¿Qué es el archivo robots.txt, para qué sirve y cómo configurarlo correctamente?
¿Alguna vez te has preguntado cómo los sitios web controlan qué áreas están fuera del alcance de los motores de búsqueda? La respuesta está en un archivo pequeño pero influyente llamado «robots.txt».
Puedes usarlo para comunicarte con los robots de búsqueda que rastrean tu sitio web. Pero deberías conocer detalles de su lenguaje y de cómo abordan este archivo para poder usarlo correctamente.
En este artículo, profundizaremos en los detalles sobre lo qué es el robots.txt, cómo configurarlo y cómo verificar si el archivo está funcionando correctamente. Además, te brindaremos guías generales para el contenido de un archivo robots.txt.
¡Comencemos!
-
El archivo robots.txt sirve como guía para los robots, informándoles qué páginas deben rastrearse y cuáles no. Sin embargo, un robot puede no obedecer.
-
El archivo robots.txt no puede evitar directamente la indexación, pero puede influir en la decisión de un robot de rastrear o ignorar ciertos documentos o archivos.
-
Si bien robots.txt, meta robots y x-robots dan instrucciones a los robots de los motores de búsqueda, difieren en su aplicación: robots.txt controla el rastreo, las etiquetas meta robots funcionan a nivel de página y la etiqueta X-Robots ofrece mayor control sobre la indexación.
-
Ocultar contenido inútil del sitio web con la directiva disallow ahorra el presupuesto de rastreo y evita que aparezca contenido no deseado en los resultados de búsqueda.
-
Seguir las reglas de sintaxis garantiza que los robots de búsqueda puedan leer y comprender correctamente tu archivo robots.txt.
-
Es posible crear un archivo robots.txt con editores de texto que admitan la codificación UTF-8 o mediante herramientas integradas en plataformas CMS populares como WordPress, Magento y Shopify.
-
Comprueba tu archivo robots.txt con herramientas como Google Search Console o plataformas SEO como SE Ranking. Esto te ayuda a identificar posibles problemas y garantiza que el archivo funcione como se espera.
-
Los problemas comunes incluyen discrepancias en el formato, ubicación incorrecta de archivos, uso incorrecto de directivas e instrucciones conflictivas.
-
Ten en cuenta que las directivas robots.txt distinguen entre mayúsculas y minúsculas. Además, asegúrate de que cada instrucción se ubique una por línea, utiliza comodines para mayor flexibilidad, crea archivos separados para diferentes dominios y prueba tu sitio web después de actualizar robots.txt para asegurarte de que las URL importantes no sean bloqueadas accidentalmente.
¿Qué es un archivo robots.txt?
Un archivo robots.txt es un documento de texto ubicado en el directorio raíz de un sitio web. La información que contiene está destinada específicamente a los rastreadores o crawlers de los motores de búsqueda.
Este archivo les indica qué URL, incluidas páginas, archivos, carpetas, etc., deben ser rastreadas y cuáles no. Si bien, la presencia de este archivo no es obligatoria para que un sitio web funcione, debe configurarse correctamente para mantener un SEO adecuado.
La decisión de utilizar robots.txt se tomó en 1994 como parte del Estándar de Exclusión de Robots.
Según Google Search Central, el propósito principal de este archivo no es ocultar páginas web de los resultados de búsqueda, sino limitar la cantidad de solicitudes que realizan los robots a los sitios y reducir la carga del servidor.
En términos generales, el contenido del archivo robots.txt debe considerarse como una recomendación para los rastreadores de búsqueda que define las reglas para el rastreo de sitios web.
Para acceder al contenido del archivo robots.txt de un sitio web, simplemente escribe “/robots.txt” después del nombre de dominio en el navegador.
¿Cómo funciona el archivo robots.txt?
En primer lugar, es importante tener en cuenta que los motores de búsqueda necesitan rastrear e indexar resultados de búsqueda específicos que se muestran en las SERP.
Para realizar esta tarea, los rastreadores web exploran sistemáticamente la web y recopilan datos de cada página web que encuentran. El término «spidering» se utiliza ocasionalmente para describir esta actividad de rastreo.
Cuando los rastreadores llegan a un sitio web, revisan el archivo robots.txt, que contiene instrucciones sobre cómo rastrear e indexar las páginas del sitio web.
Si el sitio web no tiene un archivo robots.txt o no incluye ninguna directiva que prohíba la actividad del user-agent, los robots de búsqueda continuarán rastreando el sitio hasta que alcance el presupuesto de rastreo u otras restricciones.
¿Qué es llms.txt y lo necesitas para los bots de IA?
Llms.txt es un estándar propuesto cuyo objetivo es guiar a los rastreadores de IA hacia una mejor comprensión de tu sitio web.
A diferencia del robots.txt, que indica a los rastreadores qué páginas ignorar, llms.txt enumera las páginas importantes y las describe en lenguaje natural para los crawlers de IA. Algo así como un sitemap mejorado.

Aunque la propuesta lleva un tiempo dando vueltas y algunos motores de IA han mostrado interés, no hay señales de que se esté aplicando de forma real. Según un estudio de SE Ranking sobre el tema, llms.txt no influye en la visibilidad ni en el número de citaciones en búsquedas con IA.
La mayoría de funciones que llms.txt intenta estandarizar ya las cubre el sitemap o el marcado Schema. El resto son irrelevantes porque la IA puede entender el contexto por sí sola. ¿Lo necesitas? Hoy por hoy, no.
¿Para qué sirve el archivo robots.txt?
Hay dos motivos principales por los que el archivo robots.txt es una práctica importante de SEO: gestionar el rastreo y optimizar el presupuesto de rastreo.
Gestionar el rastreo (incluidos los bots de IA)
La función principal del archivo robots.txt es evitar el escaneo de páginas y archivos de recursos que quieres mantener fuera del alcance de los rastreadores.
Hablamos de paneles de administración, contenido duplicado, páginas en desarrollo y páginas con parámetros de consulta como filtros o resultados de búsqueda interna.
Nota: el uso de la directiva «robots.txt disallow» no garantiza que una página web en particular no sea rastreada o que se excluya de los resultados de búsqueda. Google se reserva el derecho de considerar varios factores externos, como los enlaces entrantes, al determinar la relevancia de una página web y su inclusión en los resultados de búsqueda. Para evitar explícitamente que una página sea indexada, se recomienda utilizar la meta etiqueta robots «noindex» o el encabezado HTTP X-Robots-Tag. También se puede utilizar la protección con contraseña para evitar la indexación.
