Duplicate Content: Tipps zum Finden und Beheben
Einfach zu erstellen, schwer loszuwerden und äußerst schädlich für deine Website – das ist Duplicate Content in Kürze. Aber wie stark schadet Duplicate Content tatsächlich der SEO? Was sind die technischen und nicht-technischen Ursachen für Duplicate Content? Und wie kannst du ihn schnell erkennen und beheben? Lies weiter, um Antworten auf diese und weitere wichtige Fragen zu erhalten.
Was ist Duplicate Content?
Duplicate Content ist im Grunde kopierter, recycelter (oder leicht veränderter), geklonter oder wiederverwendeter Inhalt, der für Nutzer wenig bis gar keinen Mehrwert bietet und Suchmaschinen verwirrt. Inhalte werden am häufigsten entweder innerhalb einer einzelnen Website oder über verschiedene Domains hinweg dupliziert.
Hierbei handelt es sich um mehrere URLs auf deiner Website, die denselben Inhalt anzeigen (oft unbeabsichtigt). Solche Inhalte können folgende Formen annehmen:
- Wiederveröffentlichte alte Blogbeiträge ohne zusätzlichen Mehrwert
- Seiten mit identischen oder leicht abgeänderten Inhalten
- Aggregierte oder kopierte Inhalte aus anderen Quellen
- KI-generierte Seiten mit schlecht umgeschriebenem Text
Hier bedeutet es, dass Inhalte auf mehreren externen Seiten identisch oder ähnlich sind. Beispiele hierfür:
- Kopierte oder gestohlene Inhalte, die auf anderen Seiten veröffentlicht werden
- Inhalte, die ohne Genehmigung verbreitet werden
- Identische oder kaum bearbeitete Inhalte auf konkurrierenden Websites
- Umschriebene Artikel, die auf mehreren Websites verfügbar sind
Schadet Duplicate Content der SEO?
Die kurze Antwort? Ja, das tut er. Aber der Einfluss von Duplicate Content auf die SEO hängt stark vom Kontext und den technischen Parametern der betreffenden Seite ab.
Duplicate Content auf deiner Website – zum Beispiel sehr ähnliche Blogbeiträge oder Produktseiten – kann laut Suchmaschinen den Wert und die Autorität dieser Inhalte mindern. Der Grund dafür ist, dass Suchmaschinen Schwierigkeiten haben, herauszufinden, welche Seite höher ranken sollte. Zudem sind Nutzer frustriert, wenn sie auf deiner Seite nichts Nützliches finden.
Andererseits, wenn eine andere Website deine Inhalte ohne Erlaubnis übernimmt oder kopiert (und du deine Inhalte nicht syndizierst), wird dies wahrscheinlich nicht direkt die Leistung oder Sichtbarkeit deiner Seite in den Suchergebnissen beeinträchtigen. Solange deine Inhalte die Originalversion sind, qualitativ hochwertig sind und du sie im Laufe der Zeit leicht anpasst, werden Suchmaschinen deine Seiten weiterhin als Original identifizieren. Die kopierende Seite könnte etwas Traffic abgreifen, wird aber laut Google-Erklärungen mit hoher Wahrscheinlichkeit nicht dein Original in den SERPs überholen.
Wie Google mit Duplicate Content umgeht
Obwohl Google offiziell sagt: „Es gibt keine ‚Duplicate Content Penalty“, gibt es immer einige Einschränkungen, die zwischen den Zeilen gelesen werden müssen. Selbst wenn es keine direkte Strafe gibt, kann Duplicate Content deine SEO auf indirekte Weise schädigen.
Google sieht es speziell als Warnsignal, wenn Inhalte absichtlich von anderen Websites kopiert und ohne neuen Mehrwert veröffentlicht werden. Google bemüht sich, die Originalversion unter ähnlichen Seiten zu identifizieren und diese zu indexieren. Alle Seiten werden Schwierigkeiten haben, gut zu ranken. Dies bedeutet, dass Duplicate Content zu niedrigeren Rankings, reduzierter Sichtbarkeit und weniger Traffic führen kann.
Ein weiteres „No-Go“ ist der Versuch, zahlreiche Seiten, Subdomains oder Domains mit auffallend ähnlichen Inhalten zu erstellen. Dies kann ein weiterer Grund sein, warum die SEO-Leistung nachlässt.
Zudem ist zu bedenken, dass jede Suchmaschine im Wesentlichen ein Unternehmen ist. Und wie jedes Unternehmen möchte auch Google seine Ressourcen nicht verschwenden. Daher gibt es ein Crawling-Budget für jede Website – eine Begrenzung der Webressourcen, die Suchmaschinen-Roboter crawlen und indexieren. Das Crawling-Budget des Googlebots wird schneller aufgebraucht, wenn er mehr Zeit und Ressourcen für jede doppelte Seite aufwenden muss. Dadurch sinken die Chancen, dass der Bot den Rest deiner Inhalte erreicht.
Ein weiterer kritischer Fall ist das erneute Posten von Affiliate-Inhalten von Amazon oder anderen Websites ohne wesentlichen einzigartigen Mehrwert. Indem du genau die gleichen Listings anbietest, überlässt du es Google, diese Probleme mit Duplicate Content zu lösen. Google wird dann die notwendigen Anpassungen bei der Indexierung und dem Ranking vornehmen, so gut es geht.
Dies zeigt, dass gut gemeinte Website-Betreiber von Google nicht bestraft werden, wenn sie auf technische Probleme stoßen, solange sie nicht absichtlich versuchen, Suchergebnisse zu manipulieren.
Wenn du also Duplicate Content nicht absichtlich erzeugst, bist du auf der sicheren Seite. Außerdem sagte Matt Cutts über Googles Sichtweise auf Duplicate Content: „Etwa 25 bis 30 % aller Webinhalte sind Duplicate Content.“ Wie immer gilt: Halte dich an die goldene Regel und erstelle einzigartige und wertvolle Inhalte, um bessere Nutzererfahrungen und Suchmaschinenleistungen zu gewährleisten.
Duplizierte und KI-generierte Inhalte
Ein weiteres wachsendes Problem, das heutzutage zu beachten ist, sind Inhalte, die mit KI-Tools erstellt werden. Diese können schnell zu einer Mine von duplizierten Inhalten werden, wenn du nicht vorsichtig bist. Eines ist klar: KI-generierte Inhalte fassen im Wesentlichen Informationen aus anderen Quellen zusammen, ohne neuen Mehrwert zu schaffen. Wenn du KI-Tools unüberlegt einsetzt, einfach eine Eingabe machst und das Ergebnis kopierst, solltest du dich nicht wundern, wenn dies als duplizierter Inhalt gekennzeichnet wird, der deine SEO-Leistung beeinträchtigt. Denke auch daran, dass Konkurrenten ähnliche Eingaben verwenden können, um sehr ähnliche Inhalte zu erzeugen.
Selbst wenn solche KI-Inhalte technisch gesehen Plagiatsprüfungen bestehen (bei Überprüfung durch spezielle Tools), ist Google in der Lage, Texte zu erkennen, die nur wenig Mehrwert, Expertise oder originelle Erfahrungen bieten, gemäß den EEAT-Standards. Obwohl dies keine direkte Strafe darstellt, solltest du wissen, dass rein KI-generierte Inhalte es schwerer haben könnten, in Suchergebnissen gut abzuschneiden, da ihre repetitive Natur mit der Zeit auffällt.
