Alles über die robots.txt Datei: Wie du sie richtig erstellst und überprüfst
-
Die robots.txt-Datei gibt Crawlern Anweisungen darüber, welche Seiten gecrawlt werden sollen und welche nicht. Ein Bot kann diese Anweisungen jedoch ignorieren.
-
Robots.txt kann das Indexieren nicht direkt verhindern, aber beeinflusst die Entscheidung eines Bots, bestimmte Inhalte zu crawlen oder zu ignorieren.
-
Robots.txt, Meta-Robots-Tags und X-Robots-Tags steuern Suchmaschinen-Bots unterschiedlich: Robots.txt regelt das Crawling, Meta-Tags wirken auf Seitenebene, und X-Robots-Tags ermöglichen eine detailliertere Kontrolle über das Indexieren.
-
Mit der Disallow-Anweisung kannst du irrelevante Inhalte ausblenden, das Crawl-Budget sparen und verhindern, dass unerwünschte Seiten in den Suchergebnissen erscheinen.
-
Nur wenn du die Syntaxregeln korrekt anwendest, kann ein Suchbot deine robots.txt-Datei richtig lesen und interpretieren.
-
Du kannst eine robots.txt-Datei mit jedem Texteditor erstellen, der UTF-8-Kodierung unterstützt, oder über integrierte Tools in gängigen CMS-Plattformen wie WordPress, Magento und Shopify.
-
Überprüfe deine robots.txt-Datei mit Tools wie der Google Search Console oder SEO-Plattformen wie SE Ranking, um potenzielle Probleme zu erkennen und sicherzustellen, dass die Datei wie gewünscht funktioniert.
-
Häufige Probleme umfassen Formatfehler, falsche Platzierung der Datei, fehlerhafte Anweisungen und widersprüchliche Befehle.
-
Beachte, dass bei robots.txt-Direktiven zwischen Groß- und Kleinschreibung unterschieden wird. Jede Anweisung sollte in einer neuen Zeile stehen. Nutze Platzhalter für mehr Flexibilität, erstelle separate Dateien für unterschiedliche Domains und teste deine Website nach jeder Änderung an der robots.txt-Datei, um sicherzustellen, dass wichtige URLs nicht versehentlich blockiert werden.
Was ist eine robots.txt-Datei?
Eine robots.txt-Datei ist ein Textdokument, das im Root-Verzeichnis einer Website liegt und speziell für Suchmaschinen-Crawler bestimmt ist. Sie weist diese darauf hin, welche URLs, also Seiten, Dateien, Ordner usw., gecrawlt werden sollen und welche nicht. Die Datei ist keine technische Voraussetzung für den Betrieb einer Website, muss aber korrekt eingerichtet sein, damit SEO funktioniert.
Die Entscheidung, robots.txt zu verwenden, wurde 1994 im Rahmen des Robots Exclusion Standard getroffen. Laut Google Search Central dient die Datei primär nicht dazu, Webseiten aus den Suchergebnissen zu entfernen, sondern die Anzahl der Anfragen von Bots an Websites zu begrenzen und die Serverlast zu reduzieren.
Grundsätzlich sollte der Inhalt der robots.txt-Datei als Empfehlung für Suchmaschinen-Crawler betrachtet werden, die die Regeln für das Crawlen einer Website festlegt. Um den Inhalt der robots.txt-Datei einer Website anzuzeigen, gib einfach „/robots.txt“ nach dem Domainnamen in die Browser-Adressleiste ein.
Wie funktioniert robots.txt?
Suchmaschinen müssen Seiten crawlen und indexieren, bevor sie diese in den Suchergebnissen anzeigen können. Dafür durchsuchen Webcrawler systematisch das Internet und sammeln Daten von jeder Seite, die sie besuchen. Gelegentlich wird dieser Vorgang auch als „Spidering” bezeichnet.
Wenn ein Crawler eine Website aufruft, prüft er zunächst die robots.txt-Datei, die Anweisungen dazu enthält, wie die Seiten der Website gecrawlt und indexiert werden sollen. Findet er keine robots.txt-Datei oder enthält sie keine Direktiven, die die Crawler-Aktivität einschränken, crawlt der Bot die Website so lange, bis das Crawl-Budget aufgebraucht ist oder andere Einschränkungen greifen.
Was ist llms.txt, und brauchst du sie für KI-Bots?
llms.txt ist ein vorgeschlagener Standard, der darauf abzielt, KI-Crawlern ein besseres Verständnis deiner Website zu vermitteln. Anders als robots.txt, die Crawler von bestimmten Seiten fernhält, enthält llms.txt Links zu wichtigen Seiten und beschreibt diese in natürlicher Sprache für KI-Crawler, ähnlich wie eine erweiterte Sitemap.

Obwohl der Standard bereits seit einer Weile existiert und einige KI-Plattformen ihr Interesse daran bekundet haben, gibt es bislang keine Anzeichen, dass er aktiv durchgesetzt wird. Laut einer SE Ranking-Studie zu diesem Thema hat llms.txt keinen nachweisbaren Einfluss auf die KI-Sichtbarkeit und die Anzahl der Zitierungen in KI-Suchen.
Die meisten Funktionen, die llms.txt standardisieren will, werden bereits durch die Sitemap und Schema-Markup abgedeckt oder sind überflüssig, weil KI den Kontext eigenständig erfassen kann.
Warum brauchst du eine robots.txt für SEO?
Für robots.txt gibt es zwei Hauptgründe aus SEO-Sicht: Crawling-Management und die Optimierung des Crawl-Budgets.
Crawling steuern (auch für KI-Bots!)
Die Kernfunktion der robots.txt-Datei besteht darin, das Scannen von Seiten und Ressourcen zu unterbinden, die nicht öffentlich zugänglich sein sollen. Das betrifft zum Beispiel Admin-Bereiche, doppelte Inhalte, Seiten, die sich noch in der Entwicklung befinden, oder Seiten mit URL-Parametern wie Filterergebnisse oder interne Suchanfragen.
Hinweis: Die Verwendung der „robots.txt disallow“-Anweisung garantiert nicht, dass eine bestimmte Seite nicht gecrawlt oder aus den SERPs ausgeschlossen wird. Google kann externe Faktoren wie eingehende Links berücksichtigen, um die Relevanz einer Seite zu bestimmen. Um das Indexieren explizit zu verhindern, solltest du das „noindex“-Meta-Tag oder den X-Robots-Tag HTTP-Header verwenden. Auch ein Passwortschutz kann die Indexierung verhindern.
Robots.txt-Direktiven werden auch von den meisten verbreiteten KI-Plattformen wie Gemini, Perplexity und ChatGPT respektiert. Wenn du bestimmte KI-Tools vom Zugriff auf deine Website ausschließen möchtest, kannst du die entsprechende Direktive für ihren User-Agent hinzufügen.
Es gibt Hunderte von KI-User-Agent-Namen, und die meisten Plattformen unterscheiden zwischen Bots für das Training, die Indexierung und nutzerinitiierte Suchanfragen. Training-Bots suchen nach Inhalten, mit denen das KI-Modell trainiert werden kann. Such- und Indexierungs-Bots legen interne Indexes für die Suche an. Nutzerinitiierte Bots rufen aktuelle Inhalte auf Nutzeranfrage ab, falls diese nicht im Index vorhanden sind.
Einige Beispiele:
Such- und Indexierungs-Bots (erstellen Indizes für KI-gestützte Suche):
- OAI-Searchbot
- Claude-SearchBot
- PerplexityBot
Nutzerinitiierte Bots (rufen Inhalte ab, wenn Nutzer Fragen stellen):
- ChatGPT-User
- Claude-User
- Perplexity-User
- Applebot
Hinweis: Einige nutzerinitiierte Bots können auch für Trainingszwecke eingesetzt werden.
Training-Bots (sammeln Daten für das Training von KI-Modellen):
- Meta-ExternalAgent
- Google-Extended
- GPTBot
- ClaudeBot
- Applebot-Extended
- Meta-ExternalAgent
Alle KI-Plattformen empfehlen, Such- und Indexierungs-Bots Zugang zur Website zu gewähren, damit die KI-Sichtbarkeit nicht beeinträchtigt wird. Das Verhalten anderer Crawler kann jedoch unterschiedlich sein, und es gibt Unterschiede zwischen den Plattformen.
Wer beispielsweise OpenAIs Indexierungscrawler OAI-Searchbot sperrt, verhindert, dass die Website in den Suchergebnissen erscheint. Die Website kann jedoch weiterhin in Navigationslinks auftauchen. Perplexitys Indexierungsbot meidet Websites, die ihn aussperren, indexiert die Domain aber dennoch und liefert eine kurze Zusammenfassung dazu.
Die meisten Training-Bots halten sich strikt an robots.txt-Direktiven, während einige nutzerinitiierte Bots wie ChatGPT-User diese möglicherweise ignorieren.
Crawl-Budget optimieren
Das Crawl-Budget beschreibt die Anzahl der Webseiten, die ein Suchroboter auf einer Website crawlt. Um das Crawl-Budget effizienter zu nutzen, sollten Suchroboter nur auf die wichtigsten Inhalte gelenkt und von weniger relevanten Informationen ferngehalten werden.
Die Optimierung des Crawl-Budgets hilft Suchmaschinen, ihre begrenzten Ressourcen besser zu nutzen. Dies führt zu einer schnelleren Indexierung neuer Inhalte und einer besseren Sichtbarkeit in den Suchergebnissen. Es ist jedoch wichtig zu beachten, dass Seiten, die das Crawl-Budget übersteigen, möglicherweise nicht gecrawlt und damit nicht indexiert werden. Nicht indexierte Seiten erscheinen nicht in den SERPs. Es ist daher ratsam, das Crawl-Budget optimal zu nutzen, insbesondere bei großen Websites oder wenn viele Seiten nicht indexiert sind, um sicherzustellen, dass Suchmaschinen alle wichtigen Seiten abdecken.