Las directivas de robots.txt también las respetan la mayoría de motores de IA populares, como Gemini, Perplexity y ChatGPT. Si quieres impedir el acceso a tu sitio web a alguna herramienta de IA concreta, añade la directiva correspondiente para su User-agent.
Existen cientos de nombres de User-agent de IA, y la mayoría de herramientas distinguen entre bots usados para entrenamiento, indexación y búsquedas iniciadas por el usuario.
Los bots de entrenamiento buscan contenido con el que el modelo pueda aprender, los de búsqueda e indexación crean índices internos y los iniciados por el usuario recuperan contenido fresco bajo demanda cuando no está en el índice.
Aquí tienes algunos ejemplos:
Bots de búsqueda e indexación (construyen índices para la búsqueda con IA):
- OAI-Searchbot
- Claude-SearchBot
- PerplexityBot
Bots iniciados por el usuario (recuperan contenido cuando un usuario hace una pregunta):
- ChatGPT-User
- Claude-User
- Perplexity-User
- Applebot
Nota: algunos de estos bots iniciados por el usuario también pueden usarse para entrenamiento.
Bots de entrenamiento (recopilan datos para entrenar modelos de IA):
- Meta-ExternalAgent
- Google-Extended
- GPTBot
- ClaudeBot
- Applebot-Extended
Todas las plataformas de IA recomiendan permitir el acceso de los bots de búsqueda e indexación para que la visibilidad en IA no se vea afectada. Sin embargo, el comportamiento del resto de rastreadores varía. Y entre plataformas también hay diferencias.
Por ejemplo, bloquear el rastreador de indexación de OpenAI (OAI-Searchbot) impedirá que tu sitio web aparezca en los resultados de búsqueda, pero todavía podrá referenciarse en enlaces de navegación.
El bot de indexación de Perplexity también dejará de rastrear los sitios que lo deshabiliten, pero indexará el dominio y mostrará un resumen breve.
La mayoría de bots de entrenamiento obedece estrictamente las directivas de robots.txt, aunque algunos bots iniciados por el usuario, como ChatGPT-User, pueden ignorarlas.
Si quieres ir más allá del control que ofrece robots.txt y monitorizar cómo te está viendo la búsqueda con IA, el AI Search Toolkit permite rastrear tu visibilidad en AI Overviews, AI Mode, ChatGPT, Gemini y Perplexity desde un único panel.
Optimiza el presupuesto de rastreo
El presupuesto de rastreo se refiere a la cantidad de páginas de un sitio web que un robot de búsqueda dedica a rastrear.
Para utilizar el presupuesto de rastreo de manera más eficiente, los robots de búsqueda deben dirigirse solo al contenido más importante de los sitios web y bloquear el acceso a información que no sea útil.
Optimizar el presupuesto de rastreo ayuda a los motores de búsqueda a asignar sus recursos limitados de manera eficiente, lo que resulta en una indexación más rápida de contenido nuevo y una mejor visibilidad en los resultados de búsqueda.
Sin embargo, es importante tener en cuenta que si tu sitio web tiene más páginas de las que permite tu presupuesto de rastreo asignado, es posible que algunas páginas se queden sin rastrear y, en consecuencia, sin ser indexadas.
Las páginas no indexadas no pueden aparecer en ninguna parte de la SERP.
En la mayoría de casos, conviene optimizar el uso del presupuesto de rastreo si tu web es grande (miles de páginas), si es de tamaño medio pero con contenido que cambia muy a menudo, o si tienes un porcentaje significativo de páginas no indexadas.
La optimización garantizará que los motores de búsqueda cubran por completo todas tus páginas importantes.
Consideremos un escenario en el que tu sitio web tiene mucho contenido trivial en comparación con el de tus páginas principales. En casos como estos, puedes optimizar tu presupuesto de rastreo excluyendo recursos no deseados de la lista de «para visitar» del rastreador de búsqueda.
Por ejemplo, puedes usar la directiva «Disallow» seguida de una extensión de archivo específica, como «Disallow:/*.pdf», para evitar que los motores de búsqueda rastreen e indexen cualquier recurso PDF en tu sitio web.
Esto proporciona una forma eficaz de ocultar dichos recursos y garantizar que no se incluyan en los resultados de los motores de búsqueda.
Otro beneficio común de usar robots.txt es su capacidad para solucionar problemas de rastreo de contenido en tu servidor, si es que los hay.
Por ejemplo, si tienes una cantidad infinita de scripts de calendario que pueden causar problemas cuando los robots acceden a ellos con frecuencia, puedes deshabilitar el rastreo de ese script a través del archivo robots.txt.
Quizás te preguntes si es mejor usar robots.txt para bloquear enlaces de afiliados para administrar el presupuesto de rastreo de tu sitio web o utilizar la etiqueta noindex para evitar que los motores de búsqueda indexen esos enlaces.
La respuesta es simple: Google es bueno para identificar y descartar enlaces de afiliados por sí solo, especialmente si están marcados correctamente. Al usar robots.txt para deshabilitarlos, tienes mayor control y potencialmente conservas el presupuesto de rastreo de manera más efectiva.
Ejemplo de robots.txt
Tener una plantilla con directivas actualizadas puede ayudarte a crear un archivo robots.txt con el formato correcto, especificando los robots necesarios y restringiendo el acceso a los archivos relevantes.
User-agent: [nombre del bot]
Disallow: /[ruta al archivo o carpeta]/
Disallow: /[ruta al archivo o carpeta]/
Disallow: /[ruta al archivo o carpeta]/
Sitemap: [URL del sitemap]
Ahora, veamos algunos ejemplos de cómo se vería un archivo robots.txt.
1. Permitir que todos los robots web accedan a todo el contenido.
A continuación, verás un ejemplo básico del código de un archivo robots.txt que otorga a todos los rastreadores web acceso a todos los sitios web:
User-agent: *
Crawl-delay: 10
# Sitemaps
Sitemap: https://www.usa.gov/sitemap.xml
En este ejemplo, la directiva «User-agent» utiliza un asterisco (*) para aplicar las instrucciones a todos los rastreadores web. La directiva «Allow: /» otorga acceso libre a todo el sitio.