Um Duplicate Content und SEO-Probleme zu vermeiden, ist es entscheidend, sicherzustellen, dass alle Inhalte auf einer Website einzigartig und wertvoll sind. Dies lässt sich durch die Erstellung origineller Inhalte, die korrekte Verwendung von Canonical-Tags und das Vermeiden von Content Scraping oder anderen Black-Hat-SEO-Taktiken erreichen.
Beispielsweise kannst du mit dem On-Page-SEO-Tool von SE Ranking eine umfassende Analyse der Inhalts-Einzigartigkeit, der Keyword-Dichte, der Wortanzahl im Vergleich zu den bestplatzierten Wettbewerbsseiten sowie der Verwendung von Überschriften auf der Seite durchführen. Neben dem Inhalt selbst analysiert dieses Tool wichtige On-Page-Elemente wie Titel-Tags, Meta-Beschreibungen, Überschriften-Tags, interne Links, die URL-Struktur und Keywords. Durch den Einsatz dieses Tools kannst du Inhalte erstellen, die sowohl einzigartig als auch wertvoll sind.
Arten von Doppelten Inhalt
Es gibt zwei Hauptarten von Duplicate-Content-Problemen im SEO-Bereich:
- Website-übergreifender/Domänenübergreifender Duplicate Content
Duplicate Content kann entstehen, wenn Inhalte direkt an mehreren Stellen kopiert werden oder technische Probleme dazu führen, dass derselbe Inhalt unter verschiedenen URLs angezeigt wird. Beispiele hierfür sind das Fehlen von Canonical-Tags bei URLs mit Parametern, doppelte Seiten ohne die noindex-Direktive und kopierte Inhalte, die ohne ordnungsgemäße Weiterleitung veröffentlicht werden. Ohne eine korrekte Einrichtung von Canonical-Tags oder Weiterleitungen können Suchmaschinen nahezu identische Versionen von Seiten indexieren und versuchen, diese zu ranken.
- Kopierter Inhalt/Technische Probleme
Duplicate Content kann entstehen, wenn Inhalte direkt an mehreren Stellen kopiert werden oder technische Probleme dazu führen, dass derselbe Inhalt unter verschiedenen URLs angezeigt wird. Beispiele hierfür sind:
- Fehlende Canonical-Tags auf URLs mit Parametern
- Doppelte Seiten ohne die „noindex“-Anweisung
- Kopierte Inhalte, die ohne korrekte Weiterleitung veröffentlicht werden
Ohne eine ordnungsgemäße Einrichtung von Canonical-Tags oder Weiterleitungen können Suchmaschinen nahezu identische Versionen von Seiten indexieren und versuchen, diese zu ranken.
Wie überprüft man Duplicate-Content-Probleme?
Um Doppelten-Inhalt-Probleme zu erkennen, sollten zunächst die verschiedenen Methoden zur Überprüfung definiert werden. Wenn du dich auf Probleme innerhalb einer Domain konzentrierst, kannst du folgende Tools verwenden:
Website-SEO-Audit-Tool von SE Ranking: Dieses Tool hilft dir, alle Webseiten deiner Website zu finden, einschließlich der doppelten Inhalte. Im Abschnitt „Duplicate Content“ des Website-Audit-Tools findest du eine Liste der Seiten, die aufgrund technischer Gründe denselben Inhalt enthalten, z. B. URLs, die mit und ohne www oder mit und ohne abschließenden Slash zugänglich sind.
Wenn du Canonical-Tags verwendet hast, um das Duplikationsproblem zu lösen, dabei jedoch mehrere Canonical-URLs angegeben wurden, wird das Audit diesen Fehler ebenfalls hervorheben.
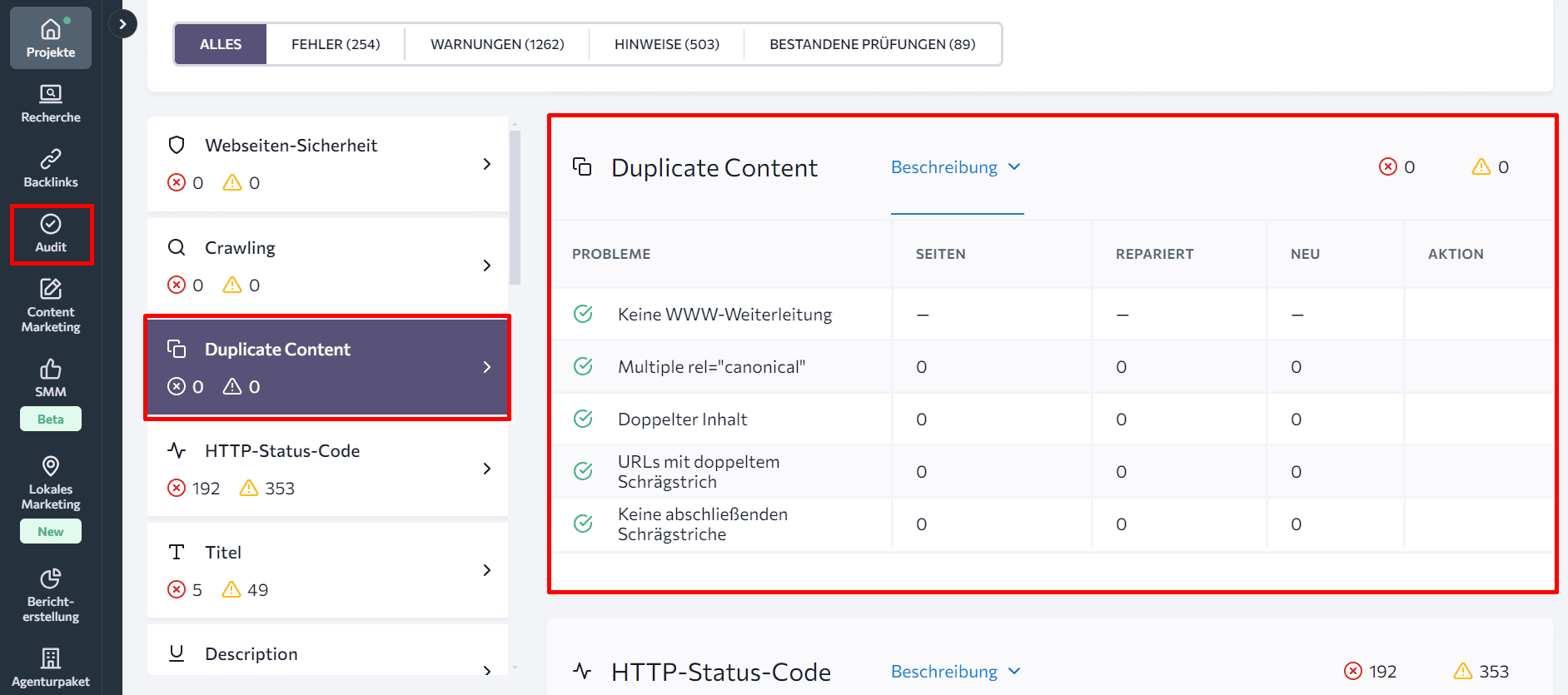
Als Nächstes sieh dir die Registerkarte “Gecrawlte Seiten” unten an. Du kannst weitere Anzeichen für Duplicate-Content-Probleme finden, indem du Seiten mit ähnlichen Titeln oder Überschriftentags überprüfst. Um einen Überblick zu erhalten, richte die Spalten ein, die du sehen möchtest.