Eine Crawl-Budget-Optimierung lohnt sich vor allem, wenn du eine große Website mit Tausenden von Seiten betreibst, eine mittelgroße Website mit häufig wechselnden Inhalten hast oder einen erheblichen Anteil nicht indexierter Seiten feststellst. Die Optimierung stellt sicher, dass Suchmaschinen alle wichtigen Seiten vollständig erfassen.
Stell dir vor, deine Website enthält viele Seiten mit geringem Mehrwert im Vergleich zu deinen Hauptseiten. Hier kannst du das Crawl-Budget optimieren, indem du diese Seiten von der Crawling-Liste ausschließt.
Du kannst beispielsweise die „Disallow”-Direktive mit einer bestimmten Dateiendung kombinieren, etwa „Disallow:/*.pdf”, damit Suchmaschinen keine PDF-Ressourcen auf deiner Website crawlen.
Ein weiterer Vorteil von robots.txt liegt darin, dass sie Crawling-Probleme auf deinem Server beheben kann. Hat deine Website zum Beispiel unendliche Kalender-Skripte, die Probleme verursachen, wenn sie häufig von Bots aufgerufen werden, kannst du das Crawling dieses Skripts über robots.txt unterbinden.
Beispiel für eine robots.txt in SEO
Eine Vorlage mit aktuellen Direktiven hilft dir dabei, eine korrekt formatierte robots.txt-Datei zu erstellen, die die gewünschten Bots anspricht und den Zugang zu relevanten Dateien einschränkt.
User-agent: [Bot-Name]
Disallow: /[Pfad zur Datei oder zum Ordner]/
Disallow: /[Pfad zur Datei oder zum Ordner]/
Disallow: /[Pfad zur Datei oder zum Ordner]/
Sitemap: [URL der Sitemap]
Schauen wir uns ein paar Beispiele an, wie eine robots.txt-Datei aussehen könnte.
1. Allen Webcrawlern den Zugriff auf alle Inhalte erlauben
Ein einfaches Beispiel für eine robots.txt-Datei, die allen Webcrawlern vollen Zugriff gewährt:
User-agent: *
Allow: /
# Sitemaps
Sitemap: https://www.beispiel.com/sitemap.xml
In diesem Beispiel wird mit dem Sternchen (*) bei der „User-agent”-Direktive die Anweisung auf alle Webcrawler angewendet. Der Sitemap-Eintrag schränkt keinen Zugang ein, sondern verweist Crawler auf die Sitemap. Zeilen, die mit einem Rautezeichen beginnen, sind Kommentare und werden von Crawlern ignoriert.
2. Einen bestimmten Web-Crawler für eine bestimmte Seite sperren
Das folgende Beispiel legt Zugriffsberechtigungen für den User-agent „Bingbot“ fest, den Web-Crawler der Suchmaschine Bing von Microsoft. Es enthält eine Liste von Website-Verzeichnissen, die für das Scannen gesperrt sind, sowie einige Verzeichnisse und Seiten, die für den Zugriff erlaubt sind.
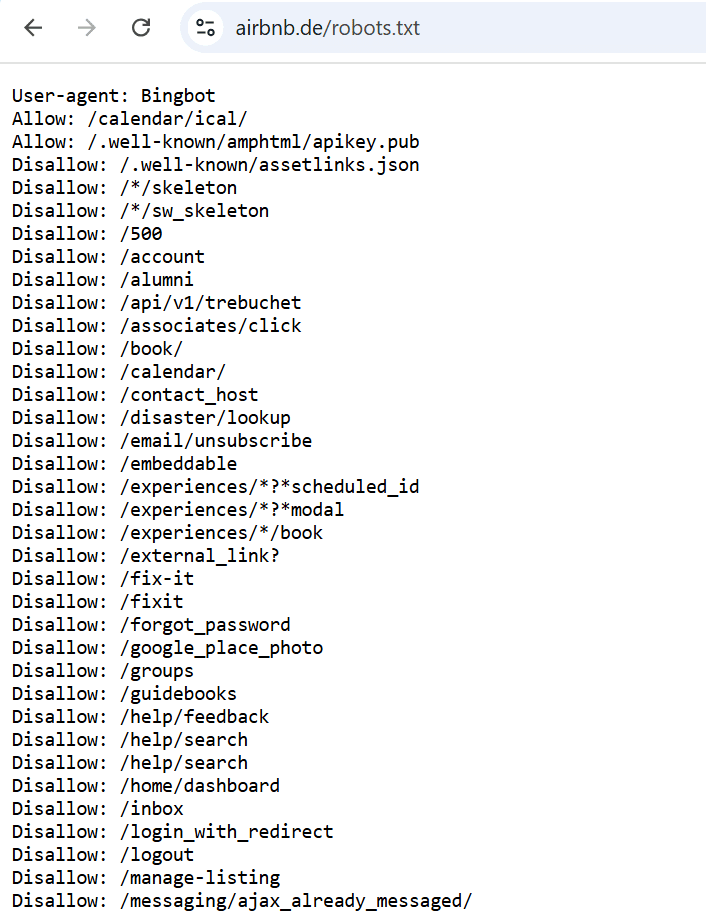
3. Alle Web-Crawler für alle Inhalte sperren
User-agent: *
Disallow: /
In diesem Beispiel gilt die Direktive „User-agent” weiterhin für alle Web-Crawler. Die Direktive „Disallow“ verwendet jedoch einen Schrägstrich (/) als Wert, was bedeutet, dass alle Inhalte der Website für jeden Web-Crawler gesperrt werden sollen. Dies teilt allen Bots effektiv mit, keine Seiten der Website zu crawlen.
Bitte beachte, dass das Sperren aller Web-Crawler vom Zugriff auf die Inhalte einer Website mit der robots.txt-Datei eine extreme Maßnahme ist und in den meisten Fällen nicht empfohlen wird. Dies kann nützlich sein, wenn eine neue Website noch in Entwicklung ist und noch nicht für Suchmaschinen zugänglich sein soll. In anderen Fällen wird die robots.txt-Datei in der Regel verwendet, um den Zugriff auf bestimmte Teile der Website zu steuern, z. B. durch das Sperren bestimmter Verzeichnisse oder Dateien, anstatt alle Inhalte zu blockieren.
4. Anweisungen für KI-Bots
Robots.txt lässt sich auch nutzen, um KI-Crawlern Anweisungen zu geben. Das folgende Beispiel zeigt einen Satz von Direktiven, der das Crawlen der gesamten Website erlaubt, bestimmte Unterverzeichnisse aber aussperrt.

Die vollständige Sperrung der Website ist nicht zu empfehlen, da das deine KI-Sichtbarkeit beeinträchtigt. Perplexity empfiehlt, ihren Such-Crawler PerplexityBot und ihren nutzeriniitierten Crawler Perplexity-User zuzulassen, um die KI-Sichtbarkeit zu sichern, da keiner der beiden für das Training verwendet wird. OpenAI empfiehlt das Zulassen von OAI-SearchBot für die KI-Sichtbarkeit; nur GPTBot wird für das Modelltraining genutzt.
Denk daran: Es gibt keinen einzigen User-Agent-Namen für alle KI-Crawler. Wenn du ihnen Direktiven mitgeben möchtest, musst du jeden User-Agent-Namen einzeln referenzieren.
Wie findet man die robots.txt-Datei?
Es gibt verschiedene Methoden, um die robots.txt-Datei einer Website zu finden:
Um die robots.txt-Datei zu finden, füge „/robots.txt“ zum Domainnamen der Website hinzu, die du überprüfen möchtest. Wenn die Domain beispielsweise „beispiel.com“ lautet, gib „beispiel.com/robots.txt“ in die Adressleiste deines Browsers ein. So gelangst du direkt zur robots.txt-Datei, falls sie auf der Website existiert.
Eine weniger häufig verwendete, aber dennoch übliche Methode für CMS-Nutzer besteht darin, die robots.txt-Datei direkt im System zu finden und zu bearbeiten. Schauen wir uns einige gängige Systeme an.
Eine robots.txt in WordPress
Um eine robots.txt-Datei in WordPress zu finden und zu bearbeiten, kannst du sie entweder manuell erstellen oder ein Plugin verwenden.
Um eine manuell zu erstellen:
- Erstelle eine Textdatei mit dem Namen „robots.txt“.
- Lade sie über einen FTP-Client in dein Stammverzeichnis hoch.
Mit dem Yoast SEO Plugin:
- Gehe zu Yoast SEO > Tools.
- Klicke auf Datei-Editor (stelle sicher, dass die Dateibearbeitung aktiviert ist).
- Klicke auf die Schaltfläche robots.txt-Datei erstellen.
- Dort kannst du die robots.txt-Datei anzeigen oder bearbeiten.
Mit dem All in One SEO Plugin:
- Gehe zu All in One SEO > Tools.
- Klicke auf Robots.txt-Editor.
- Aktiviere die benutzerdefinierte robots.txt, indem du den Schalter umlegst.
- Dort kannst du die robots.txt-Datei anzeigen oder bearbeiten.
Eine robots.txt in Magento
Magento generiert automatisch eine Standard-robots.txt-Datei.
So bearbeitest du die Datei:
- Melde dich im Magento-Admin-Panel an.
- Gehe zu Inhalt > Design > Konfiguration.
- Klicke auf Bearbeiten für die Hauptwebsite.
- Erweitere den Abschnitt Suchmaschinenroboter.
- Bearbeite den Inhalt im Feld Benutzerdefinierte Anweisungen der robots.txt-Datei bearbeiten.
- Speichere die Konfiguration.
Eine robots.txt in Shopify
Shopify generiert ebenfalls automatisch eine Standard-robots.txt-Datei.
So bearbeitest du die Datei:
- Melde dich im Shopify-Admin-Panel an.
- Klicke auf Einstellungen > Apps und Verkaufskanäle.
- Gehe zu Online-Shop > Themes.
- Klicke auf die …-Schaltfläche neben deinem aktuellen Theme und wähle Code bearbeiten.