La declaración del sitemap no restringe ningún acceso, pero dirige a los rastreadores al mapa del sitio. Las líneas que comienzan con el símbolo «#» son comentarios que los rastreadores ignoran.
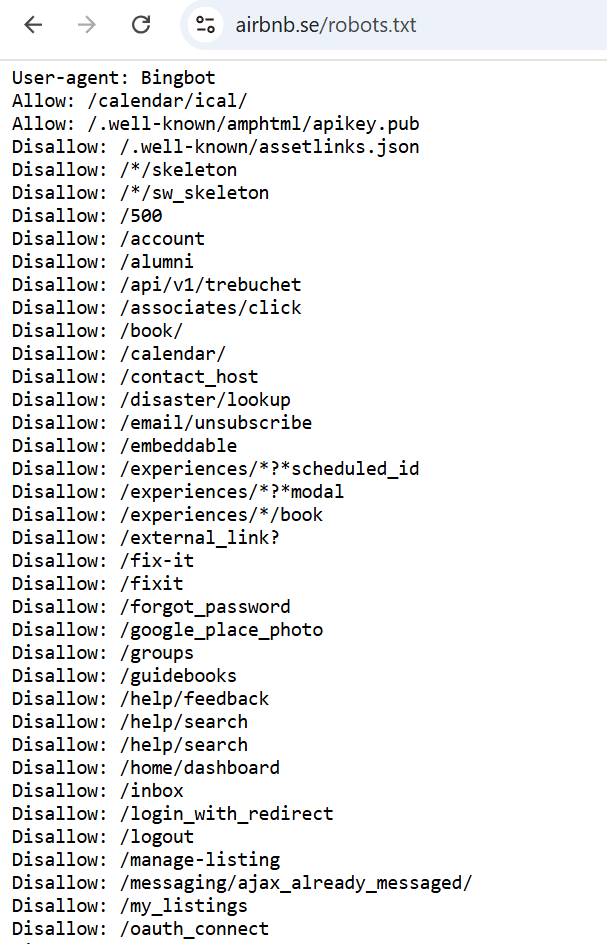
2. Bloqueo de un rastreador web específico para una página web específica.
El siguiente ejemplo especifica los permisos de acceso para el user-agent «Bingbot», que es el rastreador web que utiliza el motor de búsqueda de Microsoft, Bing.
Incluye una lista de directorios del sitio web que están cerrados para su escaneo, así como algunos directorios y páginas a los que se puede acceder en el sitio web.
3. Bloquear a todos los rastreadores web de todo el contenido.
User-agent: *
Disallow: /
En este ejemplo, la directiva «User-agent» también se aplica a todos los rastreadores web. Sin embargo, la directiva «Disallow» utiliza una barra diagonal (/) como valor, lo que indica que se debe bloquear el acceso a todo el contenido del sitio web para cualquier rastreador web.
Esto indica a todos los robots que no rastreen ninguna página del sitio.
Ten en cuenta que bloquear a todos los rastreadores web para que no accedan al contenido de un sitio web mediante el archivo robots.txt es una medida extrema y no se recomienda en la mayoría de los casos.
Puede que solo sea útil cuando tu sitio web está en desarrollo y no está listo para los motores de búsqueda.
En otras situaciones, los sitios web suelen utilizar el archivo robots.txt para controlar el acceso a partes específicas de tu sitio web, como bloquear ciertos directorios o archivos, en lugar de bloquear todo el contenido.
4. Dar instrucciones a los bots de IA
El archivo robots.txt también sirve para dirigirse a los rastreadores de IA. Aquí tienes un ejemplo de un conjunto de directivas que permite el rastreo de toda la web y bloquea subdirectorios específicos.

Bloquear toda la web no es recomendable, ya que puede afectar a tu visibilidad en IA.
Perplexity recomienda permitir su crawler de búsqueda, PerplexityBot, y su bot iniciado por el usuario, Perplexity-User, para garantizar la visibilidad en IA, ya que ninguno se usa para entrenamiento. OpenAI recomienda permitir OAI-SearchBot para visibilidad en IA, ya que solo GPTBot se usa para entrenar el modelo.
Ten en cuenta que no existe un único nombre de user-agent para todos los rastreadores de IA. Si quieres darles directivas concretas, tendrás que referenciar cada user-agent por separado.
Cómo encontrar el archivo robots.txt
Para encontrar el archivo robots.txt de un sitio web, existen un par de métodos que puedes utilizar:
Para encontrar el archivo robots.txt, añade «/robots.txt» al nombre de dominio del sitio web que quieres examinar.
Por ejemplo, si el dominio del sitio web es «example.com», debes ingresar «example.com/robots.txt» en la barra de direcciones de tu navegador web. Esto te llevará directamente al archivo robots.txt si el sitio web lo tiene.
Otro método menos utilizado, pero aún común para los usuarios de CMS, es buscar y editar archivos robots.txt directamente dentro del sistema. Veamos algunos de los más populares.
Un archivo robots.txt en WordPress
Para encontrar y modificar un archivo robots.txt en WordPress, puedes crear uno manualmente o usar un plugin.
Para crear uno manualmente:
- Crea un archivo de texto llamado «robots.txt»
- Súbelo a tu directorio raíz a través de un cliente FTP
Usando el plugin de Yoast SEO:
- Ve a Yoast SEO > Herramientas
- Haz clic en Editor de archivos (asegúrate de tener habilitada la edición de archivos)
- Haz clic en el botón Crear archivo robots.txt
- Ve o edita el archivo robots.txt allí
Usando el plugin All in One SEO:
- Ve a All in One SEO > Herramientas
- Haz clic en el Editor de robots.txt
- Haz clic en el interruptor para habilitar Robots.txt personalizado.
- Ve o edita el archivo robots.txt allí
Un archivo robots.txt en Magento
Magento genera automáticamente un archivo robots.txt predeterminado.
Para editar:
- Inicia sesión en el panel de administración de Magento
- Ve a Contenido > Diseño > Configuración
- Haz clic en Editar para el sitio web principal
- Amplía la sección Robots de motores de búsqueda
- Edita el contenido en el campo Editar instrucción personalizada del archivo robots.txt
- Guarda la configuración
Un archivo robots.txt en Shopify
Shopify genera automáticamente un archivo robots.txt predeterminado.
