Les pages dupliquées : comment elles influencent SEO et comment les éviter ?
Très simples à créer, pas si simples à d’en débrouiller, et tangiblement nocives pour votre site web – voilà comment nous pouvons décrire les pages dupliquées. Pourquoi est-ce que le contenu dupliqué peut être mauvais et comment cela peut apparaitre sur le site web sans que vous le même remarquiez ? Nous allons examiner tout cela dans cet article.
Pourquoi est-ce que les pages dupliquées sont mauvaises ?
Il y a 5 raisons significatives pour expliquer le pourquoi de ce problème – pourquoi les pages dupliquées peuvent endommager votre site web ?
N’importe quel moteur de recherche est, en substance, un business. Et comme chaque business, cela ne veut pas gaspiller ces efforts pour rien. Donc, il y a l’ensemble de budget rampant pour un site unique, ce qui est une limite des sources web que les robots de recherche vont couvrir et indexer.
Nous en venons à ce que la première raison pour éviter les pages dupliquées est l’efficacité du budget rampant : pendant l’exploration des pages dupliquées, les bots de recherche peuvent rater les pages qui sont vraiment importantes.
Les issus de l’exploration, à son tour, mènent aux issus de l’indexation – et cela nous sert de la deuxième raison pour nous débarrasser de ce genre des pages. Si une page web n’est pas couverte, cela ne va pas la faire indexer. La seule chose qui puisse être faite dans ce cas est de résoudre ce problème et d’attendre jusqu’à ce que cette page soit indexée à nouveau, mais cela peut prendre du temps, notamment si vous travaillez sur un nouveau site web.
La troisième raison consiste au risque de la cannibalisation des mots-clés ou la compétition entre des différentes pages pour les mêmes mots-clés-cibles. Imaginez la situation : vous êtes arrivé à un nouveau supermarché et vous voyez la section du pain marquée dans le coin droit et dans le coin gauche en même temps. Probablement, vous allez vous poser la question où se trouve vraiment le pain et pourquoi le supermarché a-t-elle mis le signe dans les deux différentes places pour se moquer de vous ? Voilà ce qui se passe quand un moteur de recherche marque quelques mêmes pages. En résultat, le moteur ne peut pas savoir laquelle de ces pages il doit classer. Alors, cela serait mieux de ne pas déranger les robots web de recherche.
Notez que les pages dupliquées ne sont pas les seules choses qui puissent causer la cannibalisation des mots-clés. Les titres dupliqués ou les rubriques H1, beaucoup de mêmes mots-clés placés dans le contexte, les liens externes menant à la page non-cible qui ont un mot-clé compris dans le texte présentateur – tout cela peut aussi mener à un tel problème.
Obtenir les liens externes pour les pages dupliquées au lieu des versions principales des pages est la quatrième raison. Cela peut aussi aggraver le problème de cannibalisation – nous allons en retourner plus tard.
Enfin, la cinquième raison est Algorithme de Panda de Google qui peut pénaliser le site web à cause du contenu dupliqué.
Les types du contenu dupliqué
Il existe les pages dupliquées complètement et partiellement. Les pages dupliquées complètement sont quelques pages absolument identiques. Par exemple :
- Le miroir du site principal n’est pas spécifié et la page principale est accessible comme les deux – https://site.com/ et https://www.site.com/.
- La page est accessible avec le signe slash (/) à la fin ou sans cela : site.com/page/ et site.com/page
- La page est accessible en utilisant les lettres majuscules et les lettres minuscules : site.com/PAGE et site.com/page
- La page est accessible avec la catégorie spécifiée dans le URL et sans cela : site.com/phone/iphone/ et site.com/iphone/
- La page est accessible avec une extension, comme .html, .htm, .php, .aspx et sans cela : https://site.com/page et https://site.com/page.php
- La page est accessible avec le nobre différent des signes slash dans son URL : https://site.com/page/, https://site.com/page/////////////, ou https://site.com///page/
- La page est accessible avec les signes additionnels dans son URL : https://site.com/page/, https://site.com/page/cat/, ou https://site.com/page/*
- Quelques options parmi les énumérées sont combinées
Les pages dupliquées partiellement sont les pages pareilles, créées pour la même intention d’un utilisateur et avec le même but à l’esprit. Elles partagent la sémantique et sont en compétition l’une avec l’autre, ce qui aboutit à la cannibalisation des mots-clés. Par exemple :
- L’URL site.com/phome/?price=min, qui est créé histoire de trier les unités par le prix, mène à la duplication partielle du contenu.