- Klicke auf Neues Template hinzufügen > robots.
- Klicke auf Template erstellen.
- Bearbeite den Inhalt nach Bedarf.
- Speichere deine Änderungen.
1. Website analysieren mit automatisierten Tools wie dem SE Ranking Website Audit
Ein weiterer Weg, die robots.txt-Datei zu prüfen, ist ein Website-Audit-Tool. Es überprüft deine Website und liefert Informationen darüber, ob eine robots.txt-Datei vorhanden ist und welche Seiten sie sperrt. Überprüfe die gesperrten Seiten und stelle sicher, dass die Sperrung beabsichtigt war.
Starte das Audit, warte auf die Fertigstellung (du erhältst eine Benachrichtigung per E-Mail) und gehe anschließend zum Problembericht. Wähle dort den Bereich Crawling & Indexierung und prüfe, ob das Problem robots.txt-Datei nicht gefunden gemeldet wird.
2. robots.txt für dein CMS generieren
Wenn deine Website keine robots.txt-Datei hat, kannst du eine von Grund auf neu erstellen oder mit dem kostenlosen robots.txt-Generator von SE Ranking generieren. Direktiven und Pfade kannst du manuell eingeben oder die Datei automatisch generieren lassen. Wähle dein CMS aus, und das Tool fügt automatisch alle Unterverzeichnisse hinzu, die in der Regel vom Crawling ausgeschlossen werden sollten.
Hier ein Beispiel für WordPress:

Weitere Verzeichnisse, die du vom Crawling ausschließen möchtest, kannst du im Anschluss hinzufügen.
Wie Suchmaschinen deine robots.txt-Datei finden
Suchmaschinen verwenden spezifische Mechanismen, um die robots.txt-Datei auf deiner Website zu finden und darauf zuzugreifen. So funktioniert es in der Regel:
1. Besuchen einer Website: Suchmaschinen-Crawler durchforsten kontinuierlich das Internet, besuchen Websites und folgen Links, um neue Seiten zu entdecken.
2. Abrufen der robots.txt-Datei: Wenn ein Suchmaschinen-Crawler eine Website besucht, sucht er nach der robots.txt-Datei, indem er „/robots.txt“ an die Domain der Website anhängt.
Hinweis: Nachdem du deine robots.txt-Datei erfolgreich hochgeladen und getestet hast, erkennen Googles Crawler sie automatisch und beginnen, die Anweisungen zu befolgen. Es sind keine weiteren Schritte notwendig. Solltest du jedoch Änderungen an deiner robots.txt-Datei vornehmen und möchtest, dass Google die aktualisierte Version umgehend erkennt, musst du lernen, wie man eine aktualisierte robots.txt-Datei einreicht.
3. Abrufen der robots.txt-Datei: Falls sich eine robots.txt-Datei am angegebenen Speicherort befindet, lädt der Crawler die Datei herunter und analysiert sie, um die Crawling-Direktiven zu ermitteln.
4. Befolgen der Anweisungen: Nach dem Abrufen der robots.txt-Datei hält sich der Suchmaschinen-Crawler an die darin festgelegten Anweisungen.
Robots.txt vs. Meta-Robots-Tags vs. X-Robots-Tags
Die robots.txt-Datei, das Meta-Robots-Tag und der X-Robots-Tag haben ähnliche Zwecke, nämlich Suchmaschinen-Crawlern Anweisungen zu geben. Sie unterscheiden sich jedoch in ihrer Anwendung und ihrem Kontrollbereich.
Wenn du Website-Inhalte aus den Suchergebnissen heraushalten möchtest, reicht robots.txt allein oft nicht aus. Die Datei gibt Crawlern lediglich eine Empfehlung, auf welche Bereiche sie zugreifen dürfen. Sie garantiert nicht, dass Inhalte nicht indexiert werden, denn Suchmaschinen können Links zu gesperrten Seiten auf anderen Websites finden. Für eine zuverlässige Steuerung der Indexierung brauchst du zusätzliche Methoden.
Robots-Meta-Tag
Eine effektive Methode zur Steuerung der Indexierung ist die Verwendung des Robots-Meta-Tags, das im <head>-Bereich des HTML-Codes einer Seite platziert wird. Mit einem Meta-Tag und der “noindex”-Direktive können Webmaster Suchmaschinen-Bots explizit mitteilen, dass der Inhalt einer Seite nicht indexiert werden soll. Diese Methode bietet eine präzisere Kontrolle über einzelne Seiten und deren Indexierungsstatus im Vergleich zu den allgemeinen Anweisungen der robots.txt-Datei.
Hier ein Beispiel für einen Codeausschnitt, der die Indexierung durch Suchmaschinen auf Seitenebene verhindert:
<meta name="robots" content="noindex">
Ähnlich wie die robots.txt-Datei erlaubt auch dieses Meta-Tag die Einschränkung bestimmter Bots. Um beispielsweise einen spezifischen Bot (z. B. Googlebot) einzuschränken, kannst du verwenden:
<meta name="googlebot" content="noindex">
X-Robots-Tag
Das X-Robots-Tag kann in der Konfigurationsdatei der Website genutzt werden, um die Indexierung von Seiten weiter einzuschränken. Diese Methode bietet eine zusätzliche Kontroll- und Flexibilitätsebene bei der granularen Verwaltung der Indexierung.
Seiten und Dateien, die häufig über robots.txt gesperrt werden
1. Admin-Dashboard und Systemdateien
Interne und Servicedateien, mit denen nur Website-Administratoren oder Webmaster interagieren sollten.
2. Hilfsseiten, die nur nach bestimmten Nutzeraktionen angezeigt werden.
Seiten, die Kunden nach dem erfolgreichen Abschluss einer Bestellung, dem Ausfüllen von Formularen, der Autorisierung oder der Passwortwiederherstellung angezeigt werden.
3. Suchseiten.
Seiten, die angezeigt werden, nachdem ein Website-Besucher eine Anfrage in die Suchleiste der Website eingegeben hat, werden in der Regel für Suchmaschinen-Crawler gesperrt.
4. Filterseiten.
Ergebnisse, die mit einem angewendeten Filter (Größe, Farbe, Hersteller usw.) angezeigt werden, sind separate Seiten und können als doppelter Inhalt betrachtet werden. SEO-Experten verhindern in der Regel, dass diese Seiten gecrawlt werden, es sei denn, sie generieren Traffic für Marken-Keywords oder andere Zielanfragen. Aggregator-Seiten, bestimmte E-Commerce-Websites und ordentlich konfigurierte Filterseiten, die Traffic erzeugen können, sind Ausnahmen.
5. Dateien eines bestimmten Formats.
Dateien wie Fotos, Videos, .PDF-Dokumente oder JS-Dateien. Mithilfe der robots.txt-Datei kannst du das Scannen einzelner Dateien oder solcher mit einer bestimmten Dateierweiterung einschränken.
Syntax der robots.txt-Datei
Um die Sichtbarkeit deiner Webseiten in Suchmaschinen zu steuern, musst du die Syntax und Struktur der robots.txt-Datei verstehen. Die Datei enthält Regeln, die festlegen, auf welche Dateien einer Domain oder Subdomain Crawler zugreifen dürfen. Diese Regeln können den Zugang zu bestimmten Dateipfaden erlauben oder sperren. Standardmäßig gilt: Wenn in der robots.txt-Datei nichts anderes festgelegt ist, dürfen alle Dateien gecrawlt werden.
Die robots.txt-Datei besteht aus Gruppen, die jeweils mehrere Regeln oder Anweisungen enthalten. Diese Regeln werden zeilenweise aufgelistet. Jede Gruppe beginnt mit einer „User-agent“-Zeile, die die Zielgruppe der Regeln angibt.
Eine Gruppe enthält folgende Informationen:
- Der User-Agent, auf den sich die Regeln beziehen.
- Die Verzeichnisse oder Dateien, auf die der User-Agent zugreifen darf.
- Die Verzeichnisse oder Dateien, auf die der User-Agent nicht zugreifen darf.
Bei der Verarbeitung der robots.txt-Datei folgen Crawler dem spezifischsten Pfad. Erlaubt die Datei beispielsweise das Crawlen aller Website-Inhalte, sperrt aber ein Verzeichnis und erlaubt ein Unterverzeichnis davon, greift der User-Agent auf alle Inhalte und das angegebene Unterverzeichnis zu, ignoriert aber den Rest des gesperrten Verzeichnisses.
Ein User-Agent kann nur einem einzigen Regelsatz entsprechen. Gibt es mehrere Gruppen für denselben User-Agent, werden diese vor der Verarbeitung zu einer einzigen Gruppe zusammengeführt. Bei widersprüchlichen Direktiven wählt Google die weniger restriktive.
Ein einfaches Beispiel für eine robots.txt-Datei mit zwei Regeln:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.beispiel.com/sitemap.xml
Da Crawler den spezifischsten Regelsatz suchen, sperrt diese Datei Googlebot für den Ordner /nogooglebot/ und erlaubt allen anderen Crawlern den Zugang zur gesamten Website.
Bei Pfadangaben in Direktiven gilt der angegebene Pfad für alle Pfade, die damit beginnen. In diesem Beispiel wären das:
- https://www.beispiel.com/nogooglebot/
- https://www.beispiel.com/nogooglebot/folder/
- https://www.beispiel.com/nogooglebot/folder/content.html
- https://www.beispiel.com/nogooglebot/folder/content.html?parameter=0
Nicht enthalten wäre hingegen: https://www.beispiel.com/folder/nogooglebot/
Wildcard-Zeichen
Mit Wildcard-Zeichen kannst du das Verhalten von Webcrawlern noch präziser steuern. In robots.txt gibt es zwei davon: * und $.
Das Sternchen steht für eine beliebige Zeichenfolge. Einige Anwendungsbeispiele:
- User-agent: * — gilt für alle existierenden User-Agents.
- User-agent: googlebot* — gilt für alle User-Agents, die mit „googlebot” beginnen, wie „googlebot-news” oder „googlebot/1.2″.
