed the activation, you can list or export all URLs of your website.
If you use a different CMS, check whether it has built-in plugins for this purpose or has a separate one in the extension directory. For instance, Joomla has many plugins for generating sitemaps to help you get a list of website pages. Similarly, Drupal has a sitemap module that can come in handy when collecting the pages on your site.
How to see all pages of a website on Google
We have discussed various tools that can help you find all the pages on your website, but we’ve saved the simplest option for last—and for good reason. While this method is the easiest, you must be careful when using it.
Google your site, but do it right. This means using Google search operators, which are special commands that refine the search based on set criteria.
Simply go to Google Search and type “site:website name” like in “site:seranking.com”. You won’t need to add http:// or www, but make sure there are no spaces between the operator and query; otherwise, the results will be incorrect.

Still, you must consider that this command wasn’t created to display all indexed pages on your site, to which Google’s John Mueller confirmed.

One last tip is to use Google Search Console, but in a slightly different way than was explained in previous sections. Focus on the page’s impressions (the number of times the page was shown in search) but for a short period of time; like seven days, for instance.
Closing thoughts
Locating all of your website’s pages is crucial to improving its SEO and serves as the initial step towards further optimization activities. With this data, you can identify pages requiring improvement, update outdated content, find all website links and fix broken ones, and optimize your overall internal linking structure.
By using the tools and methods described in this article, you can quickly uncover all of the pages on your website and gain valuable insights into its performance. So, take a brief moment to compile a page list to stay on top of your SEO and marketing efforts. Take it from the SE Ranking team: it won’t take much time at all when you’re using our tools.