Para editar:
- Inicia sesión en tu panel de administración de Shopify
- Haz clic en Configuración > Aplicaciones y canales de venta
- Ve a Tienda online > Temas
- Haz clic en el botón … junto a tu tema actual y selecciona Editar código
- Haz clic en Agregar una nueva plantilla > robots
- Haz clic en Crear plantilla
- Edita el contenido según sea necesario
- Guarda los cambios
Cómo encuentran los motores de búsqueda tu archivo robots.txt
Los motores de búsqueda tienen mecanismos específicos para descubrir y acceder al archivo robots.txt de tu sitio web. Así es como lo encuentran normalmente:
1. Visitando un sitio web: los rastreadores de búsqueda recorren continuamente la web, visitando sitios web y siguiendo enlaces para descubrir páginas web nuevas.
2. Solicitando robots.txt: cuando un rastreador de un motor de búsqueda accede a un sitio web, busca la presencia de un archivo robots.txt agregando «/robots.txt» al dominio del sitio web.
Nota: después de cargar y probar correctamente tu archivo robots.txt, los rastreadores de Google lo detectarán automáticamente y comenzarán a seguir sus instrucciones. No es necesario realizar ninguna otra acción. Sin embargo, si has realizado modificaciones en tu archivo robots.txt y quieres actualizar rápidamente la versión en caché de Google, deberás aprender a enviar un archivo robots.txt actualizado.
3. Análisis de robots.txt: si existe un archivo robots.txt en la ubicación solicitada, el rastreador descargará y analizará el archivo para determinar las directivas de rastreo.
4. Seguimiento de instrucciones: después de obtener el archivo robots.txt, el rastreador del motor de búsqueda sigue las instrucciones que se describen en él.
Robots.txt vs meta robots vs x-robots
Si bien el archivo robots.txt, la meta etiqueta robots y la etiqueta X-Robots-Tag tienen propósitos similares en términos de dar instrucciones a los robots araña de los motores de búsqueda, difieren en su aplicación y área de control.
Cuando se trata de ocultar el contenido del sitio web de los resultados de búsqueda, confiar únicamente en el archivo robots.txt puede no ser suficiente.
Como se mencionó anteriormente, el archivo robots.txt es principalmente una recomendación para los rastreadores web. Les informa sobre las áreas de un sitio web a las que pueden acceder.
Sin embargo, no garantiza que el contenido no sea indexado por los motores de búsqueda. Para evitar la indexación, los webmasters deben emplear métodos adicionales
Meta etiqueta robots
Una técnica eficaz es utilizar la meta etiqueta robots, que se coloca dentro de la sección <head> del código HTML de una página.
Al incluir una meta etiqueta con la directiva «noindex», le dices explícitamente a los robots de los motores de búsqueda que el contenido de la página no debe ser indexado.
Este método proporciona un control más preciso sobre páginas individuales y su estado de indexación en comparación con las directivas generales del archivo robots.txt.
A continuación, verás un fragmento de ejemplo para evitar la indexación de los motores de búsqueda a nivel de página:
<meta name=“robots” content=“noindex”>
De forma similar a lo que es robots.txt, esta meta etiqueta permite restringir el acceso a robots específicos. Por ejemplo, para restringir un bot específico (por ejemplo, Googlebot), utiliza:
<meta name="googlebot" content="noindex">
Etiqueta X-Robots
También puedes utilizar la etiqueta X-Robots en el archivo de configuración del sitio para limitar aún más la indexación de páginas.
Este método ofrece una capa adicional de control y flexibilidad con la gestión de la indexación a un nivel detallado.
Para obtener más información sobre este tema, lee nuestra guía completa sobre la meta etiqueta robots y la etiqueta X-Robots.
Páginas y archivos que normalmente deben ser bloqueadas usando robots.txt
1. Panel de administración y archivos del sistema.
Archivos internos y del servicio con los que solo los administradores del sitio web o webmasters deben interactuar.
2. Páginas auxiliares que sólo aparecen después de acciones específicas del usuario.
Páginas a las que se envía a los clientes después de completar con éxito un pedido, formularios, páginas de autorización o de recuperación de contraseña.
3. Páginas de búsqueda.
Las páginas que se muestran después de que un usuario ingresa una consulta en el cuadro de búsqueda de tu sitio web generalmente se cierran para los robots de búsqueda.
4. Páginas de filtro.
Los resultados que se muestran con un filtro aplicado (tamaño, color, fabricante, etc.) son páginas separadas y pueden ser consideradas como contenido duplicado.
Los expertos en SEO generalmente evitan que se rastreen a menos que dirijan tráfico para palabras clave de marca u otras consultas objetivo. Los sitios agregadores de noticias pueden ser una excepción.
5. Archivos de un formato determinado.
Archivos como fotos, videos, documentos .PDF, archivos .JS. Con la ayuda de robots.txt, puedes restringir el análisis de archivos individuales o de extensiones específicas.
Sintaxis de robots.txt
Los webmasters deben comprender la sintaxis y la estructura del archivo robots.txt para controlar la visibilidad de sus páginas web en los motores de búsqueda.
El archivo robots.txt normalmente contiene un conjunto de reglas que determinan a qué archivos de un dominio o subdominio pueden acceder los rastreadores.
Estas reglas pueden bloquear o permitir el acceso a rutas de archivo específicas. De forma predeterminada, si no se indica explícitamente en el archivo robots.txt, se supone que todos los archivos están permitidos para el rastreo.
El archivo robots.txt consta de grupos, cada uno de los cuales contiene varias reglas o directivas. Estas reglas se enumeran una en cada línea. Cada grupo comienza con una línea User-agent que especifica la audiencia objetivo para las reglas.
Un grupo proporciona la siguiente información:
- El user-agent al que se aplican las reglas.
- Los directorios o archivos a los que el user-agent puede acceder.
- Los directorios o archivos a los que el user-agent no puede acceder.
Al procesar el archivo robots.txt, los rastreadores siguen un enfoque de arriba a abajo. Un user-agent solo puede coincidir con un conjunto de reglas. Si hay varios grupos que tienen como objetivo el mismo user-agent, estos grupos se fusionan en un solo grupo antes de ser procesados.
A continuación, verás un ejemplo de un archivo robots.txt básico con solo dos reglas:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml
Símbolos comodín
Si quieres un control más preciso sobre el comportamiento del rastreador web, puedes usar caracteres comodín. En robots.txt hay dos: el asterisco (*) y el signo de dólar ($).