- Disallow: */folder/ — sperrt alle Instanzen dieses Ordnernamens, unabhängig davon, ob er sich im Root-Verzeichnis oder in einem anderen Ordner befindet.
- Disallow: /*.png — sperrt alle Pfade, die „.png” irgendwo im URL-Pfad enthalten. Das schließt Pfade mit Zeichen nach der Endung ein, etwa „/image.png?scr=site.com”.
Das Dollarzeichen steht für das Zeilenende. Es legt fest, dass nur Pfade, die mit dem angegebenen String enden, von der Direktive erfasst werden:
- Disallow: /folder/$ — sperrt exakt den Pfad /folder/, erlaubt aber das Crawlen von Pfaden, die diesen enthalten.
- Allow: /*.pdf$ — erlaubt das Crawlen von Pfaden, die auf .pdf enden. Pfade wie „/file.pdf?parameters” sind von dieser Direktive ausgeschlossen.
Die User-agent-Direktive
Die User-agent-Direktive ist obligatorisch und definiert, für welchen Suchroboter die Regeln gelten. Jede Regelgruppe beginnt mit dieser Direktive, wenn es mehrere Bots gibt.
Google hat mehrere Bots, die für verschiedene Arten von Inhalten verantwortlich sind:
- Googlebot: Crawlt Websites für Desktop- und Mobilgeräte.
- Googlebot Image: Crawlt Bilder von Websites, um sie im Bereich „Bilder“ und bei bildbasierten Produkten anzuzeigen.
- Googlebot Video: Scannt und zeigt Videos an.
- Googlebot News: Wählt nützliche und qualitativ hochwertige Artikel für den Bereich „News“ aus.
- Google-InspectionTool: Ein URL-Testtool, das Googlebot imitiert, indem es alle zugänglichen Seiten crawlt.
- Google StoreBot: Scannt verschiedene Seitentypen, wie Produktdetails, Warenkorb- und Checkout-Seiten.
- GoogleOther: Ruft öffentlich zugängliche Inhalte von Websites ab, einschließlich einmaliger Crawls für interne Forschung und Entwicklung.
- Google-CloudVertexBot: Crawlt Websites auf Anfrage von Website-Betreibern, die Vertex AI Agents erstellen.
- Google-Extended: Ein eigenständiger Produkt-Token, der steuert, ob Websites helfen, Gemini Apps, Vertex AI generative APIs und zukünftige Modelle zu verbessern.
Es gibt auch eine separate Gruppe von Bots, sogenannte „Special-Case-Crawler“, wie AdSense, Google-Safety und andere. Diese Bots können sich im Verhalten und in den Berechtigungen von den gängigen Crawlern unterscheiden.
Die vollständige Liste der Google-Roboter (User-agents) findest du in der offiziellen Hilfedokumentation.
Andere Suchmaschinen haben ähnliche Bots, zum Beispiel Bingbot für Bing, Slurp für Yahoo!, Baiduspider für Baidu und viele mehr. Insgesamt gibt es über 500 Suchmaschinen-Bots.
Beispiel
- User-agent: * \ gilt für alle existierenden Roboter.
- User-agent: Googlebot gilt für Googles Roboter.
- User-agent: Bingbot gilt für Bings Roboter.
- User-agent: Slurp gilt für Yahoos Roboter.
Die Disallow-Direktive
Disallow ist ein wichtiger Befehl, der Suchmaschinen-Bots anweist, eine Seite, Datei oder einen Ordner nicht zu scannen. Die Namen der Dateien und Ordner, auf die der Zugriff beschränkt werden soll, werden nach dem „/“-Symbol angegeben.
Beispiel 1: Angabe verschiedener Parameter nach Disallow.
Disallow: /link zur Seite verbietet den Zugriff auf eine bestimmte URL.
Disallow: /ordnername/ sperrt den Zugriff auf den Ordner.
Disallow: /*.png$ sperrt den Zugriff auf Bilder im PNG-Format.
Disallow: /. Das Fehlen von Anweisungen nach dem „/“-Symbol bedeutet, dass die gesamte Website vom Scannen ausgeschlossen wird, was während der Entwicklung einer Website nützlich sein kann.
Beispiel 2: Sperrung des Scannens aller .PDF-Dateien auf der Website.
User-agent: Googlebot
Disallow: /*.pdf$
Die Allow-Direktive
In der robots.txt-Datei funktioniert die Allow-Direktive entgegengesetzt zu Disallow, indem sie den Zugriff auf Website-Inhalte erlaubt. Diese Befehle werden oft zusammen verwendet, insbesondere wenn der Zugriff auf bestimmte Informationen wie ein Foto in einem geschützten Medienverzeichnis geöffnet werden soll.
Beispiel 1: Verwendung von Allow, um ein Bild in einem geschlossenen Album zu scannen.
Gib die Allow-Direktive mit der Bild-URL an und auf einer anderen Zeile die Disallow-Direktive mit dem Namen des Ordners, in dem sich die Datei befindet. Die Reihenfolge der Zeilen ist wichtig, da Crawler Gruppen von oben nach unten verarbeiten.
Disallow: /album/
Allow: /album/bild1.jpg
Die „robots.txt Allow All“-Direktive wird normalerweise verwendet, wenn es keine spezifischen Einschränkungen oder Verbote für Suchmaschinen gibt. Es ist jedoch wichtig zu beachten, dass die „Allow: /“-Direktive kein notwendiger Bestandteil der robots.txt-Datei ist. Tatsächlich verzichten einige Webmaster vollständig darauf und verlassen sich auf das Standardverhalten der Suchmaschinen-Crawler.
Die Allow-Direktive ist kein Bestandteil der ursprünglichen robots.txt-Spezifikation. Das bedeutet, dass sie möglicherweise nicht von allen Bots unterstützt wird. Während viele bekannte Crawler wie Googlebot die Allow-Direktive erkennen und respektieren, tun dies andere möglicherweise nicht.
Laut dem Standard for Robots Exclusion „werden nicht erkannte Header ignoriert“. Das bedeutet, dass Bots, die die „Allow“-Direktive nicht erkennen, ein anderes Verhalten zeigen können, als vom Webmaster erwartet. Dies sollte bei der Erstellung von robots.txt-Dateien berücksichtigt werden.
Kommentare
Du kannst der robots.txt-Datei Kommentare hinzufügen, um spezifische Direktiven zu erklären, Änderungen oder Aktualisierungen der Datei zu dokumentieren, verschiedene Abschnitte zu organisieren oder anderen Teammitgliedern Kontext zu bieten. Kommentare beginnen mit dem Symbol „#“. Diese Zeilen werden von Bots ignoriert, wenn die Datei verarbeitet wird. Sie helfen dir und deinem Team, die Datei besser zu verstehen, beeinflussen jedoch nicht, wie Bots sie lesen.
Hier ein Beispiel aus der robots.txt-Datei von Wizzair:
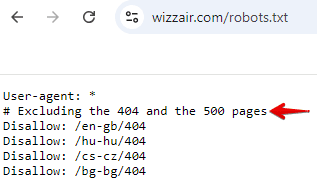
Wenn deine robots.txt-Datei umfangreich ist und nicht standardmäßige Direktiven enthält, empfiehlt es sich, erklärende Kommentare hinzuzufügen.
Nicht-standardmäßige Erweiterungen
Neben den oben genannten Direktiven gibt es einige nicht standardmäßige Direktiven, die in robots.txt verwendet werden können.
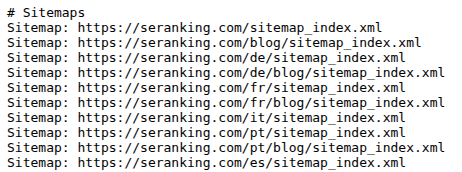
Sitemap gibt den Pfad zur Sitemap-Datei an.
Beispiel:
Sitemap: https://website.com/sitemap.xml
Diese Direktive kann weggelassen werden, wenn die Sitemap einen Standardnamen trägt, im Root-Verzeichnis liegt und über den Link „seitenname”/sitemap.xml erreichbar ist. Google und andere Suchmaschinen suchen auch ohne expliziten Hinweis nach einer Sitemap, aber es ist Best Practice, diesen Eintrag zu setzen, damit sie schneller gefunden wird, insbesondere wenn deine Website mehrere Sitemaps hat.
Crawl-delay legt die Verzögerung zwischen Seitenanfragen fest. Ursprünglich sollte diese Direktive die Serverlast reduzieren; heute wird sie kaum noch eingesetzt. Google-Crawler respektieren diese Direktive nicht, während Bing, Yahoo und Yandex sie weiterhin berücksichtigen.
Falls du Probleme mit einem zu häufigen Crawling feststellst, kannst du Google Search Console nutzen, um einen Bericht über übermäßiges Crawling einzureichen.
Content-signal ist eine Direktive, die von Cloudflare vorgeschlagen wurde, um das KI-Verhalten auf deiner Website zu steuern. Sie erlaubt es, KI-Input, KI-Training und KI-Suche gezielt zu erlauben oder zu sperren.
User-Agent: *
Content-Signal: ai-train=no, search=yes, ai-input=no
Allow: /
In diesem Beispiel ist das Durchsuchen der Website erlaubt, die Nutzung der Inhalte für Training und KI-Input hingegen nicht.
Das ist eine relativ neue Direktive, und viele Crawler werden sie zunächst ignorieren. Google hat noch keine offizielle Position dazu bezogen. Vorerst ist es empfehlenswert, sie erst zu verwenden, wenn Google sie offiziell unterstützt.
Wie man eine robots.txt für SEO erstellt
Eine gut gestaltete robots.txt-Datei bildet die Grundlage für technisches SEO.
Da die Datei die Erweiterung .txt hat, reicht ein einfacher Texteditor mit UTF-8-Unterstützung aus. Die einfachsten Optionen sind Notepad (Windows) oder TextEdit (Mac).
