Common сanonical tag issues and how to fix them
Even the most experienced marketers and website owners make mistakes. But when it comes to using canonical tags, mistakes can be costly (and it’s not just about the money).
But don’t let that scare you! In this article, we’ll look at the most common canonical tag issues faced by SEO pros. By learning how to prevent them from happening, you’ll be able to deal with other related problems, including pages not being indexed or traffic loss caused by incorrect usage of canonical tags.
Key takeaways
In terms of SEO, canonical issues refer to problems associated with the canonicalization of content on a website. In other words, when your site has two or more URLs that are similar (or identical), search engines can’t determine which page to prioritize.
You can discover which version of the URL Google believes is the right one by using Google Search Console. This tool also pinpoints any pages that are being affected by specific canonicalization issues. If you’re planning to audit your website for canonical issues and get quick fix tips, you can benefit from using dedicated tools like SE Ranking’s Website Audit.
Here are the most common canonical tag mistakes most marketers face:
- Pointing to a URL that is blocked from crawling or indexing
- Creating canonical chains
- Pointing to a URL that returns a status code that isn’t 200
- Pointing to a URL with an HTTP protocol
- Adding non-canonical pages in the sitemap
- Pointing internal links to non-canonicalized URLs
- Using hreflang instead of canonical
- Using the “noindex” tag or blocking in the robots.txt file, plus using the canonical tag on the same page
- Not adding a single canonical tag to any identical pages
What is a canonical issue in SEO?
Not using a canonical tag correctly (or at all) can lead to major canonical issues. This holds especially true when websites offer multiple versions of identical content through distinct URLs. Sites like these absolutely must use canonical tags to indicate the preferred URL of these pages to avoid certain disasters.
So, canonical tag issue refers to a certain problem or misconfiguration related to the use of canonical tags on a website.
Canonical issues often can lead to duplicate content issues. They confuse search engines and make it difficult for search bots to determine which version of the content to index and display in search results. This also means you should check canonical URLs regularly. Doing so will help ensure that it matches the preferred page for indexing. Read our guide on website auditing to learn where to start.
How to check your canonical tags?
One of the most straightforward ways to check and manage canonical tags is by using Google Search Console. You can either analyze a separate URL in real time by using the URL Inspection Tool or check the canonical-related reports with all affected site pages (it takes time for data to collect and update).
In the first case, to test the page you want to check the canonical tag for, you’ll need to open the URL Inspection Tool, enter the URL, and initiate the inspection.
To see which URL Google selected as the preferred page version, scroll down to the Page Indexing block and observe the Google-selected canonical field.

If the Google-selected canonical and User-declared canonical values don’t match, Google is considering indexing the other version of the same page.
Now, to identify canonical tag issues that are affecting your webpages (and site as a whole), navigate to Indexing>Pages>Page Indexing>Why pages aren’t indexed.
You may find a list of canonicalization errors/notices among the many issues related to noindex tag, redirect errors, and so on. These include:
- Alternate page with proper canonical tag: Your canonical tag seems to be working fine and aligns with what Google considers to be the main version.
- Duplicate without user-selected canonical: You have at least two very similar or identical pages and you haven’t identified the canonical tag for one of them.
- Duplicate, Google chose different canonical than user: Google ignored your directive and chose another page as the main version.

GSC displays Google’s perspective on your canonical pages so that you get a basic picture of the situation.
SE Ranking also has a tool dedicated to this process. The platform lets you generate a comprehensive site audit report that offers way more than just canonical error insights.
It also provides a list of all technical issues affecting your website’s performance in search and offers practical tips on how to fix them. This helps you not only address duplicate content issues but also identify and fix other unseen technical problems.
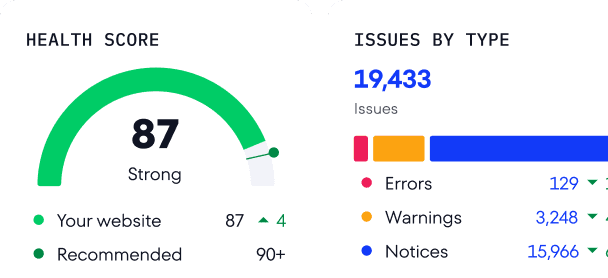
In the Issue Report section, you can see data on:
- rel=”canonical” from HTTPS to HTTP
- Non-canonical pages in XML sitemap
- Canonical chains
- Canonical URLs with a 3XX Status Code
- Canonical URLs with a 4XX Status Code
- Canonical URLs with a 5XX Status Code

Common mistakes when adding canonical tags
Now let’s take a look at the most common canonical mistakes. We’ll also discuss how to prevent them from happening.
Pointing to a URL that is not crawlable or indexable
The chosen canonical URL absolutely must be crawlable. This means it shouldn’t be blocked in the robots.txt file or by the X-Robots-tag or <meta name=“robots” content=“noindex” />.
You can check if the page is scannable and indexable in Google Search Console. You can also use SE Ranking’s Website Audit tool to get a breakdown of all pages and their tags.