El comodín asterisco representa cualquier secuencia de símbolos. Aquí tienes algunos ejemplos de uso:
- User-agent: * — incluye a todos los user-agents.
- User-agent: googlebot* — incluye user-agents que empiezan por «googlebot», como «googlebot-news» o «googlebot/1.2».
- Disallow: /folder/ — bloquea todas las apariciones de esa carpeta, esté en el directorio raíz o dentro de otra carpeta.
- Disallow: /.png — bloquea todas las rutas que contengan «.png» en cualquier parte de la URL. Esto incluye rutas con símbolos después de la extensión, como «/imagen.png?scr=site.com».
El comodín del signo de dólar marca el final de la línea. Especifica que solo se incluyen en la directiva las rutas que terminan con la cadena indicada. Algunos ejemplos:
- Disallow: /folder/$ — bloquea exclusivamente la ruta /folder/, mientras permite el rastreo de las que la contengan.
- Allow: /*.pdf$ — permite el rastreo de rutas que terminan en .pdf. En este caso, rutas como «/file.pdf?parameters» quedan fuera de la directiva.
La directiva User-Agent
La directiva User-Agent es obligatoria y define el robot de búsqueda al que se aplican las reglas. Cada grupo de reglas comienza con esta directiva si hay varios bots.
Google tiene varios bots responsables de distintos tipos de contenido.
- Googlebot: rastrea sitios web para dispositivos móviles y de escritorio
- Googlebot Image: rastrea las imágenes de los sitios web para mostrarlas en la sección “Imágenes” y productos que dependen de imágenes
- Googlebot Video: escanea y muestra videos
- Googlebot News: selecciona artículos útiles y de alta calidad para la sección “Noticias”
- Google-InspectionTool: una herramienta de prueba de URL que imita a Googlebot al rastrear cada página a la que tiene acceso
- Google StoreBot: escanea varios tipos de páginas web, como detalles de productos, carritos y páginas de pago
- GoogleOther: analiza contenido de acceso público de los sitios web, incluidos rastreos únicos para investigación y desarrollo internos
- Google-CloudVertexBot: rastrea sitios a pedido de los propietarios de los sitios al crear agentes de Vertex AI
- Google-Extended: un token de producto independiente que se usa para administrar si los sitios web ayudan a mejorar las API generativas de Gemini Apps y Vertex AI y los modelos futuros
También hay un grupo separado de bots, o rastreadores de casos especiales, que incluye AdSense, Google-Safety y otros. Estos robots pueden tener diferentes comportamientos y permisos en comparación con los rastreadores comunes.
La lista completa de robots de Google (user agents) está disponible en la documentación de Ayuda oficial.
Otros motores de búsqueda también tienen raíces similares, como Bingbot para Bing, Slurp para Yahoo!, Baiduspider para Baidu y muchos más. Hay más de 500 robots de motores de búsqueda.
Ejemplo
- User-agent: * se aplica a todos los robots existentes.
- User-agent: Googlebot se aplica al robot de Google.
- User-agent: Bingbot se aplica al robot de Bing.
- User-agent: Slurp se aplica al robot de Yahoo!.
La directiva Disallow
Disallow es un comando clave que indica a los robots de los motores de búsqueda que no escaneen una página, archivo o carpeta. Los nombres de los archivos y las carpetas a los que quieres restringir el acceso se indican después del símbolo “/”.
Ejemplo 1. Especificación de diferentes parámetros después de Disallow.
Disallow: /enlace a la página prohíbe el acceso a una URL específica.
Disallow: /nombre de carpeta/ cierra el acceso a la carpeta.
Disallow: /*.png$ cierra el acceso a las imágenes en formato PNG.
Disallow: /. La ausencia de instrucciones después del símbolo “/” indica que el sitio web está completamente cerrado al escaneo, lo que puede ser útil durante el desarrollo del sitio.
Ejemplo 2. Deshabilitar el escaneo de todos los archivos .PDF del sitio web.
User-agent: Googlebot
Disallow: /*.pdf$
La directiva Allow
En el archivo robots.txt, la directiva Allow funciona de manera opuesta a Disallow al otorgar acceso al contenido del sitio web. Estos comandos se usan a menudo juntos, especialmente cuando necesitas abrir el acceso a información específica, como una foto en un directorio de archivos multimedia oculto.
Ejemplo. Usar Allow para escanear una imagen en un álbum cerrado.
Indica la directiva Allow con la URL de la imagen y, en otra línea, la directiva Disallow junto con el nombre de la carpeta donde se encuentra el archivo. El orden de las líneas es importante, ya que los rastreadores procesan los grupos de arriba a abajo.
Disallow: /album/
Allow: /album/picture1.jpg
La directiva “robots.txt Allow All” se utiliza normalmente cuando no existen restricciones o prohibiciones específicas para los motores de búsqueda.
Sin embargo, es importante tener en cuenta que la directiva “Allow: /” no es un componente necesario del archivo robots.txt.
De hecho, algunos webmasters optan por no incluirla en absoluto, confiando únicamente en el comportamiento predeterminado de los rastreadores de los motores de búsqueda.
La directiva Allow no forma parte de la especificación original de robots.txt. Esto significa que es posible que no todos los robots la admitan. Si bien muchos rastreadores populares como Googlebot reconocen y respetan la directiva Allow, es posible que otros no la respeten.
Según el Estándar de Exclusión de Robots, “los encabezados no reconocidos se ignoran”. Esto significa que para los robots que no reconocen la directiva “Allow”, el resultado puede ser diferente del que esperabas. Ten esto en cuenta al crear tus archivos robots.txt.
La directiva Sitemap
La directiva Sitemap en robots.txt indica la ruta al mapa del sitio. Esta directiva se puede omitir si el mapa del sitio tiene un nombre estándar, se encuentra en el directorio raíz y se puede acceder a él a través del enlace “nombre del sitio”/sitemap.xml, similar al archivo robots.txt.
Ejemplo
Sitemap: https://website.com/sitemap.xml
Aunque el archivo robots.txt se utiliza principalmente para controlar el escaneo de tu sitio web, el sitemap ayuda a los motores de búsqueda a comprender la organización y la estructura jerárquica de tu contenido.