- La version à imprimer de cette page est, essentiellement, sa duplication.
- Les mêmes bloques du contenu, comme les commentaires affichés à travers les pages multiples, peuvent aussi mener à la duplication partielle.
Les raisons pourquoi les sites web obtiennent les pages dupliquées
La faute du manageur de contenu
Le même contenu peut être mis dans le site web deux fois, juste par mégarde. Heureusement, cette situation est simple à éviter.
En premier lieu, il peut être efficace de développer et de suivre le plan du contenu, pour que vous puissiez pister le contenu qui est publié sur le site web. Il est aussi important de réexaminer régulièrement votre contenu pour être sûr qu’il n’y a pas de contenu dupliqué ou les problèmes de cannibalisation.
Si vous avez remarqué qu’en tout cas il y a du contenu dupliqué ajouté sur le site web et indexé par les moteurs de recherche, vous avez besoin de mettre en œuvre la version principale de la page et éliminer toutes les autres. Nous allons expliquer ce processus plus en détails plus tard.
Paramètres dans l’URL
Le plus souvent, c’est les paramètres d’URL qui causent la duplication du contenu et la dépense du budget d’exploration qui n’est pas effectif. Les choses suivantes peuvent contribuer à la duplication :
- Les options de filtrage pour l’affichage du contenu (la vue de la liste, la vue des schémas, etc.)
- Les tags UTM
- Les options de filtrage pour les unités présentées sur le site web
- Les paramètres pour quelques options de triage (par le prix, par la date, etc.)
- La pagination incorrecte
- L’autre information technique ajouté dans les paramètres d’URL
Une solution commune est la canonisation d’une page. Comme ça, toutes les pages qui contiennent les paramètres vont pointer sur une page qui n’a pas d’information canonique. Par exemple, https://seranking.com/?sort=desc contient <link rel=”canonical” href=”https://seranking.com/“/>.
Une autre solution commune est l’utilisation de Meta tag des robots ou X-Robots-Tag avec l’attribut non-index pour éviter la situation que les pages pas nécessaires sont indexées.
Moi personnellement, je préfère la canonisation d’une page web quand il s’agit des paramètres d’URL. Mais gardez à l’esprit que canonique n’est qu’une recommandation pour les moteurs de recherche.
Pour résoudre les problèmes du filtrage, je recommande le remplacement des tags <a> par <span> pour des filtres qui créent invariablement les pages dupliquées. C’est une solution plus complexe qui sauve le budget de l’exploration mais qui vous exige de poser une tâche pour le développeur.
Les variations d’un produit
Quand il s’agit des produits similaires, comme par exemple un modèle de T-shirt à différentes couleurs, je recommande utiliser la page unique de ce produit et fournir le choix des couleurs comme options dedans. De cette façon, vous allez minimiser le nombre des pages dupliquées et aider les utilisateurs à trouver les produits dont ils ont besoin sans devoir visiter quelques pages similaires. Cela va aussi économiser le budget de l’exploration du site web et va vous aider à éviter la cannibalisation des mots-clés.
Les versions des sites localisées
Parfois, les sites web utilisent les classeurs au lieu des sous-domaines pour leurs versions régionales, et ces classeurs contiennent en fait le même contenu. Je crois qu’il est mieux d’utiliser les sous-domaines dans ce cas-là, mais il y a aussi les autres choses à faire pour éviter les pages dupliquées dans le cas de quelques versions d’un site web.
Si vous utilisez en tout cas les classeurs sur un site e-commerce, vous devez au moins faire un titre de meta tags unique et les rubriques H1. Aussi, vous devez rendre les produits affichés différemment sur chaque version du site. Il n’y a aucune garantie que les robots de recherche vont exploiter les pages correctement, alors vous pouvez avoir à l’esprit une idée de rendre le contenu unique.
C’est plus facile à faire avec un site web qui ne vend pas des produits mais fait la promotion des services. Si vous avez des pages ciblés à différents pays ou villes, écrivez juste du contenu unique pour chaque location spécifique.