Wie bereits erwähnt, bieten die meisten CMS-Plattformen Lösungen zum Erstellen einer robots.txt-Datei. WordPress erstellt beispielsweise standardmäßig eine virtuelle robots.txt-Datei, die online einsehbar ist, indem man „/robots.txt“ an die Domain der Website anhängt. Um diese Datei jedoch zu bearbeiten, muss eine eigene Version erstellt werden. Dies kann entweder über ein Plugin (z. B. Yoast oder All in One SEO Pack) oder manuell erfolgen.
Auch Magento und Wix generieren als CMS-Plattformen automatisch eine robots.txt-Datei, die jedoch nur grundlegende Anweisungen für Web-Crawler enthält. Daher wird empfohlen, benutzerdefinierte Anweisungen innerhalb dieser Systeme zu erstellen, um das Crawl-Budget optimal zu nutzen.
Tools wie der Robots.txt Generator von SE Ranking ermöglichen ebenfalls die Erstellung einer benutzerdefinierten robots.txt-Datei basierend auf den angegebenen Informationen. Dabei hast du die Wahl, die Datei von Grund auf neu zu erstellen oder eine der vorgeschlagenen Vorlagen zu verwenden.
Wenn du eine robots.txt-Datei von Grund auf neu erstellst, kannst du sie auf folgende Weise personalisieren:
- Durch das Konfigurieren von Direktiven für Crawling-Berechtigungen.
- Durch das Festlegen spezifischer Seiten und Dateien mithilfe des Pfadparameters.
- Durch die Bestimmung, welche Bots diese Anweisungen befolgen sollen.
Alternativ können vordefinierte robots.txt-Vorlagen ausgewählt werden, die allgemeine und CMS-spezifische Direktiven enthalten. Es ist auch möglich, eine Sitemap in die Datei aufzunehmen. Dieses Tool spart Zeit, indem es eine fertige robots.txt-Datei zum Herunterladen bereitstellt.
Dateiname und Größe
Die robots.txt-Datei sollte exakt wie angegeben benannt werden, ohne Großbuchstaben zu verwenden. Laut den Google-Richtlinien sollte die Dateigröße 500 KiB nicht überschreiten. Inhalte nach diesem Limit werden von Suchmaschinen ignoriert.
Wo die Datei platziert werden sollte
Die robots.txt-Datei muss im Stammverzeichnis des Website-Hosts abgelegt werden und ist über FTP zugänglich. Es wird empfohlen, die ursprüngliche robots.txt-Datei vor Änderungen in ihrer Originalform herunterzuladen.
Wie man die robots.txt-Datei überprüft
Fehler in der robots.txt-Datei können dazu führen, dass wichtige Seiten nicht im Suchindex erscheinen oder die gesamte Website für Suchmaschinen unsichtbar wird. Andererseits könnten unerwünschte Seiten, die privat bleiben sollten, ebenfalls indexiert werden.
Die Robots.txt-Datei kann einfach mit dem kostenlosen Robots.txt Tester von SE Ranking überprüft werden. Gib bis zu 100 URLs ein, um zu testen, ob sie zum Scannen freigegeben sind.
Alternativ kannst du in der Google Search Console einen robots.txt-Bericht abrufen. Gehe dazu zu Einstellungen > Crawling > robots.txt.
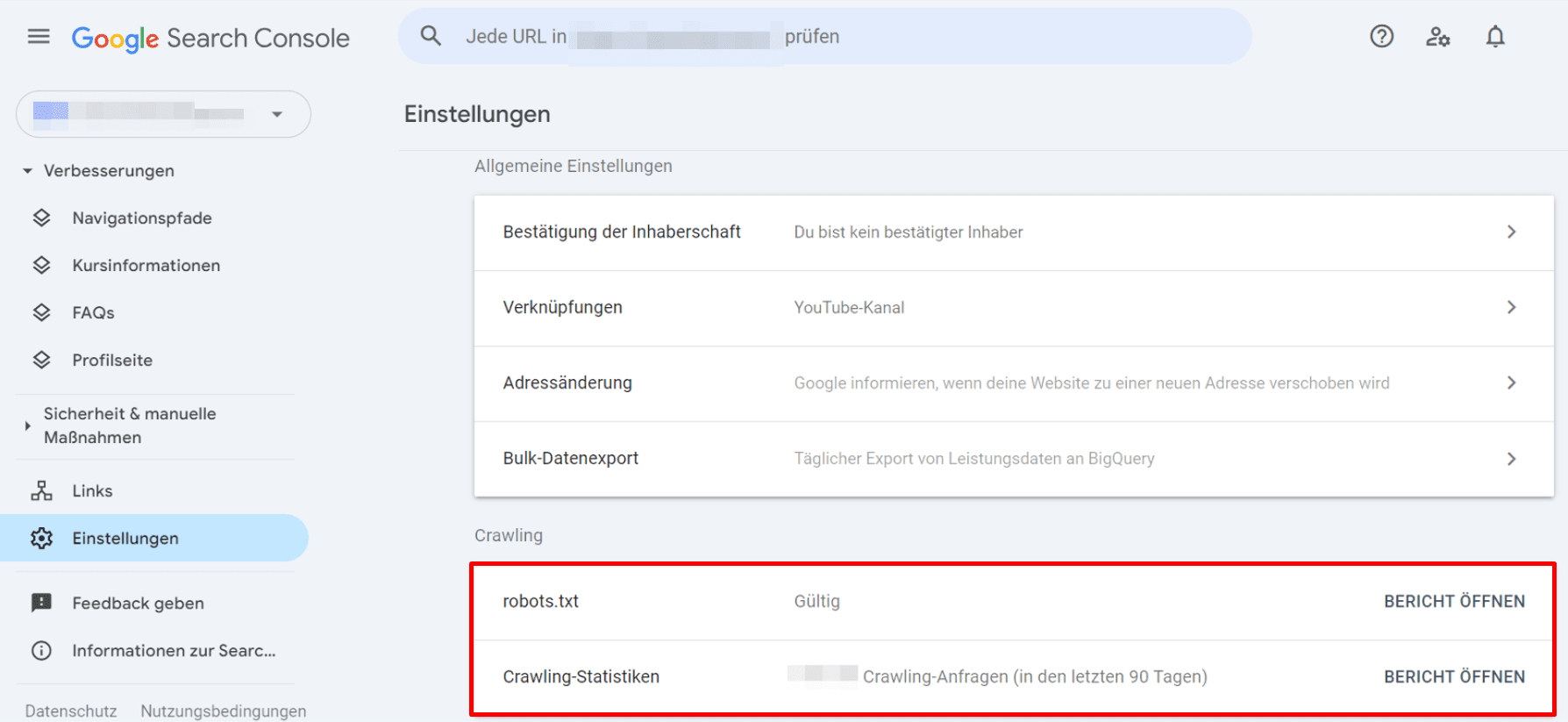
Das Öffnen eines robots.txt-Berichts zeigt die robots.txt-Dateien, die Google für die 20 wichtigsten Hosts deiner Website gefunden hat. Du siehst, wann Google sie zuletzt überprüft hat, den Abrufstatus und eventuelle Probleme. Zudem kannst du diesen Bericht nutzen, um Google zu bitten, eine robots.txt-Datei schnell erneut zu crawlen, falls dies dringend erforderlich ist.
Häufige Probleme mit robots.txt und SEO
Während du die robots.txt-Datei deiner Website verwaltest, können verschiedene Probleme die Interaktion von Suchmaschinen-Crawlern mit deiner Website beeinträchtigen. Zu den häufigsten Problemen gehören:
- Falsches Format: Web-Crawler können die Datei nicht erkennen und analysieren, wenn sie nicht im .txt-Format erstellt wurde.
- Falsche Platzierung: Deine robots.txt-Datei sollte sich im Stammverzeichnis befinden. Wenn sie beispielsweise in einem Unterordner liegt, können Suchbots sie möglicherweise nicht finden und darauf zugreifen.
- Fehlerhafte Verwendung von „/“ in der Disallow-Direktive: Eine Disallow-Direktive ohne Inhalt erlaubt Bots den Zugriff auf alle Seiten deiner Website. Eine Disallow-Direktive mit „/“ sperrt deine gesamte Website für Bots. Überprüfe deine robots.txt-Datei stets sorgfältig, um sicherzustellen, dass die Disallow-Direktiven deinen Absichten entsprechen.
- Leere Zeilen in der robots.txt-Datei: Achte darauf, dass zwischen den Direktiven keine leeren Zeilen vorhanden sind, da Web-Crawler sonst Schwierigkeiten haben könnten, die Datei zu analysieren. Leere Zeilen sind nur zulässig, bevor ein neuer User-Agent angegeben wird.
- Seite in robots.txt blockieren und gleichzeitig eine „noindex“-Direktive hinzufügen: Dies erzeugt widersprüchliche Signale. Suchmaschinen könnten die Absicht nicht verstehen oder die „noindex“-Anweisung vollständig ignorieren. Es ist besser, entweder robots.txt zu verwenden, um das Crawlen zu blockieren, oder „noindex“, um das Indexieren zu verhindern – jedoch nicht beides gleichzeitig.
Zusätzliche Tools/Berichte zur Überprüfung von Problemen
Es gibt viele Möglichkeiten, deine Website auf mögliche Probleme mit der robots.txt-Datei zu überprüfen. Hier sind die am häufigsten genutzten:
1. Google Search Console Seitenbericht
Der Bereich Seiten in der Google Search Console enthält wertvolle Informationen über deine robots.txt-Datei.
Um zu überprüfen, ob die robots.txt-Datei deiner Website Googlebot daran hindert, eine Seite zu crawlen, gehe wie folgt vor:
- Rufe den Bereich Seiten auf und navigiere zur Kategorie Nicht indexiert.