Al incluir un enlace a tu mapa del sitio en el archivo robots.txt, proporcionas a los rastreadores de los motores de búsqueda una forma sencilla de localizar y analizar el mapa del sitio, lo que genera un rastreo e indexación más eficientes de tu sitio web.
Por lo tanto, no es obligatorio, pero sí muy recomendable, incluir una referencia a tu sitemap en el archivo robots.txt.
Comentarios
Puedes añadir comentarios al archivo robots.txt que expliquen directivas específicas, documenten cambios o actualizaciones del archivo, organicen diferentes secciones o brinden contexto a otros miembros del equipo.
Los comentarios son líneas que comienzan con el símbolo «#». Los bots ignoran estas líneas al procesar el archivo. Te ayudan a ti y a otros miembros del equipo a entender el archivo, pero no afectan la forma en que los bots lo leen. Aquí hay un ejemplo del archivo robots.txt de Wizzair.
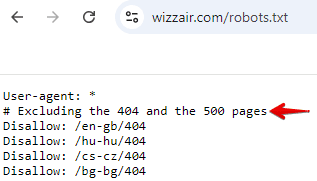
Si tu archivo robots.txt es bastante extenso e incluye directivas no estándar, lo mejor es dejar comentarios que expliquen qué intentan conseguir.
Extensiones no estándar
Más allá de las directivas básicas, existen algunas extensiones no estándar que pueden aparecer en archivos robots.txt.
Sitemap indica la ruta al archivo del sitemap.
Ejemplo
Sitemap: https://website.com/sitemap.xml
Esta directiva se puede omitir si el sitemap tiene un nombre estándar, está ubicado en el directorio raíz y se puede acceder a él a través del enlace «nombre del sitio»/sitemap.xml, igual que el archivo robots.txt.
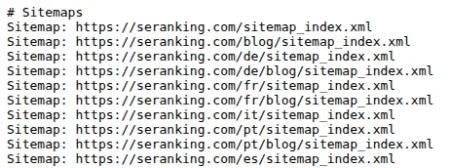
Es una directiva opcional, ya que Google y otros motores de búsqueda buscarán un sitemap por su cuenta, pero conviene incluirla como buena práctica para que lo encuentren antes. Sobre todo si tu sitio tiene varios sitemaps, como en el ejemplo de abajo.
- Crawl-delay especifica el retraso entre solicitudes de páginas. En su origen pretendía aliviar la carga del servidor, pero hoy apenas se usa. Los rastreadores de Google no respetan esta directiva, mientras que Bing, Yahoo y Yandex sí lo hacen.
Si detectas que Google está rastreando demasiado tu sitio web, usa Google Search Console para enviar un informe de sobrerrastreo.
- Content-signal es una directiva propuesta por Cloudflare para especificar el comportamiento de la IA en tu sitio web. Te permite permitir o denegar entrada de IA, entrenamiento de IA y búsqueda con IA.
User-Agent: *
Content-Signal: ai-train=no, search=yes, ai-input=no
Allow: /
En este ejemplo se permite la búsqueda en el sitio, pero se prohíbe el uso del contenido para entrenamiento y como entrada de IA.
Es una directiva relativamente nueva y muchos rastreadores la van a ignorar. Google todavía no se ha posicionado oficialmente. Por ahora, lo mejor es no usarla salvo que Google la adopte de forma oficial.
Cómo crear un archivo robots.txt
Un archivo robots.txt bien elaborado sirve como base para el SEO técnico.
Dado que el archivo tiene una extensión .txt, cualquier editor de texto que admita la codificación UTF-8 será suficiente. Las opciones más simples son el Bloc de notas (Windows) o TextEdit (Mac).
Como ya mencionamos anteriormente, la mayoría de las plataformas CMS también brindan soluciones para crear un archivo robots.txt.
Por ejemplo, WordPress crea un archivo robots.txt virtual de forma predeterminada, que se puede ver en línea agregando «/robots.txt» al nombre de dominio del sitio web.
Sin embargo, para modificar este archivo, debes crear tu propia versión. Puedes hacerlo a través de un complemento (por ejemplo, Yoast o All in One SEO Pack) o manualmente.
Magento y Wix, como plataformas CMS, también generan automáticamente el archivo robots.txt, pero solo contiene instrucciones básicas para los rastreadores web.
Por eso se recomienda crear instrucciones robots.txt personalizadas dentro de estos sistemas para optimizar con precisión el presupuesto de rastreo.
También puedes utilizar herramientas como el Generador de Robots.txt de SE Ranking para crear un archivo robots.txt personalizado en función de la información especificada. Tienes la opción de crear un archivo robots.txt desde cero o elegir una de las opciones sugeridas.
Si creas un archivo robots.txt desde cero, puedes personalizar el archivo de las siguientes formas:
- Configurando directivas para permisos de rastreo.
- Especificando páginas y archivos específicos a través del parámetro path.
- Determinando qué robots deben seguir estas directivas.
Como alternativa, se pueden seleccionar plantillas robots.txt preexistentes, incluidas directivas generales y de CMS ampliamente utilizados. También es posible incluir un sitemap dentro del archivo. Esta herramienta te ahorra tiempo al proporcionar un archivo robots.txt listo para descargar.
Título y tamaño del documento
El archivo robots.txt debe tener el mismo nombre que se menciona, sin usar letras mayúsculas. Según las directrices de Google, el tamaño del archivo no debe superar los 500 KiB. El contenido que aparezca después de este límite será ignorado por los motores de búsqueda.
Dónde colocar el archivo
El archivo robots.txt debe estar ubicado en el directorio raíz del host del sitio web y se puede acceder a él a través de FTP. Antes de realizar cualquier cambio, se recomienda descargar el archivo robots.txt original en su forma original.
Cómo verificar tu archivo robots.txt
Los errores en el archivo robots.txt pueden provocar que páginas importantes no aparezcan en el índice de búsqueda o que todo el sitio web sea invisible para los motores de búsqueda. Por el contrario, las páginas no deseadas que deberían ser privadas también pueden ser indexadas.
Puedes comprobar fácilmente tu archivo Robots.txt con el Comprobador de Robots.txt gratuito de SE Ranking. Solo debes introducir hasta 100 URL para probar y verificar si el escaneo está permitido.
Como alternativa, puedes acceder a un informe de robots.txt dentro de Google Search Console. Para ello, ve a Ajustes > Rastreo > robots.txt.