L’utilisation de hreflang vous aide à éliminer les pages partiellement dupliquées mais c’est crucial pour appliquer l’attribut attentivement et pour pister la situation.
Certains sites web ont les domaines locaux, dont le contenu est le même ou pareil. Dans ce cas, il est bien de réécrire le contenu en prenant en considération chaque spécifique locale et aussi de mettre les attributs hreflang.
L’accessibilité du produit à travers les différentes catégories
D’habitude, les produits sont ajoutés dans quelques catégories sur les sites e-commerce. Cela peut causer la duplication, si l’URL contient le chemin complet vers le produit. Par exemple, https://site.com/t-shirt/nike/t-shirt-best.html et https://site.com/t-shirt/red/t-shirt-best.html.
Vous pouvez résoudre cet issu dans le CMS en mettant en œuvre un URL unique pour chaque produit disponible sous les différentes catégories. L’autre solution est d’utiliser le tag canonique.
Les issus techniques
Les problèmes techniques sont les raisons les plus communes à causer la duplication. Cela arrive très souvent dans les CMSs moins populaires ou créés par les utilisateurs. Un spécialiste SEO doit pister les paramètres qui puissent mener à la duplication (les miroirs des sites web, les signes slash dans les URLs, etc.). J’ai déjà mentionné tous les risques potentiels à pister plus tôt.
Comment éviter les pages dupliquées
Quand vous créez un site web, vous pouvez empêcher les URLs pas nécessaires d’être explorés avec de l’aide de robots.txt file. Notez, quand même, que vous devez toujours vérifier cela avec La fonctionnalité de testing des robots dans Google Search Console. De cette façon, robots.txt ne vont pas fermer les pages importantes des explorateurs de recherche.
Qui plus est, vous devez fermer les pages pas nécessaires de l’indexation avec de l’aide de <meta name=”robots” content=”noindex”> ou X-Robots-Tag: noindex dans la réponse du serveur. Ici, nous avons énuméré les façons les plus simples et les plus communes d’éviter les problèmes avec l’indexation des pages dupliquées.
Important ! Si les moteurs de recherche ont déjà vu les pages dont vous n’avez pas besoin et vous utilisez le tag canonique ou la directive noindex pour résoudre ce problème, attendez jusqu’à ce que les moteurs de recherche explorent les pages et ce n’est qu’après cela que vous pouvez les bloquer dans le fichier robots.txt. Sinon, l’explorateur ne va pas voir le tag canonique ou la directive noindex.
Vous pouvez vérifiez l’accès des robots aux pages facilement en utilisant le Test de robots.txt.
Comment trouver les pages dupliquées en utilisant SE Ranking
La fonctionnalité de SE Ranking L’audit du site web peut vous aider à identifier toutes les pages dupliquées. Dans la section Contenu Dupliqué, vous allez trouver la liste des pages qui contiennent le même contenu, tout comme la liste des duplications techniques : les pages accessibles avec ou sans www, avec ou sans les signes slash, etc. Si vous avez utilisé le tag canonique pour résoudre le problème de la duplication mais en même temps avez spécifié quelques URLs canoniques, l’audit va aussi mettre en relief cette faute.

Choisir la version principale d’une page
Si vous avez détecté le contenu dupliqué sur votre site web, ne vous précipitez pas de juste l’effacer. En premier lieu, vérifiez les choses suivantes :
- Vérifiez quelles pages sont classées mieux pour le mot-clé cible. Vous pouvez le faire de quelques différentes façons :
- En utilisant l’opérateur site:your-url keyword. Si vous voyez que ce n’est pas une des pages dupliquées mais une autre est classée comme première, cela veut dire que les pages dupliquées ont besoin d’être mieux optimisées. Si vous ne savez pas ce qui est le mot-clé-cible pour une page donnée, vous pouvez le repérer dans le meta tag title.
- En utilisant Google Search Console. Allez au rapport Performance qui va vous permettre le filtrage par requête.
Source : Search Engine Watch
- En utilisant SE Ranking, dans le module Classements, vous pouvez spécifier un URL-cible pour chaque mot-clé ajouté. Si le classement d’URL pour le mot-clé et l’URL-cible spécifié sont deux pages différentes, l’icône de lien va être affichée en rouge.