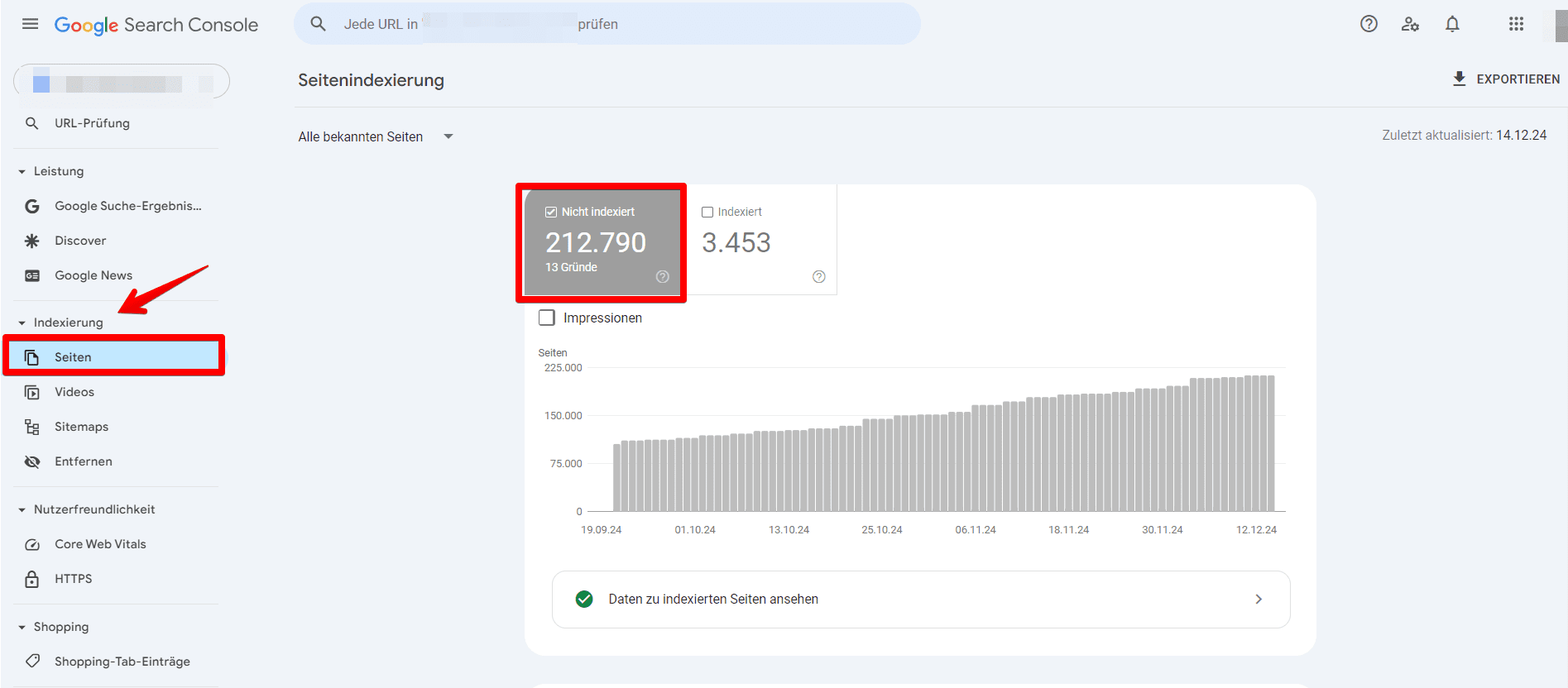
- Suche nach dem Fehler mit der Bezeichnung Durch robots.txt blockiert und wähle ihn aus.
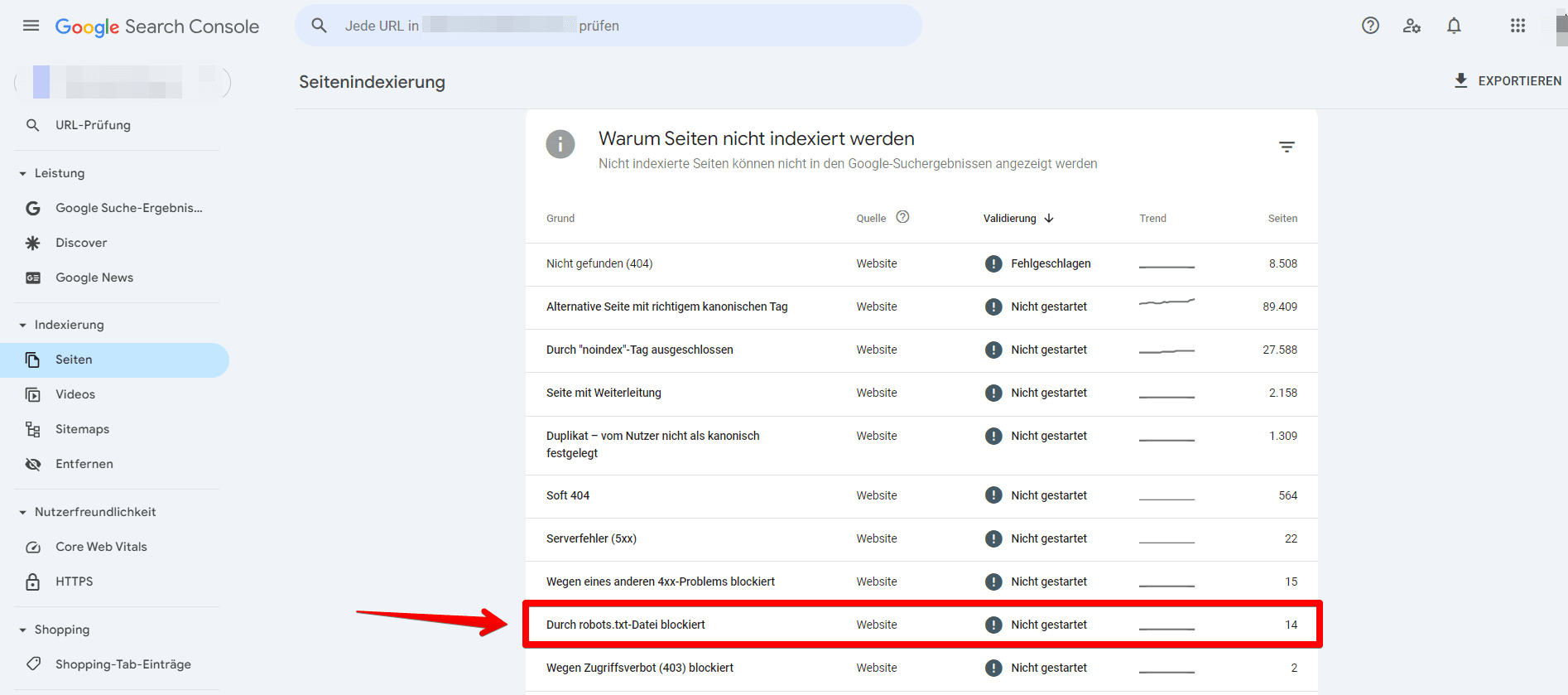
- Klick auf diesen Bereich zeigt dir eine Liste der Seiten, die derzeit durch die robots.txt-Datei deiner Website blockiert werden. Stelle sicher, dass dies die beabsichtigten blockierten Seiten sind.
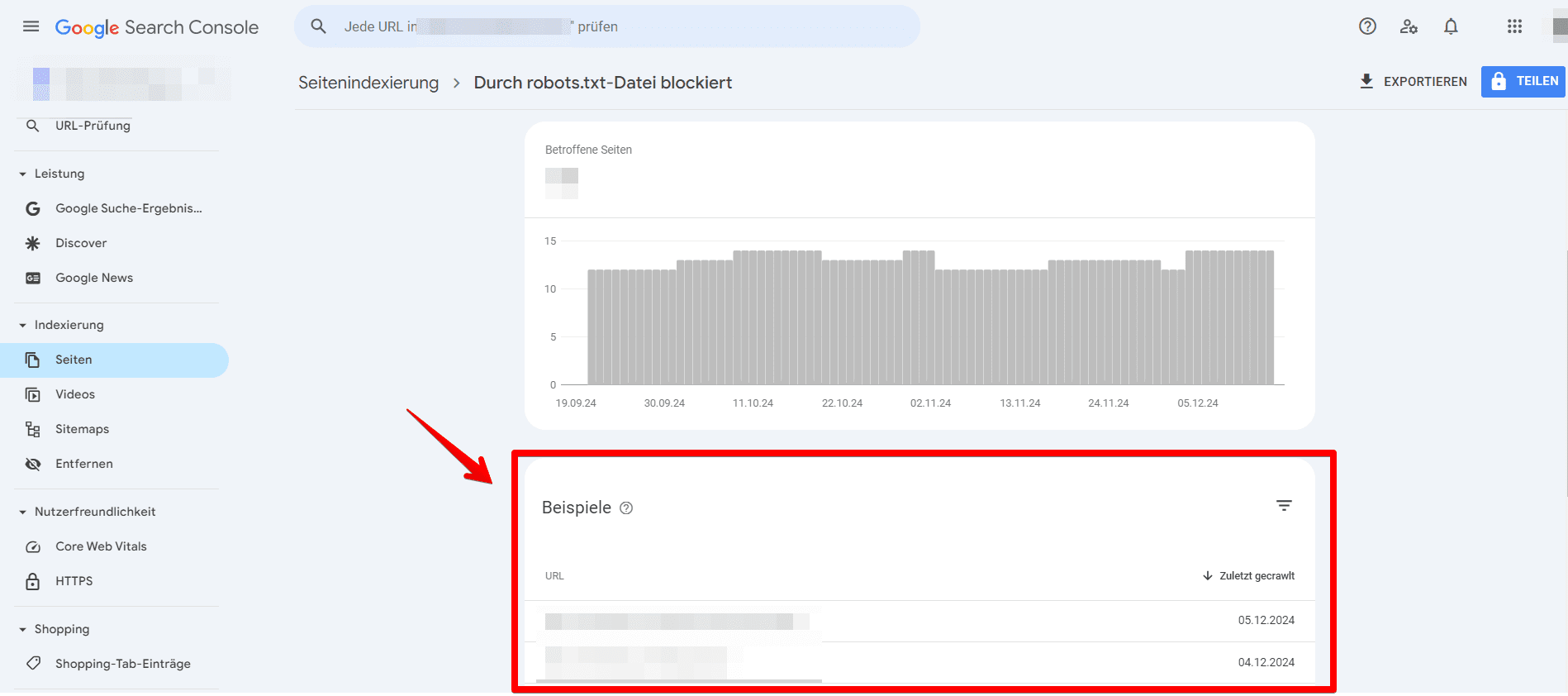
Überprüfe außerdem, ob in diesem Bereich das folgende Problem vorliegt: Indexiert, obwohl durch robots.txt blockiert.