Abrir el informe de robots.txt revela los archivos robots.txt que Google encontró para los 20 principales hosts de tu sitio web, cuándo los comprobó por última vez, el estado del análisis y los problemas encontrados.
También puedes usar este informe para pedirle a Google que vuelva a rastrear un archivo robots.txt rápidamente si la necesidad de hacerlo es urgente.

Problemas comunes de robots.txt
Mientras administras el archivo robots.txt de tu sitio web, varios problemas pueden afectar la forma en que los rastreadores de búsqueda interactúan con tu sitio web. Algunos problemas comunes incluyen:
- Falta de coincidencia de formato: los rastreadores web no pueden detectar ni analizar el archivo si no está en formato .txt.
- Ubicación incorrecta: tu archivo robots.txt debe estar ubicado en el directorio raíz. Si se encuentra, por ejemplo, en una subcarpeta, los robots de búsqueda no podrán encontrarlo ni acceder a él.
- Uso incorrecto de «/» en la directiva Disallow: una directiva Disallow sin ningún contenido implica que los robots tienen permiso para visitar cualquier página de tu sitio web. Una directiva Disallow con «/» cierra tu sitio web a los robots. Siempre es mejor volver a comprobar el archivo robots.txt para asegurarte de que las directivas Disallow reflejen con precisión tus intenciones.
- Líneas en blanco en el archivo robots.txt: asegúrate de que no haya líneas en blanco entre las directivas. De lo contrario, los rastreadores web podrían tener dificultades para analizar el archivo. El único caso en el que se permiten los enlaces en blanco es antes de indicar un nuevo User-agent.
- Bloquear una página en robots.txt y agregar una directiva «noindex»: esto crea señales conflictivas. Es posible que los motores de búsqueda no comprendan la intención o ignoren la instrucción «noindex» por completo. Es mejor usar robots.txt para bloquear el rastreo o «noindex» para evitar la indexación, pero no ambos simultáneamente.
Herramientas e informes adicionales para comprobar si hay problemas
Existen muchas formas de analizar tu sitio web para detectar posibles problemas relacionados con el archivo robots.txt. Repasemos las más utilizadas.
1. Informe de páginas de Google Search Console.
La sección Páginas de GSC contiene información valiosa sobre tu archivo robots.txt.
Para comprobar si el archivo robots.txt de tu sitio web impide que Googlebot rastree una página, sigue estos pasos:
- Accede a la sección Páginas y navega hasta la categoría Sin indexar.

- Busca el error denominado Bloqueado por robots.txt y selecciónalo.

- Al hacer clic en esta sección, verás una lista de las páginas que están bloqueadas por el archivo robots.txt de tu sitio web. Asegúrate de que sean las páginas bloqueadas deseadas.

Además, comprueba si tienes el siguiente problema en esta sección: Indexado aunque un archivo robots.txt la tenía bloqueada.
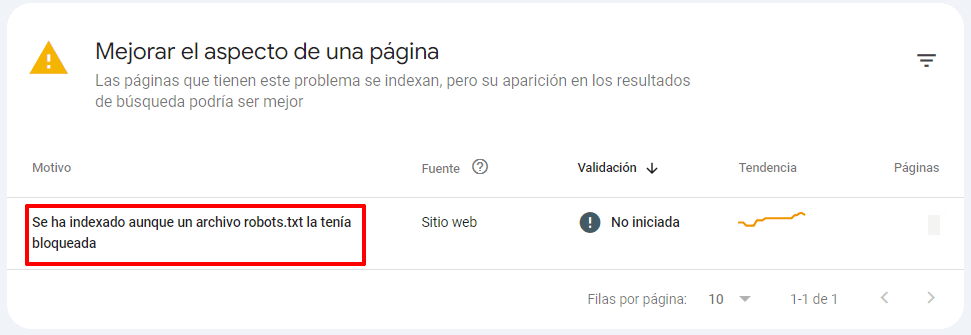
También puedes comprobar si las URL individuales están indexadas pegándolas en el cuadro de búsqueda de la herramienta de Inspección de URL de Google Search Console. Esto puede ayudarte a detectar posibles problemas de indexación causados por directivas conflictivas o reglas de robots.txt mal configuradas.
A continuación, verás una guía completa de Google Search Console sobre cómo detectar y solucionar problemas relacionados con la indexación.
2. Auditoría Web de SE Ranking
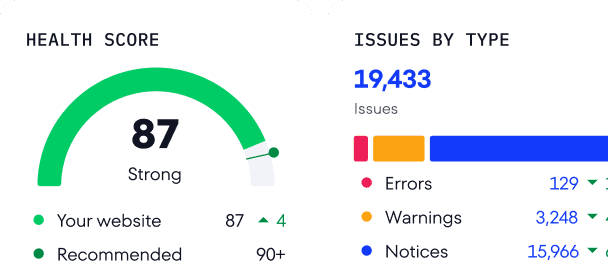
La herramienta de Auditoría Web de SE Ranking (y otras similares) proporciona un resumen completo de tu archivo robots.txt, incluida información sobre las páginas que están bloqueadas por el archivo.
También puede ayudarte a comprobar problemas relacionados con la indexación y el sitemap XML.
Para ver información sobre tu archivo robots.txt, comienza explorando el Informe de Problemas generado por la herramienta.