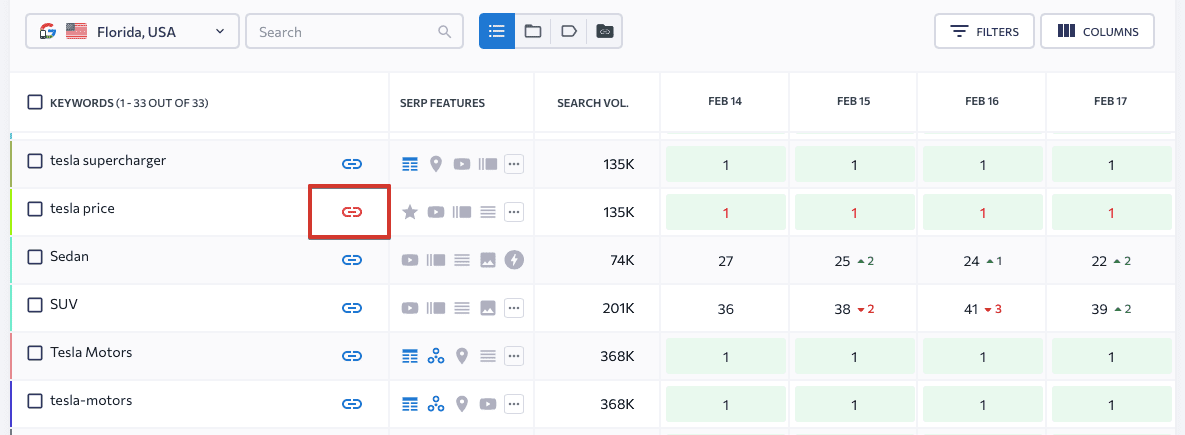
Vous allez aussi repérer si les URLs affichés dans la recherche replacent constamment l’un l’autre : le système va afficher le nombre qui est à côté de l’icône de lien. Ce nombre indique combien pages web sont en compétition l’une contre l’autre, et en cliquant sur l’icône, vous allez voir ces pages et leurs textes title.
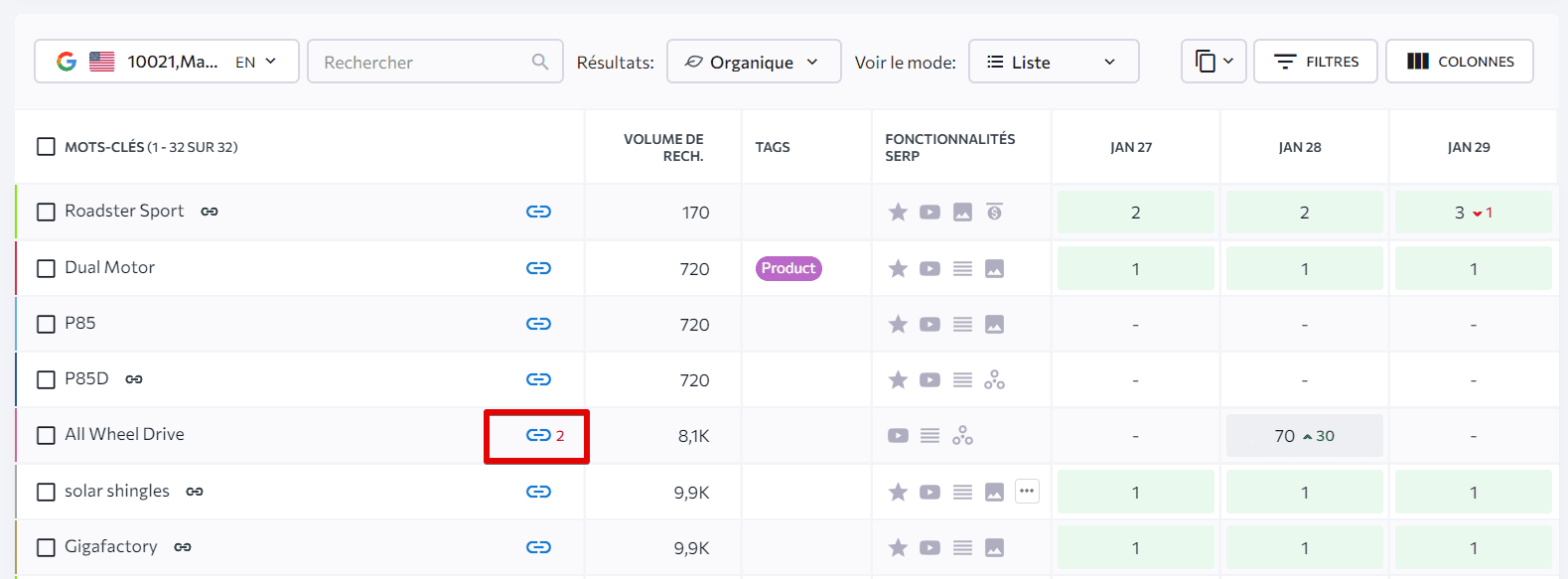
Vous pouvez pister comment les URLs changent leurs classements sous la section SERP Concurrents dans la fonctionnalité Mes concurrents. De cette façon, vous allez simplement repérer le problème de cannibalisation pour s’il y a les points suivants :