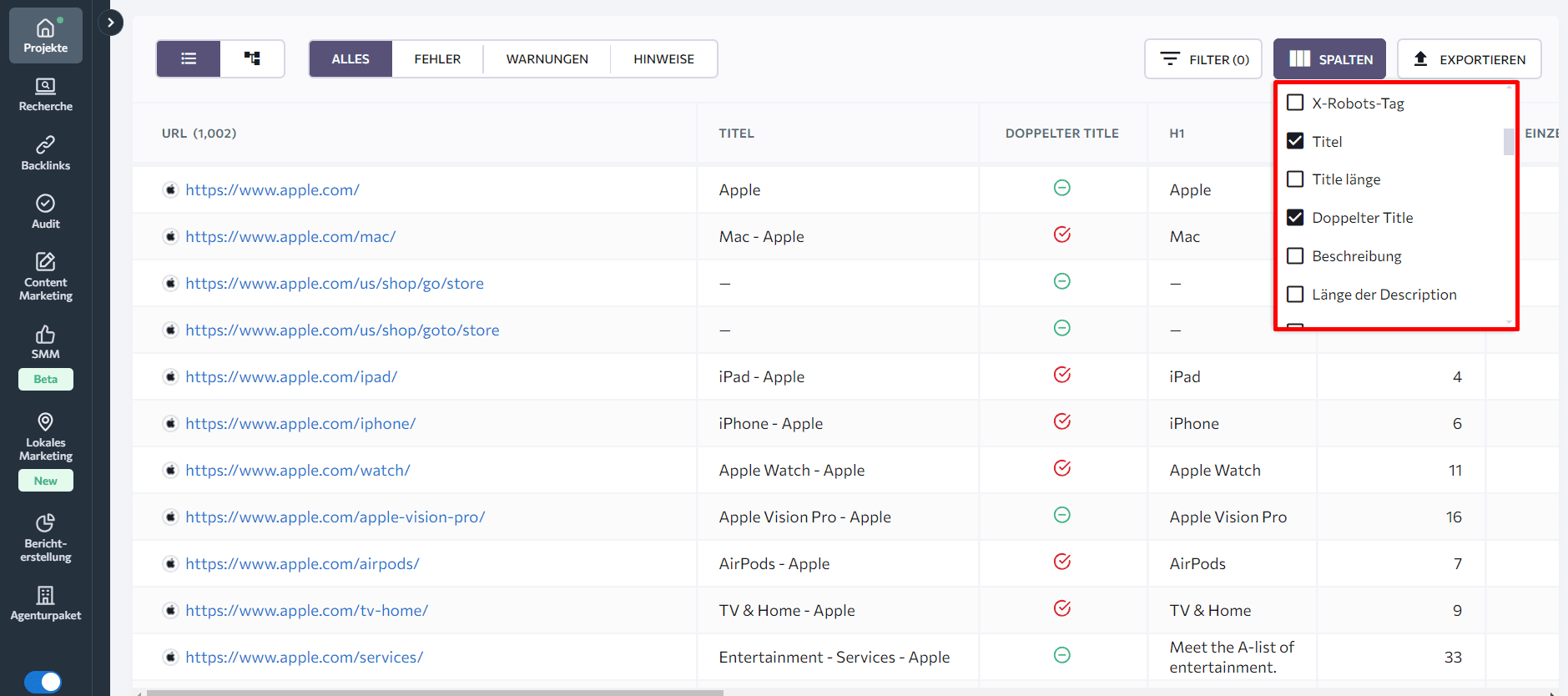
Um das beste Tool für deine Anforderungen zu finden, erkunde das Audit-Tool von SE Ranking und vergleiche es mit anderen Website-Audit-Tools.
Die Google Search Console kann dir ebenfalls dabei helfen, identische Inhalte zu finden.
- Im Reiter „Indexierung“ gehe zu „Seiten“.
- Achte auf die folgenden Probleme:
- Duplikat ohne benutzerdefiniertes Canonical: Google hat doppelte URLs gefunden, ohne dass eine bevorzugte Version festgelegt wurde. Verwende das URL-Inspektionstool, um herauszufinden, welche URL Google als canonical für diese Seite betrachtet. Dies ist kein Fehler – es passiert, weil Google bevorzugt, denselben Inhalt nicht doppelt anzuzeigen. Wenn du jedoch denkst, dass Google die falsche URL als canonical markiert hat, setze die Canonical-Auszeichnung deutlicher. Oder, falls du glaubst, dass diese Seite kein Duplikat der von Google ausgewählten Canonical-URL ist, stelle sicher, dass die beiden Seiten klar unterscheidbare Inhalte haben.
- Alternative Seite mit korrekt gesetztem Canonical-Tag: Google sieht diese Seite als Alternative zu einer anderen Seite. Es könnte sich um eine AMP-Seite mit einem Desktop-Canonical, eine mobile Version eines Desktop-Canonicals oder umgekehrt handeln. Diese Seite verweist auf die korrekte Canonical-Seite, die indexiert ist, sodass du nichts ändern musst. Beachte jedoch, dass die Search Console keine alternativen Sprachseiten erkennt.
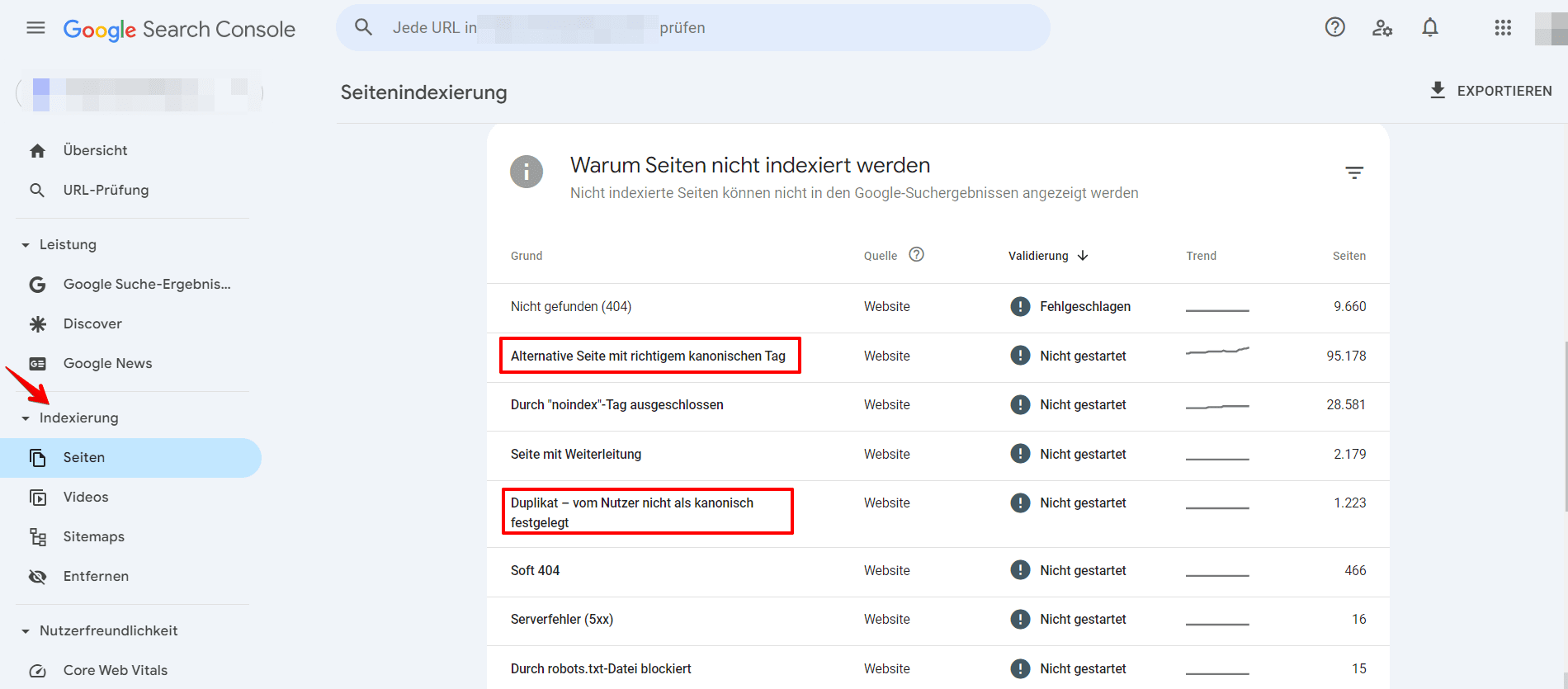
- Duplikat, Google hat ein anderes Canonical als der Nutzer gewählt: Google markiert diese Seite als die Canonical-Seite für eine Gruppe von Seiten, schlägt jedoch vor, dass eine andere URL als besser geeignete Canonical dienen würde. Google indexiert diese Seite selbst nicht, sondern diejenige, die es als Canonical betrachtet.