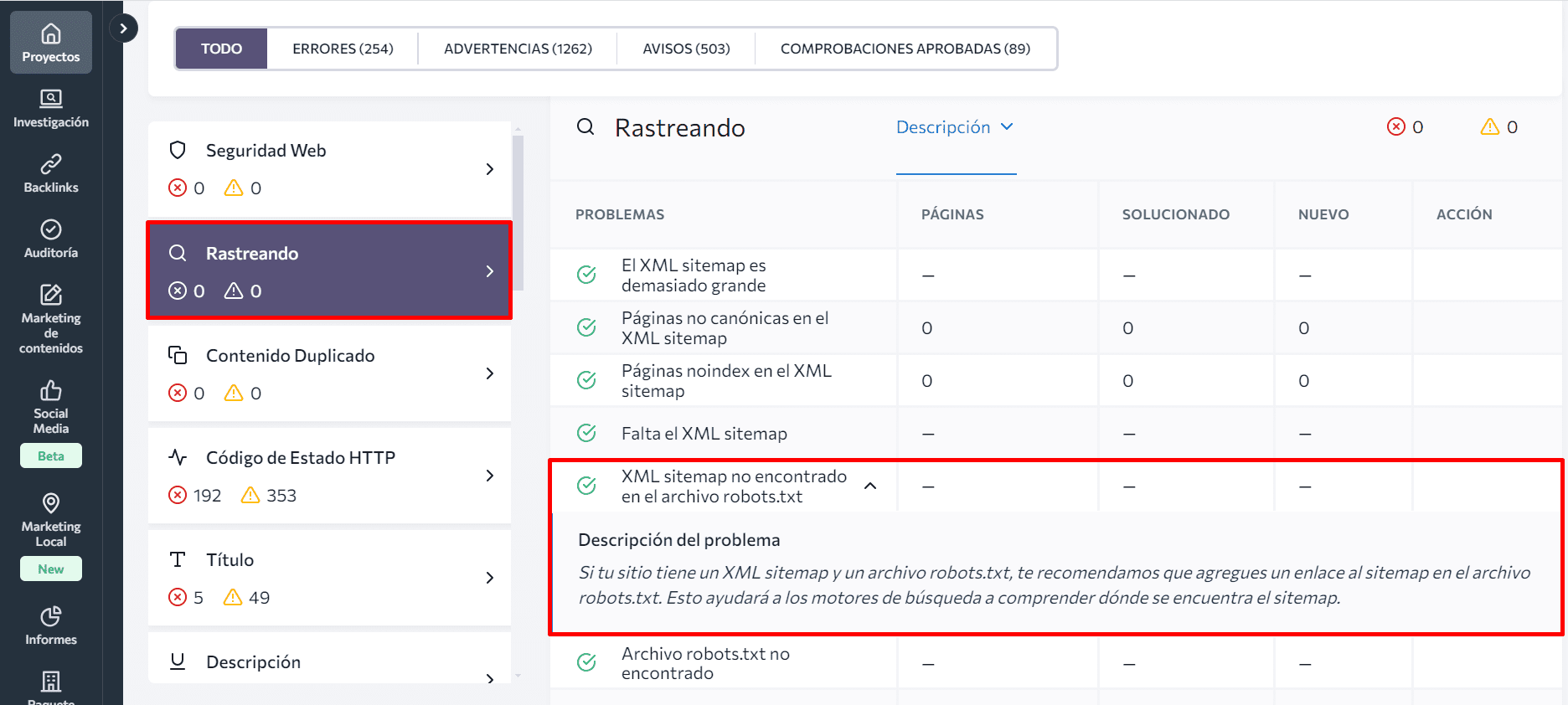
Entre las más de 120 métricas analizadas, encontrarás el parámetro Bloqueado por robots.txt en la sección Rastreo. Al hacer clic en él, verás una lista de páginas web bloqueadas para el rastreo, junto con descripciones de los problemas y sugerencias de solución rápida.
Esta herramienta también te ayuda a identificar si has añadido un enlace al archivo del sitemap en el archivo robots.txt. Simplemente, comprueba el estado del sitemap XML no encontrado en el archivo robots.txt en la misma sección.
Al navegar a la pestaña Páginas Rastreadas en el menú de la izquierda, puedes analizar los parámetros técnicos de cada página individualmente.
Aplica filtros para centrarte en la solución de problemas críticos de las páginas más importantes. Por ejemplo, si aplicas el filtro Bloqueado por robots.txt > Sí, se mostrarán todas las páginas bloqueadas por el archivo.

Generador y Comprobador de Robots.txt de SE Ranking

El Generador de Robots.txt facilita la creación del archivo sin que una errata acabe interfiriendo con tus intenciones.
Para crear el robots.txt de forma manual, añade las rutas que quieres permitir o bloquear, especifica los bots a los que aplica el conjunto de reglas y suma tu sitemap. También puedes incluir todos los formatos de imagen y archivo que necesites en la regla.
Si lo prefieres, ahorras tiempo con una de las plantillas de robots.txt: archivos listos para los CMS más populares o conjuntos de reglas habituales como bloquear todo a los bots más restringidos. Después puedes añadir reglas personalizadas a estos archivos.
Y si lo que quieres es probar tu archivo robots.txt, usa el Comprobador de Robots.txt. Introduce tu sitio web, y la herramienta te mostrará el archivo y revisará posibles incoherencias.
También sirve para comprobar las directivas que afectan a una URL concreta del sitio: la herramienta indicará si está permitida o no para el User-agent que elijas.

Mejores prácticas de SEO
Para garantizar que los rastreadores web indexen el contenido de tu sitio web de forma precisa y bien, sigue estas mejores prácticas de SEO.
- Asegúrate de utilizar correctamente las mayúsculas y minúsculas en el archivo robots.txt: los rastreadores web interpretan los nombres de las carpetas y secciones con distinción entre mayúsculas y minúsculas, por lo que utilizar el uso adecuado de las mayúsculas y minúsculas es fundamental para evitar confusiones y garantizar un rastreo e indexación precisos.
- Comienza cada directiva en una nueva línea, con solo un parámetro por línea.
- Evita utilizar espacios, comillas o punto y coma al escribir directivas.
- Usa la directiva Disallow para bloquear el rastreo de todos los archivos dentro de una carpeta o directorio específico. Esta técnica es más eficiente que enumerar cada archivo por separado.
- Emplea caracteres para obtener instrucciones más flexibles al crear el archivo robots.txt. El asterisco (*) significa cualquier variación en el valor, mientras que el signo de dólar ($) actúa como una restricción y significa el final de la ruta URL.
- Crea un archivo robots.txt independiente para cada dominio. Esto establece guías de rastreo para diferentes sitios de forma individual.
- Comprueba siempre el archivo robots.txt para asegurarte de que URL importantes no sean bloqueadas.
Conclusión
Hemos cubierto todos los aspectos importantes del archivo robots.txt, desde su sintaxis hasta las mejores prácticas y los problemas más comunes.
Ahora sabes por qué un archivo robots.txt bien configurado es crucial para una gestión eficaz del SEO y del sitio web.
Optimiza los presupuestos de rastreo, guía a los motores de búsqueda hacia el contenido importante y protege las áreas sensibles.
No te olvides de revisar y actualizar periódicamente tu archivo robots.txt a medida que tu sitio web evoluciona. Utiliza las herramientas y técnicas que hemos analizado para asegurarte de que tu archivo funcione como se espera.