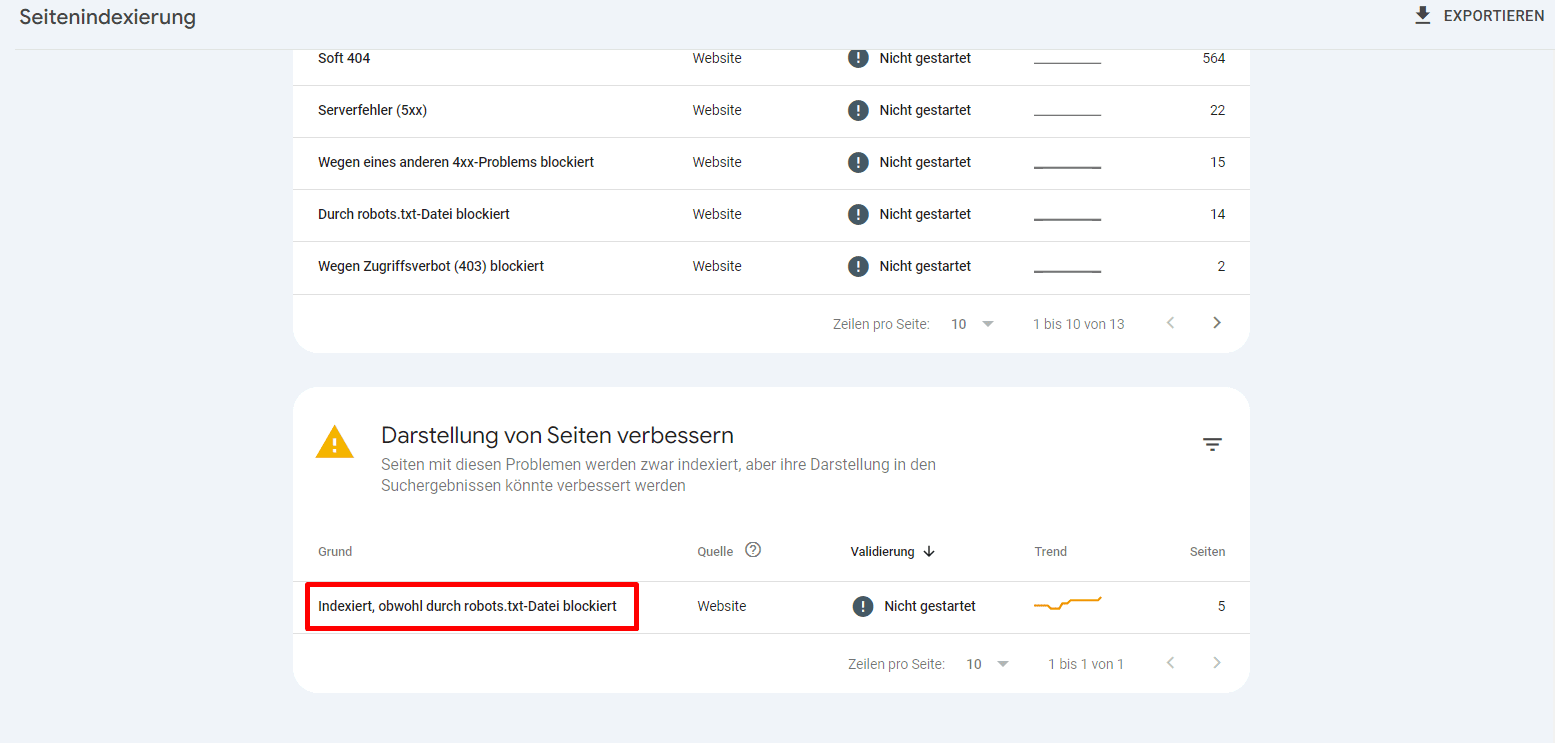
Du kannst auch prüfen, ob einzelne URLs indexiert sind, indem du sie in das Suchfeld des URL-Inspektionstools in der Google Search Console einfügst. Dies kann dir helfen, potenzielle Indexierungsprobleme zu erkennen, die durch widersprüchliche Direktiven oder falsch konfigurierte robots.txt-Regeln verursacht werden.
2. Website-Audit von SE Ranking
Das Website-Audit-Tool von SE Ranking (und ähnliche Tools) bietet einen umfassenden Überblick über deine robots.txt-Datei, einschließlich Informationen über Seiten, die durch die Datei blockiert sind. Es hilft dir auch, Indexierungs- und XML-Sitemap-bezogene Probleme zu identifizieren.
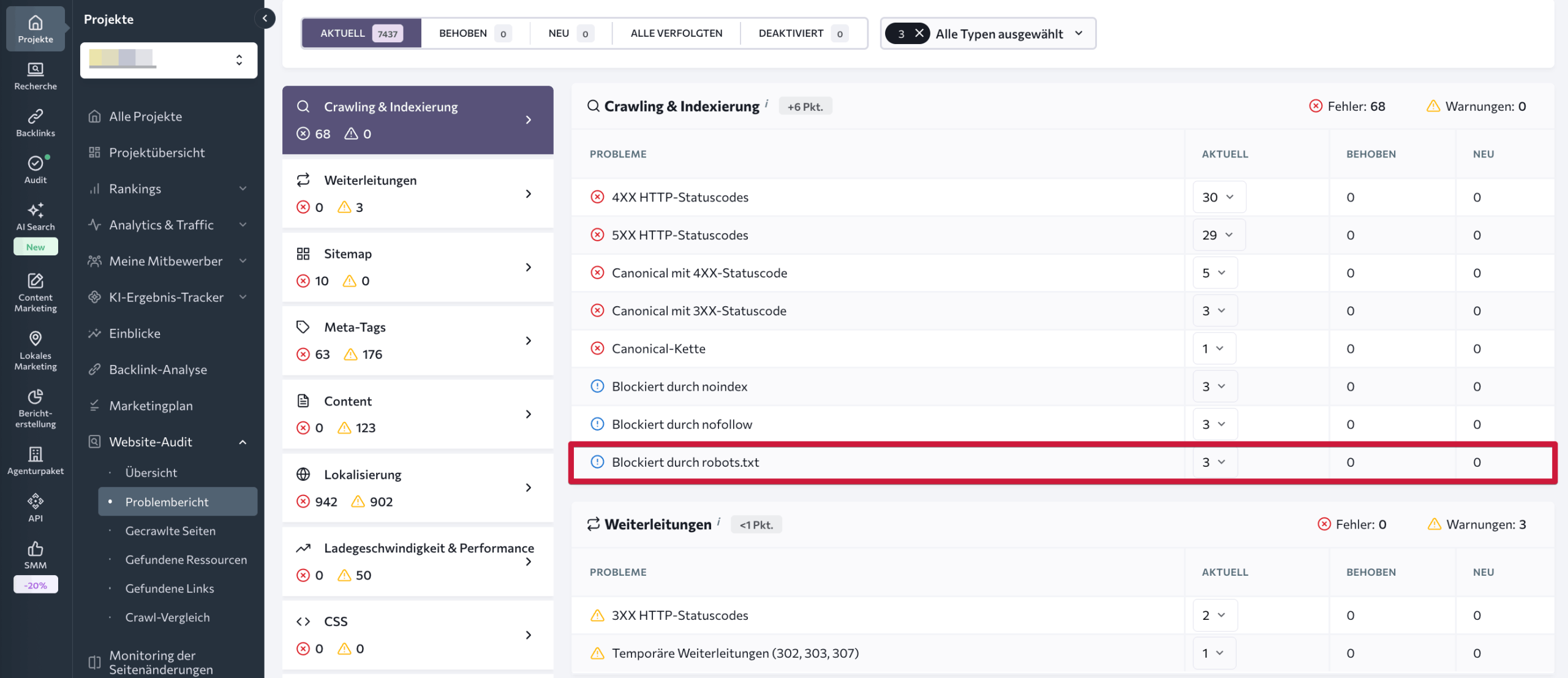
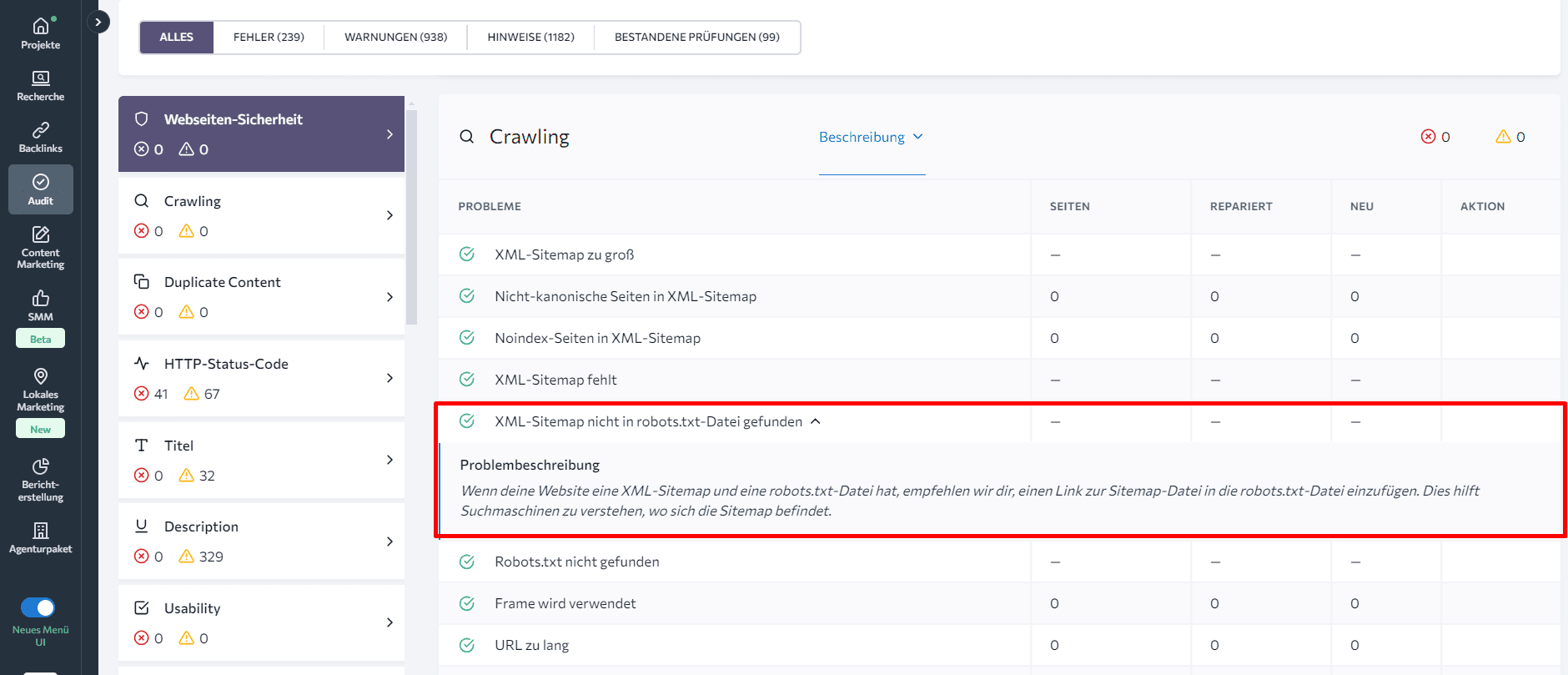
Um wertvolle Einblicke in deine robots.txt-Datei zu erhalten, beginne mit der Analyse des Problemberichts, den das Tool generiert. Unter den über 120 analysierten Metriken findest du den Parameter Durch robots.txt blockiert im Abschnitt Crawling. Ein Klick darauf zeigt eine Liste der vom Crawling blockierten Webseiten sowie Problembeschreibungen und Tipps zur schnellen Behebung.