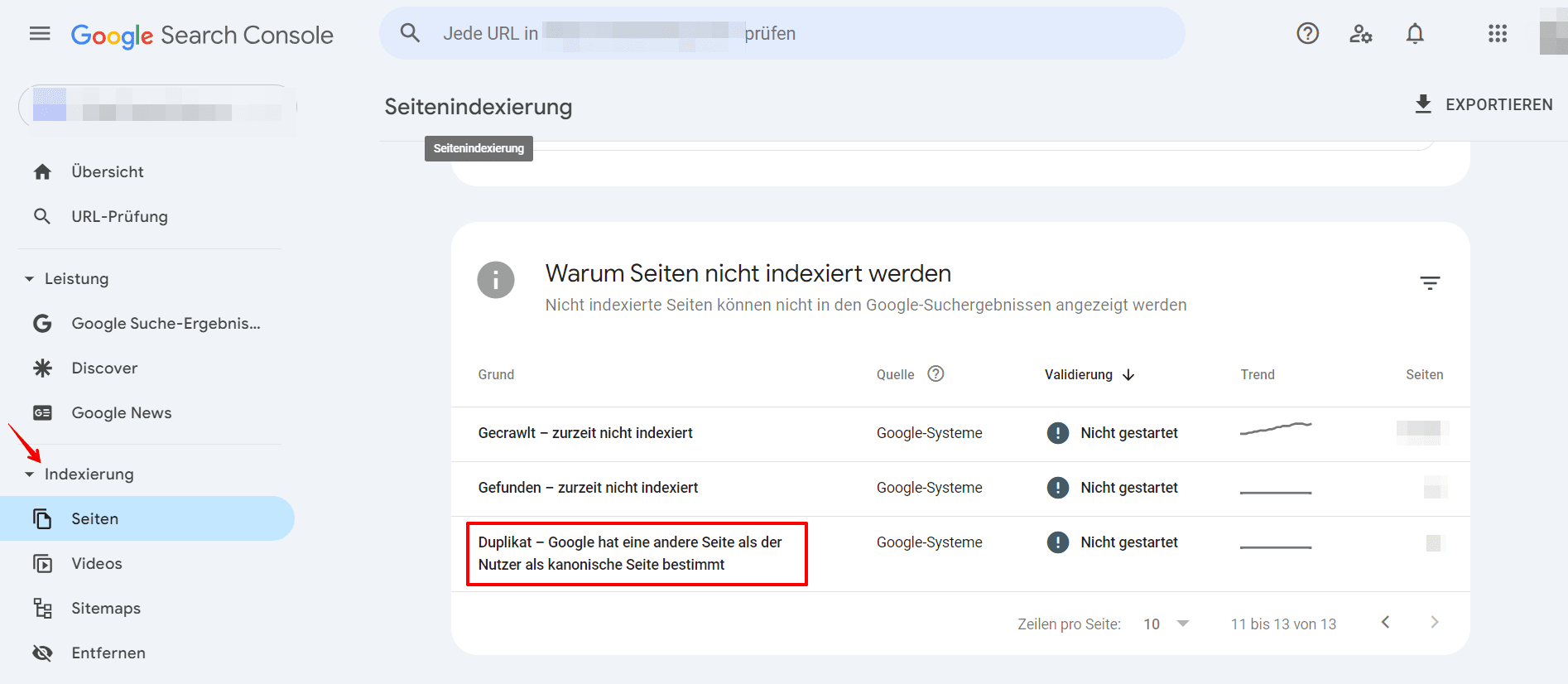
Wähle eine der unten aufgeführten Methoden, um Duplikationsprobleme über verschiedene Domains hinweg zu finden.
- Google-Suche verwenden: Suchoperatoren können sehr nützlich sein. Versuche, doppelten Inhalt zu finden, indem du ein Textfragment deiner Seite in Anführungszeichen in Google suchst. Dies ist hilfreich, da kopierte oder syndizierte Inhalte dein Original übertreffen können.
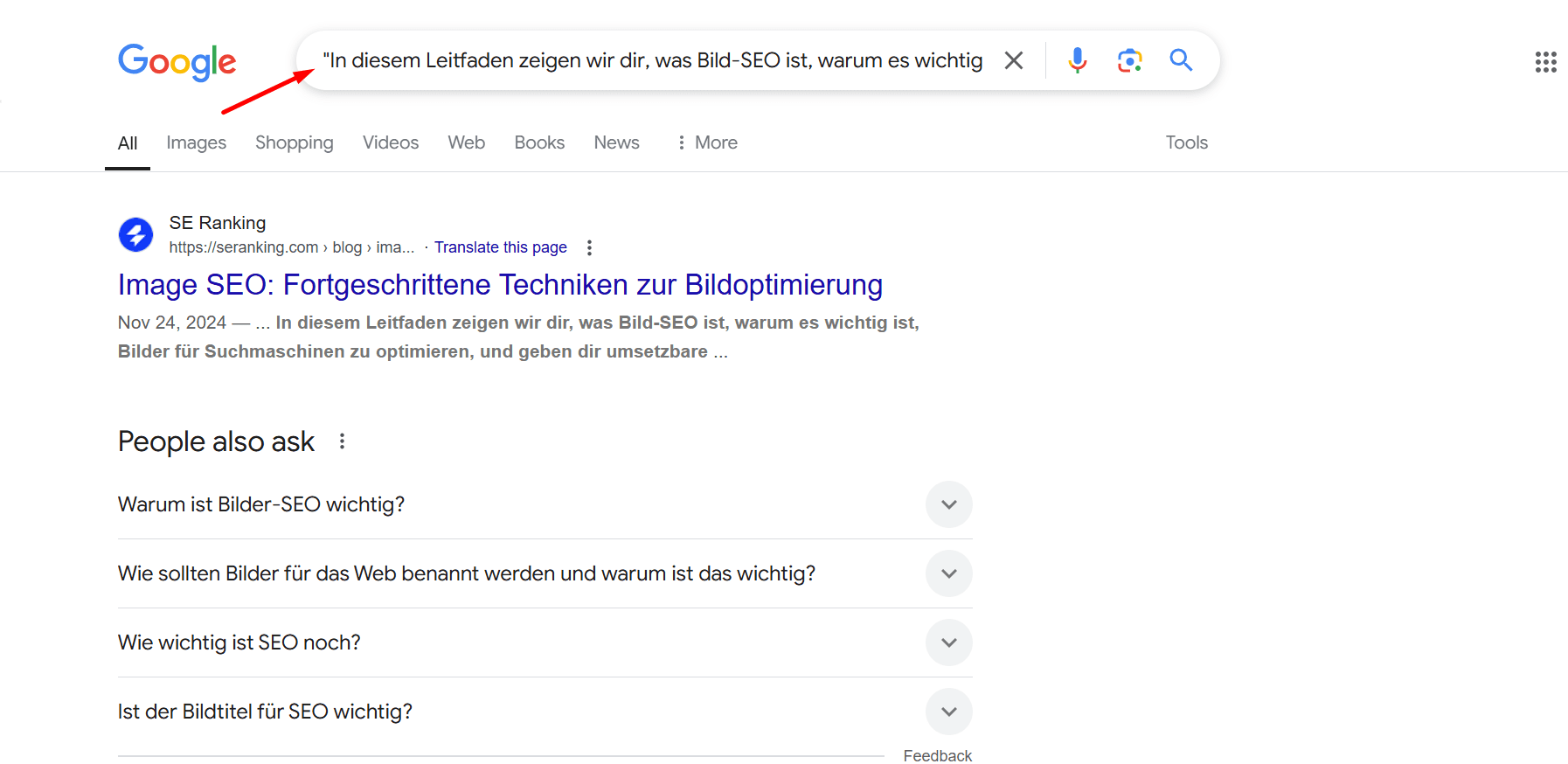
- Verwende den On-Page Checker, um Inhalte auf spezifischen URLs zu überprüfen: Dies verstärkt deine manuellen Content-Audit-Bemühungen. Das Tool bewertet deine Seite anhand von 94 Schlüsselparametern, einschließlich der Einzigartigkeit der Inhalte.