For a quick check, use our free robots.txt checker to test if your page is open for crawling in your robots.txt file.
Creating canonical chains
When typing a URL in the href attribute, the page you are pointing to must neither have a canonical tag pointing to another page or the same page.
Now, let’s say that the page you want to canonicalize is https://site.com/phone/iphone12/.
The page you want to set as canonical is https://site.com/iphone12/.
It already contains the following canonical:
<link rel="canonical" href="https://site.com/phone/apple/iphone12/" />

This use case for canonical is incorrect because it creates a canonical chain.
The last in this chain is the page, https://site.com/phone/apple/iphone12/, which means that it will likely be considered canonical by search engines. If you don’t want to confuse search robots, you must direct them to only one canonical page.
In this example, you would have to decide which page you want to set as canonical: https://site.com/iphone12/ or https://site.com/phone/apple/iphone12/.
For the first option, you need to replace canonical on the https://site.com/iphone12/ page so that it points to itself and canonicalizes https://site.com/phone/iphone12/ and https://site.com/phone/apple/iphone12/.

To leave the page, https://site.com/phone/apple/iphone12, as canonical, other similar pages must link to it. The page must also link to itself.

Important! Be careful when modifying canonical URLs. You should always try to find out why certain values are being used.
Pointing to a URL that returns a status code other than 200
The URL you are designating as canonical must return a status code of 200, not 404 or 301. To check if the URL you are canonizing functions properly and has a status code of 200, you can use specialized SEO tools, like SE Ranking, to analyze it.
Pointing to a URL with an invalid protocol
Another common mistake many SEOs make is incorrectly specifying the URL protocol. Using HTTP instead of HTTPS, for example, can confuse search engine algorithms. Make it a point to specify the HTTPS version of the page in the href attribute.
Adding non-canonical pages in the sitemap
One more common mistake to look out for involves adding non-canonical pages in the sitemap.xml. This can cause search engines to ignore the page altogether and index them incorrectly. To avoid this problem, make sure that only the main page versions appear in the sitemap. The sitemap file only has to include pages pointing to themselves through canonical tags.
Be sure to read our guide on how to create sitemaps to learn the ins and outs of successful SEO mapping.
Pointing internal links to non-canonicalized URLs
Ensuring that your internal links point to the main version of the page helps search engines crawl your website without issues. If you link to your non-canonical page, Googlebot may sometimes ignore your canonical tag and index the illegitimate version of the URL. Not good.
Make sure to only add internal links to your non-canonical page when it’s absolutely necessary. There may be some cases where you’ll need to implement this type of internal linking for analytical purposes (e.g. you need to track some events on a non-canonical page with UTMs).
Using hreflang instead of canonical
Canonical tags tell Google that only one version of a webpage should be indexed. Hreflang tags inform the search engine that several versions of the same page exist but all of them still need to be indexed. This is because they target people who live in different regions and/or speak different languages.
This is the core difference between these attributes.
For a deeper understanding of how canonical tags, hreflang, and other HTML elements influence SEO, explore our detailed guide on HTML tags.
Apart from causing misinterpretation by search bots, this mistake can also lead to incorrect language/regional targeting and indexing issues. That’s why we strongly suggest reading our guide on how to approach hreflang vs canonical tags.
Using the “noindex” tag, blocking the page in the robots.txt file, and using the canonical tag
According to John Mueller, canonical tags shouldn’t be used in combination with the “noindex” tag and/or robots.txt disallow. Since each of these attributes serves a different function, using all of them simultaneously gives Google contradictory signals.
By doing so, you basically use one attribute to tell Google that a particular webpage is more important than the other, yet the other attribute says otherwise. Or, perhaps, you use the noindex to hide the page but still ask Google to pass that weight to other pages.
To avoid this issue, use each signal in the most appropriate cases:
- The “noindex” tag prevents pages from being indexed and appearing on SERPs.
- Blocking a page in the robots.txt file is a signal prohibiting crawling of a page.
- Canonical tags specify which page to prioritize as the main version.
Not adding a canonical tag to identical pages
Ignoring pages with similar or identical content and hoping that Google will understand which page to prioritize is another major mistake to avoid.
While Google is smart enough to determine which page to index and which title and meta description to display in the SERPs, it can still benefit greatly from your guidance. Offering Google a helping hand helps search bots focus on unique content instead of wasting time and resources crawling and indexing multiple versions of the same content.
To see if you have pages that are not canonicalized to the correct version, go to GSC and navigate to the Indexing>Pages>Page Indexing>Why pages aren’t indexed. Take a look at the Duplicate without user-selected canonical error.
Now, run through the list of URLs affected by this issue and analyze each of them. Make sure to either set up a redirect or canonicalize them to the preferred URL version. Alternatively, you can apply the noindex directive.
Closing thoughts
As with many things, it’s wiser to prevent than to remedy.
We hope you’ll be able to use the information provided in this article to avoid the most common canonical tag issues faced by SEO pros. The end goal? Your website’s success and the highest of rankings.