Mit diesem Tool kannst du außerdem leicht überprüfen, ob du einen Link zur Sitemap-Datei in der robots.txt-Datei hinzugefügt hast. Kontrolliere einfach den Status XML-Sitemap nicht in robots.txt-Datei gefunden im selben Abschnitt.
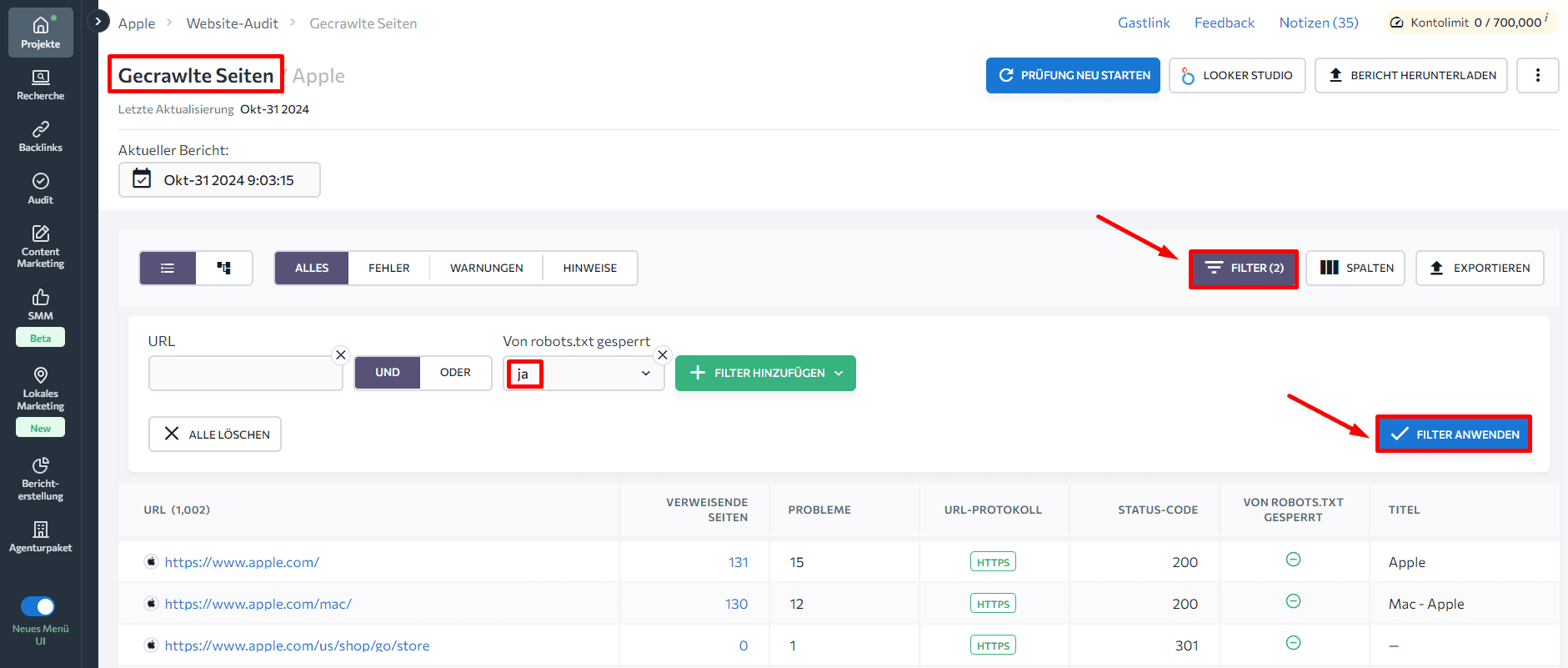
Wenn du im Menü auf der linken Seite zum Tab Gecrawlte Seiten navigierst, kannst du die technischen Parameter jeder Seite einzeln analysieren. Wende Filter an, um dich auf die Lösung kritischer Probleme auf den wichtigsten Seiten zu konzentrieren. Zum Beispiel zeigt der Filter Durch robots.txt blockiert > Ja alle Seiten, die durch die Datei blockiert sind.
3. SE Ranking robots.txt-Generator und robots.txt-Tester
Der robots.txt-Generator von SE Ranking ermöglicht es dir, die Datei zu erstellen, ohne das Risiko einzugehen, dass ein Tippfehler deine Absichten zunichte macht. Gib die Pfade ein, die du erlauben oder sperren möchtest, bestimme, für welche Bots dieser Regelsatz gelten soll, und füge deine Sitemap hinzu. Du kannst auch alle Bild- und Dateiformate in die Regel einbeziehen.

Nutze fertige robots.txt-Vorlagen für die gängigsten CMS-Plattformen oder füge verbreitete Regelsätze hinzu, etwa das vollständige Sperren für die am häufigsten blockierten Bots.

Benutzerdefinierte Regeln lassen sich jederzeit ergänzen.Wenn du deine robots.txt-Datei testen möchtest, nutze den robots.txt-Tester von SE Ranking. Gib deine Website ein, und das Tool zeigt dir die Datei an und prüft sie auf Inkonsistenzen. Du kannst auch die Direktiven für eine bestimmte URL deiner Website überprüfen. Das Tool gibt an, ob die URL für einen gewählten User-Agent erlaubt oder gesperrt ist.
SEO Best Practices
Um sicherzustellen, dass Web-Crawler die Inhalte deiner Website korrekt indexieren und sie optimal performt, solltest du diese SEO-Best Practices befolgen:
- Achte auf korrekte Groß- und Kleinschreibung in der robots.txt-Datei: Web-Crawler interpretieren Ordner- und Abschnittsnamen case-sensitiv. Die richtige Schreibweise ist entscheidend, um Verwirrung zu vermeiden und ein genaues Crawling und Indexieren zu gewährleisten.
- Beginne jede Anweisung in einer neuen Zeile, mit nur einem Parameter pro Zeile.
- Vermeide Leerzeichen, Anführungszeichen oder Semikolons beim Schreiben von Anweisungen.
- Verwende die Disallow-Direktive, um alle Dateien innerhalb eines bestimmten Ordners oder Verzeichnisses vom Crawling auszuschließen. Diese Methode ist effizienter, als jede Datei einzeln aufzulisten.
- Setze Wildcard-Zeichen für flexiblere Anweisungen in der robots.txt-Datei ein. Das Sternchen (*) steht für beliebige Variationen, während das Dollarzeichen ($) das Ende des URL-Pfads kennzeichnet.
- Erstelle eine separate robots.txt-Datei für jede Domain. So werden Crawl-Richtlinien für jede Website individuell festgelegt.
- Teste immer eine robots.txt-Datei, um sicherzustellen, dass wichtige URLs nicht blockiert werden.
Fazit
Wir haben alle wichtigen Aspekte der robots.txt-Datei behandelt, von der Syntax über Best Practices bis hin zu häufigen Fehlern. Eine korrekt konfigurierte robots.txt-Datei ist kein Nice-to-have, sondern ein grundlegendes Element im technischen SEO: Sie optimiert das Crawl-Budget, lenkt Suchmaschinen auf die wichtigsten Inhalte und schützt sensible Bereiche deiner Website.
Überprüfe und aktualisiere die Datei regelmäßig, wenn deine Website wächst oder sich verändert. Die Tools und Methoden, die wir vorgestellt haben, helfen dir dabei, sicherzustellen, dass deine robots.txt-Datei immer das tut, was sie soll.