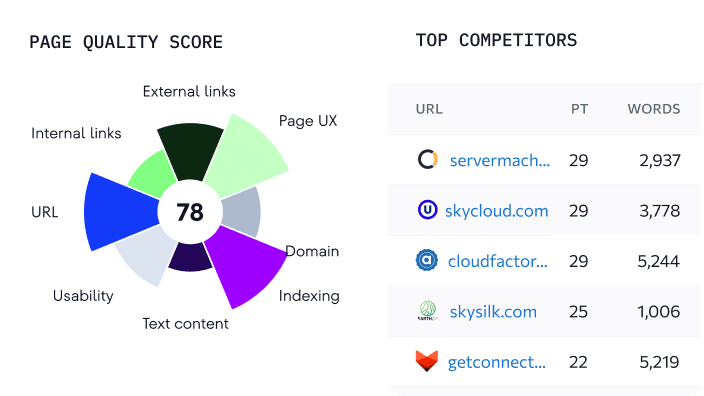
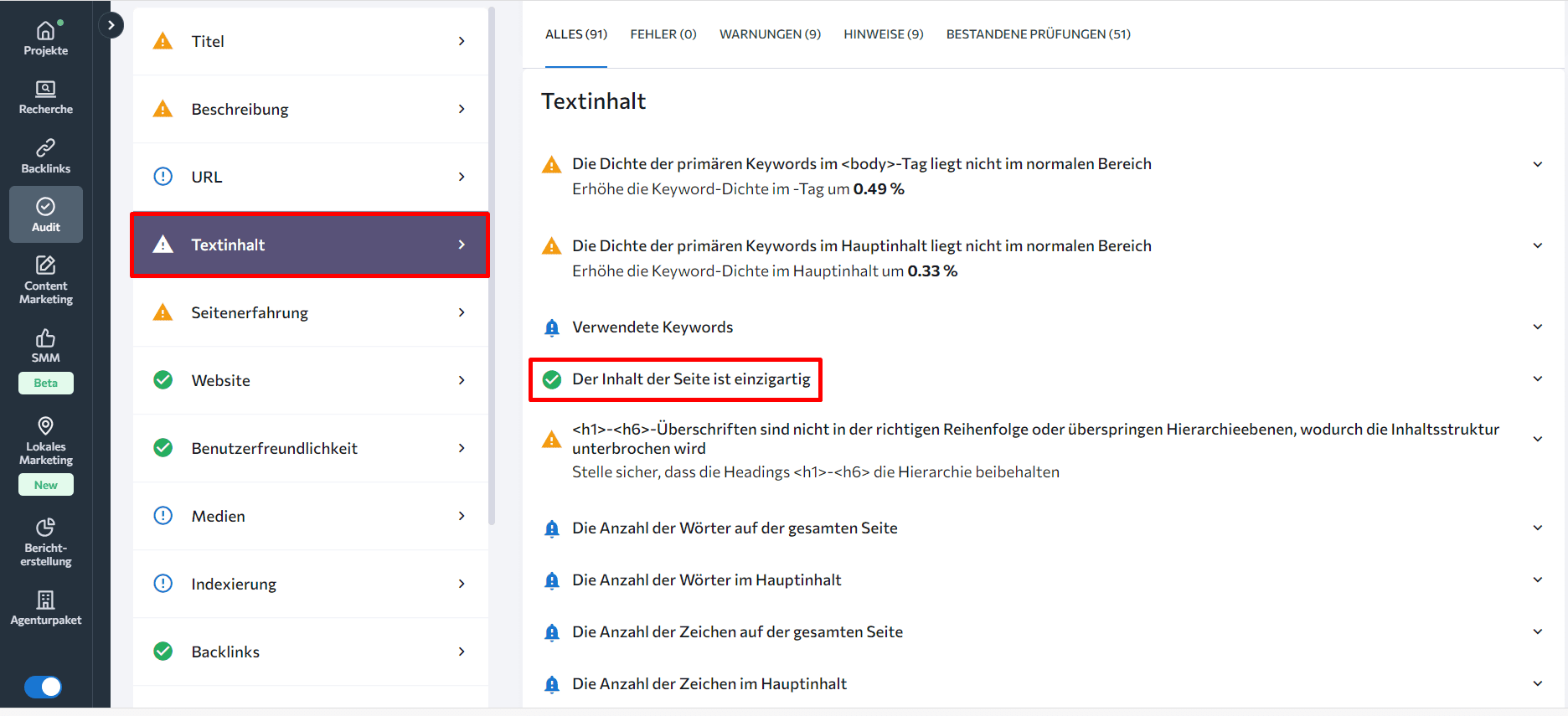
Um dies zu tun, scrolle im On-Page SEO Checker nach unten zum Reiter „Textinhalt“. Dort wird angezeigt, ob die Einzigartigkeit deiner Inhalte innerhalb des empfohlenen Bereichs liegt.
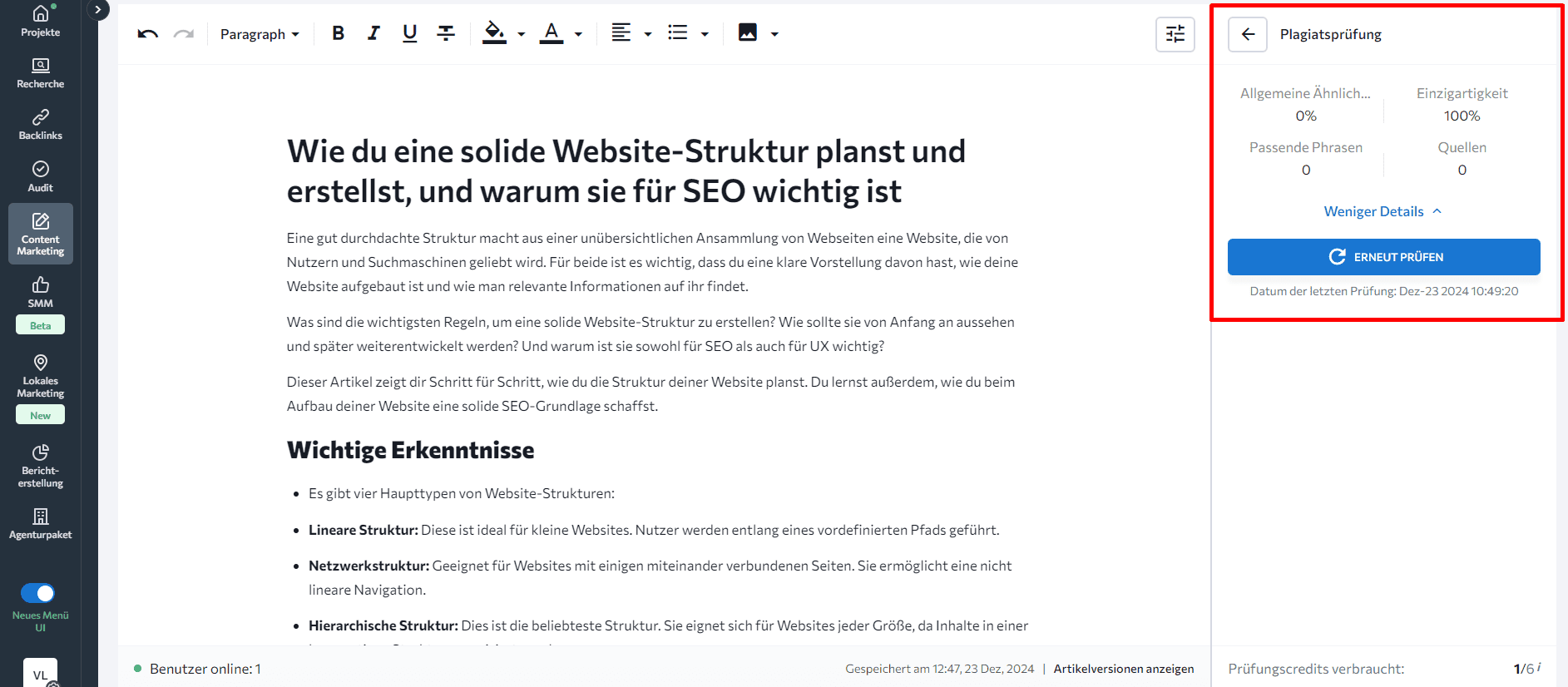
- Verwende das KI-gestützte Content Editor Tool von SE Ranking, um Zeit zu sparen. Es enthält einen integrierten Plagiatsprüfer, der deine Inhalte überprüft und mit einer großen Datenbank abgleicht, um zu bestätigen, dass es sich um die originale (nicht kopierte) Version handelt. Es zeigt den Prozentsatz der übereinstimmenden Wörter, wie einzigartig der Text ist, die Anzahl der Seiten mit Übereinstimmungen sowie die einzigartigen übereinstimmenden Phrasen bei allen Mitbewerbern.
Um zu starten, finde den Content Editor in der SE Ranking Plattform, klicke auf die Schaltfläche „Neuer Artikel“ und gib die Details zu deinem Artikel an.
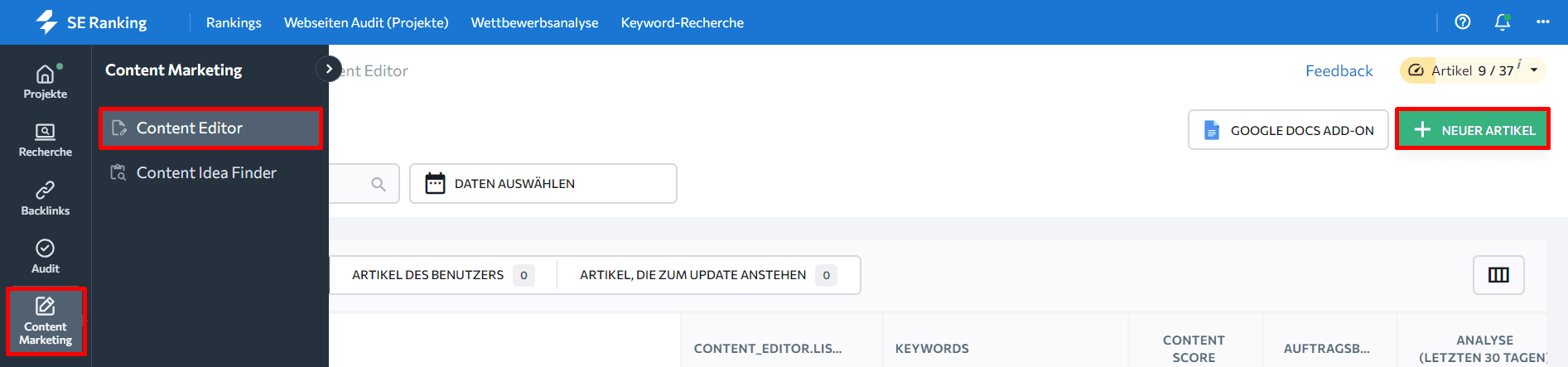
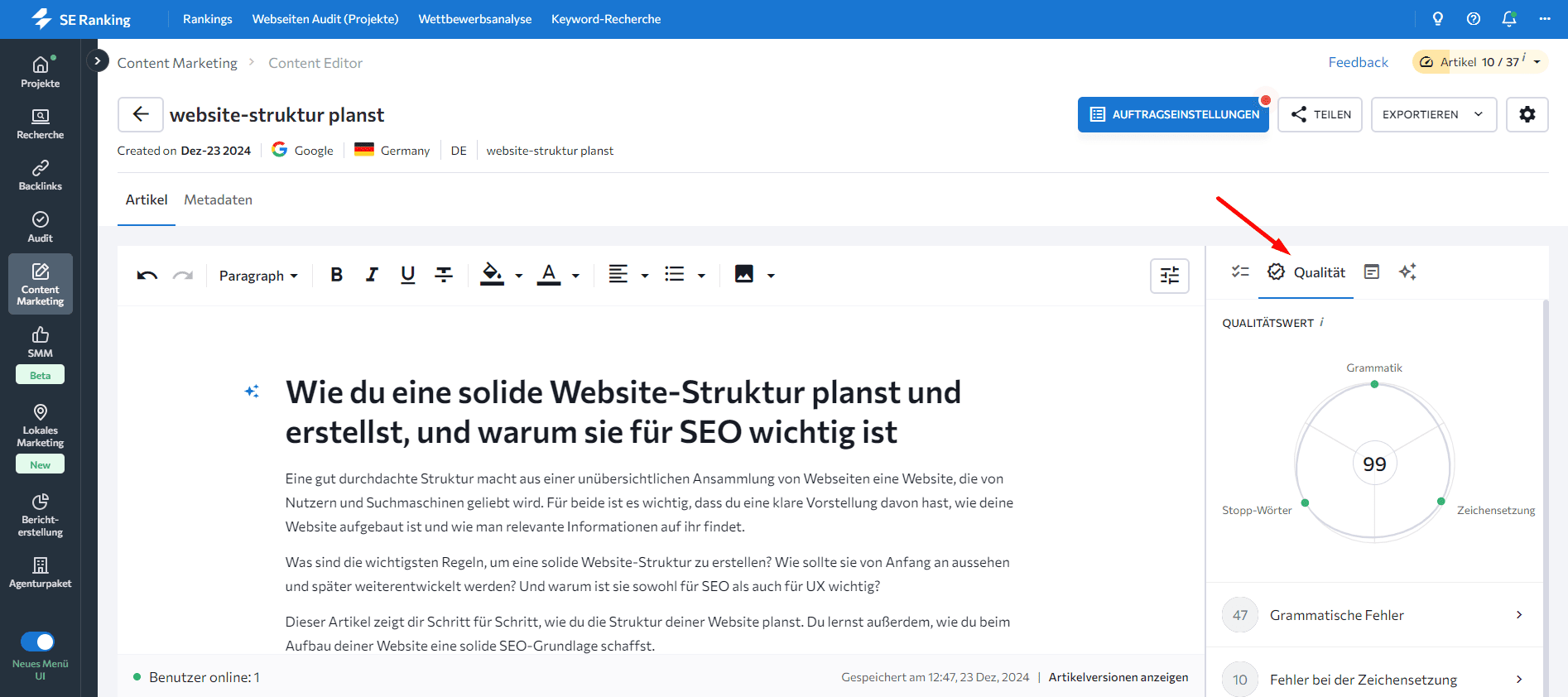
Füge deinen Artikel hinzu und öffne den Reiter „Qualität“ in der rechten Seitenleiste.
Scrolle zum Plagiatsprüfer herunter und sieh dir die Details an.
Die häufigsten technischen Gründe für Doppelten Inhalt
Wie bereits erwähnt, ist unabsichtlicher Duplicate Content in der SEO häufig und entsteht vor allem durch das Übersehen bestimmter technischer Faktoren. Nachfolgend findest du eine Liste dieser Probleme und deren Lösungen.
URL-Parameter
Duplicate Content tritt häufig auf, wenn derselbe oder sehr ähnlicher Inhalt über mehrere URLs zugänglich ist. Hier sind zwei häufige technische Ursachen dafür:
1. Filter- und Sortierparameter: Viele Websites verwenden URL-Parameter, um Nutzern zu helfen, Inhalte zu filtern oder zu sortieren. Dies kann dazu führen, dass mehrere Seiten mit demselben oder ähnlichem Inhalt, aber mit leichten Parametervariationen existieren. Zum Beispiel zeigen www.store.com/shirts?color=blue blaue Hemden und www.store.com/shirts?color=red rote Hemden. Während Nutzer die Seiten aufgrund ihrer Präferenzen unterschiedlich wahrnehmen könnten, interpretieren Suchmaschinen sie möglicherweise als identisch.
Filteroptionen können eine Vielzahl von Kombinationen erzeugen, insbesondere wenn es mehrere Auswahlmöglichkeiten gibt. Dies liegt daran, dass die Parameter neu angeordnet werden können. Dadurch würden die folgenden zwei URLs denselben Inhalt anzeigen:
- www.store.com/shirts?color=blue&sort=price-asc
- www.store.com/shirts?sort=price-asc&color=blue
Um Duplicate-Content-Probleme in der SEO zu verhindern und die Autorität der gefilterten Seiten zu stärken, solltest du Canonical-URLs für jede primäre, ungefilterte Seite verwenden. Beachte jedoch, dass dies das Problem des Crawling-Budgets nicht löst. Alternativ kannst du diese Parameter in deiner robots.txt-Datei blockieren, um Suchmaschinen daran zu hindern, gefilterte Versionen deiner Seiten zu crawlen.
2. Tracking-Parameter: Websites fügen oft Parameter wie „utm_source“ hinzu, um die Quelle des Traffics zu verfolgen, oder „utm_campaign“, um eine spezifische Kampagne oder Promotion zu identifizieren, sowie viele andere Parameter. Obwohl diese URLs einzigartig erscheinen mögen, bleibt der Inhalt auf der Seite identisch mit dem Inhalt der URLs ohne diese Parameter. Zum Beispiel:
www.example.com/services und www.example.com/services?utm_source=twitter
Alle URLs mit Tracking-Parametern sollten auf die Hauptversion (ohne diese Parameter) kanonisiert werden.
Suchergebnisse
Viele Websites haben Suchfelder, die es Nutzern ermöglichen, Inhalte auf der Website zu filtern und zu sortieren. Doch manchmal stößt man bei der Suche auf Inhalte auf der Ergebnisseite, die sehr ähnlich oder nahezu identisch mit den Inhalten anderer Seiten sind. Zum Beispiel: Wenn du auf unserem Blog nach „content“ suchst (https://seranking.com/blog/?s=content), sind die angezeigten Inhalte fast identisch mit den Inhalten unserer Kategorieseite (https://seranking.com/blog/category-content/).
Das liegt daran, dass die Suchfunktion versucht, relevante Ergebnisse basierend auf der Suchanfrage des Nutzers bereitzustellen. Wenn der Suchbegriff genau mit einer Kategorie übereinstimmt, können die Suchergebnisse Seiten aus dieser Kategorie enthalten. Dies kann zu Duplicate- oder Near-Duplicate-Content-Problemen führen.
Um Duplicate Content zu beheben, verwende noindex-Tags oder blockiere alle URLs, die Suchparameter enthalten, in deiner robots.txt-Datei. Diese Maßnahmen teilen den Suchmaschinen mit: „Überspringt meine Suchergebnisseiten, sie sind nur Duplikate.“ Websites sollten auch vermeiden, Links zu diesen Seiten zu setzen. Und da Suchmaschinen versuchen, Links zu crawlen, verhindert das Entfernen unerwünschter Links, dass sie die doppelten Seiten crawlen.
Lokalisierte Website-Versionen
Einige Websites haben länderspezifische Domains mit gleichen oder ähnlichen Inhalten. Zum Beispiel könntest du lokalisierte Inhalte für Länder wie die USA und Großbritannien haben. Da die Inhalte für jede Region ähnlich sind und nur geringe Unterschiede aufweisen, könnten die Versionen als Duplikate angesehen werden.
Dies ist ein klares Signal dafür, dass du hreflang-Tags einrichten solltest. Diese Tags helfen Google zu verstehen, dass es sich um lokalisierte Varianten desselben Inhalts handelt.
Auch wenn du Subdomains oder Ordner (anstelle von Domains) für deine mehrregionale Version verwendest, bleibt die Wahrscheinlichkeit, auf Duplikate zu stoßen, hoch. Daher ist es genauso wichtig, hreflang für beide Optionen zu verwenden.
Non-www vs. www
Websites sind manchmal unter zwei verschiedenen Versionen verfügbar: example.com und www.example.com. Obwohl sie zur gleichen Website führen, betrachten Suchmaschinen diese als unterschiedliche URLs. Dadurch werden Seiten sowohl von der www- als auch von der non-www-Version als Duplikate indexiert. Diese Duplikation teilt den Link- und Traffic-Wert, anstatt ihn auf eine bevorzugte Version zu konzentrieren. Außerdem führt dies zu wiederholten Inhalten in den Suchindizes.
Um dieses Problem zu lösen, sollten Websites eine 301-Weiterleitung von einem Hostnamen zum anderen einrichten. Das bedeutet, entweder die non-www-Version auf die www-Version umzuleiten oder umgekehrt, je nachdem, welche Version bevorzugt wird.
URLs mit abschließendem Slash
Web-URLs können manchmal einen abschließenden Slash enthalten:
- example.com/page/
Und manchmal wird der Slash weggelassen:
- example.com/page
Suchmaschinen behandeln diese als separate URLs, selbst wenn sie zur gleichen Seite führen. Wenn beide Versionen gecrawlt und indexiert werden, wird der Inhalt auf zwei unterschiedlichen URLs dupliziert.
Die beste Praxis ist, ein URL-Format (mit oder ohne abschließenden Slash) auszuwählen und es konsistent auf der gesamten Website zu verwenden. Konfiguriere deinen Webserver und die Hyperlinks so, dass das gewählte Format genutzt wird. Anschließend sollten 301-Weiterleitungen verwendet werden, um alle Relevanzsignale auf den ausgewählten URL-Stil zu konsolidieren.
Paginierung
Viele Websites teilen lange Inhaltslisten (z. B. Artikel oder Produkte) auf nummerierte Paginierungsseiten auf, wie:
- /articles/?page=2
- /articles/page/2
Es ist wichtig sicherzustellen, dass die Paginierung nicht über verschiedene URL-Typen zugänglich ist, wie /?page=2 und /page/2, sondern nur über eine der beiden (ansonsten werden sie als Duplikate betrachtet). Es ist auch ein häufiger Fehler, paginierte Seiten als Duplikate zu identifizieren, da Google sie nicht als solche betrachtet.
Tag- und Kategorieseiten
Websites zeigen häufig Produkte sowohl auf Tag- als auch auf Kategorieseiten an, um Inhalte nach Themen zu organisieren.
Beispiel:
- example.com/category/shirts/
- example.com/tag/blue-shirts/
Wenn die Kategorieseite und die Tag-Seite eine ähnliche Liste von T-Shirts anzeigen, wird derselbe Inhalt sowohl auf der Tag- als auch auf der Kategorieseite dupliziert.
Tags bieten in der Regel minimalen bis gar keinen Mehrwert für deine Website, daher ist es am besten, sie zu vermeiden. Stattdessen kannst du Filter oder Sortieroptionen hinzufügen, aber sei vorsichtig, da diese ebenfalls Duplikate verursachen können, wie oben erwähnt. Eine andere Lösung ist die Verwendung von noindex-Tags auf deinen Seiten. Beachte jedoch, dass Google sie trotzdem crawlen wird.
Indexierbare Staging-/Testumgebungen
Viele Websites verwenden separate Staging- oder Testumgebungen, um neue Codeänderungen zu testen, bevor sie in die Produktion übernommen werden. Staging-Sites enthalten oft Inhalte, die mit denen der Live-Version identisch oder sehr ähnlich sind.
Wenn jedoch diese Test-URLs öffentlich zugänglich sind und gecrawlt werden, indexieren Suchmaschinen die Inhalte aus beiden Umgebungen. Dies kann dazu führen, dass die Live-Website gegen ihre eigene Staging-Kopie konkurriert.
Beispiel:
- www.site.com
- test.site.com
Wenn die Staging-Site bereits indexiert wurde, entferne sie zuerst aus dem Index. Die schnellste Option ist, eine Entfernung über die Search Console zu beantragen. Alternativ kannst du HTTP-Authentifizierung verwenden. Dadurch erhält Googlebot einen 401-Code, der ihn daran hindert, diese Seiten zu indexieren (Google indexiert keine 4XX-URLs).
Andere nicht-technische Gründe für Doppelten Inhalt
Duplicate Content in der SEO wird nicht nur durch technische Probleme verursacht. Es gibt auch mehrere nicht-technische Faktoren, die zu Duplicate Content und anderen SEO-Problemen führen können.
Beispielsweise kopieren andere Website-Betreiber möglicherweise absichtlich einzigartige Inhalte von Seiten, die in Suchmaschinen hoch ranken, in der Hoffnung, von bestehenden Ranking-Signalen zu profitieren. Wie bereits erwähnt, führt das Scraping oder erneute Veröffentlichen von Inhalten ohne Genehmigung zu unautorisierten Duplikaten, die mit den Originalinhalten konkurrieren.
Websites veröffentlichen möglicherweise auch Gastartikel oder von Freelancern erstellte Inhalte, die nicht ausreichend auf ihre Einzigartigkeit geprüft wurden. Wenn der Autor vorhandene Inhalte wiederverwendet oder neu aufbereitet, könnte die Website unbeabsichtigt duplizierte Versionen von Artikeln oder Informationen veröffentlichen, die bereits online verfügbar sind.
Die Ergebnisse sind in beiden Fällen in der Regel schlecht und unerwartet.
Glücklicherweise ist die Lösung einfach:
- Verwende Plagiatsprüfungen, bevor Gastartikel oder ausgelagerte Inhalte veröffentlicht werden, um sicherzustellen, dass sie vollständig original und nicht kopiert sind.
- Überwache deine Inhalte auf unautorisierte Kopien oder Scraping durch andere Websites.
- Vereinbare Schutzmaßnahmen mit Partnern und Affiliates, um sicherzustellen, dass deine Inhalte nicht übermäßig erneut veröffentlicht werden.
- Füge ein DMCA-Abzeichen auf deiner Website hinzu. Wenn jemand deine Inhalte kopiert, während du das Abzeichen hast, verlangt die DMCA deren Entfernung kostenlos. Die DMCA bietet auch Tools, um plagiierten Inhalt auf anderen Websites zu finden. Sie entfernen schnell kopierte Texte, Bilder oder Videos.
Wie du Duplicate Content vermeiden kannst
Beim Erstellen einer Website stelle sicher, dass du geeignete Verfahren implementierst, um Duplicate Content auf (oder im Zusammenhang mit) deiner Seite zu verhindern.
Beispielsweise kannst du mit der robots.txt-Datei unnötige URLs vom Crawlen ausschließen. Beachte jedoch, dass du sie immer überprüfen solltest (z. B. mit unserem kostenlosen Robots.txt-Tester). So verhinderst du, dass robots.txt wichtige Seiten für Suchmaschinen-Crawler schließt.
Außerdem solltest du unnötige Seiten mit Hilfe von <meta name=”robots” content=”noindex”> oder dem X-Robots-Tag: noindex in der Serverantwort vom Indexieren ausschließen. Dies sind die einfachsten und häufigsten Methoden, um Probleme mit der Indexierung von duplizierten Seiten zu vermeiden.
Wichtig! Wenn Suchmaschinen die doppelten Seiten bereits gesehen haben und du das Canonical-Tag (oder die noindex-Direktive) verwendest, um Duplicate-Content-Probleme zu beheben, warte, bis die Suchmaschinen-Robots diese Seiten erneut crawlen. Erst dann solltest du sie in der robots.txt-Datei blockieren. Andernfalls sieht der Crawler weder das Canonical-Tag noch die noindex-Direktive.
Duplikate zu eliminieren ist unverhandelbar
Die Konsequenzen von Duplicate Content in der SEO sind vielfältig. Sie können Websites ernsthaft schaden, daher solltest du ihre Auswirkungen nicht unterschätzen. Indem du verstehst, wo das Problem liegt, kannst du deine Webseiten besser kontrollieren und Duplikate vermeiden. Wenn du doppelte Seiten hast, ist es entscheidend, rechtzeitig Maßnahmen zu ergreifen. Website-Audits durchzuführen, Ziel-URLs für Keywords festzulegen und regelmäßige Ranking-Checks durchzuführen, hilft dir, das Problem vom Doppelten Inhalt sofort zu erkennen.
Hast du jemals mit doppelten Seiten gekämpft? Wie bist du mit der Situation umgegangen? Teile deine Erfahrungen mit uns im Kommentarbereich unten!