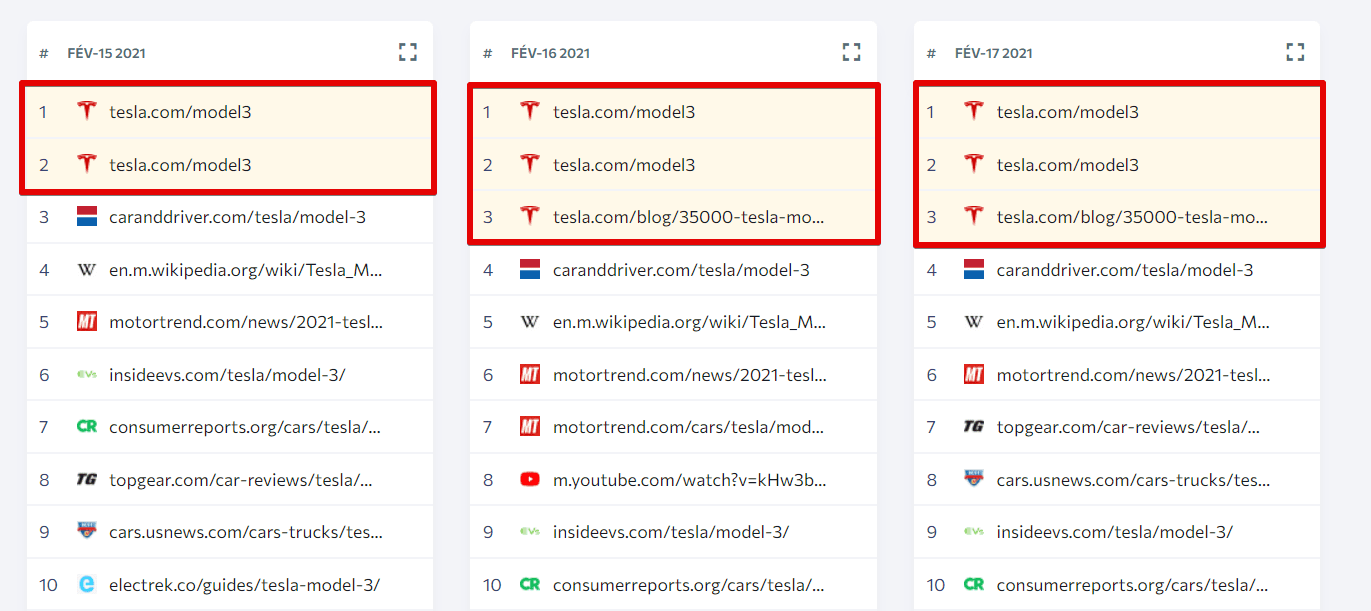
- Définir le nombre des liens externes pointant vers chaque page dupliquée.
- Définir le nombre des mots-clés selon lesquels ces pages sont classées. Utiliser Google Search Console et filtrer les données par page.
- Définir combien de trafic ces pages reçoivent et ce qui est leurs taux de rebond et les taux de conversion. Pour le faire, utilisez Google Search Console ou la fonctionnalité Analyses & Trafic
- Décidez quelle page est à abandonner sur le site en se basant sur tous les facteurs mentionnés.
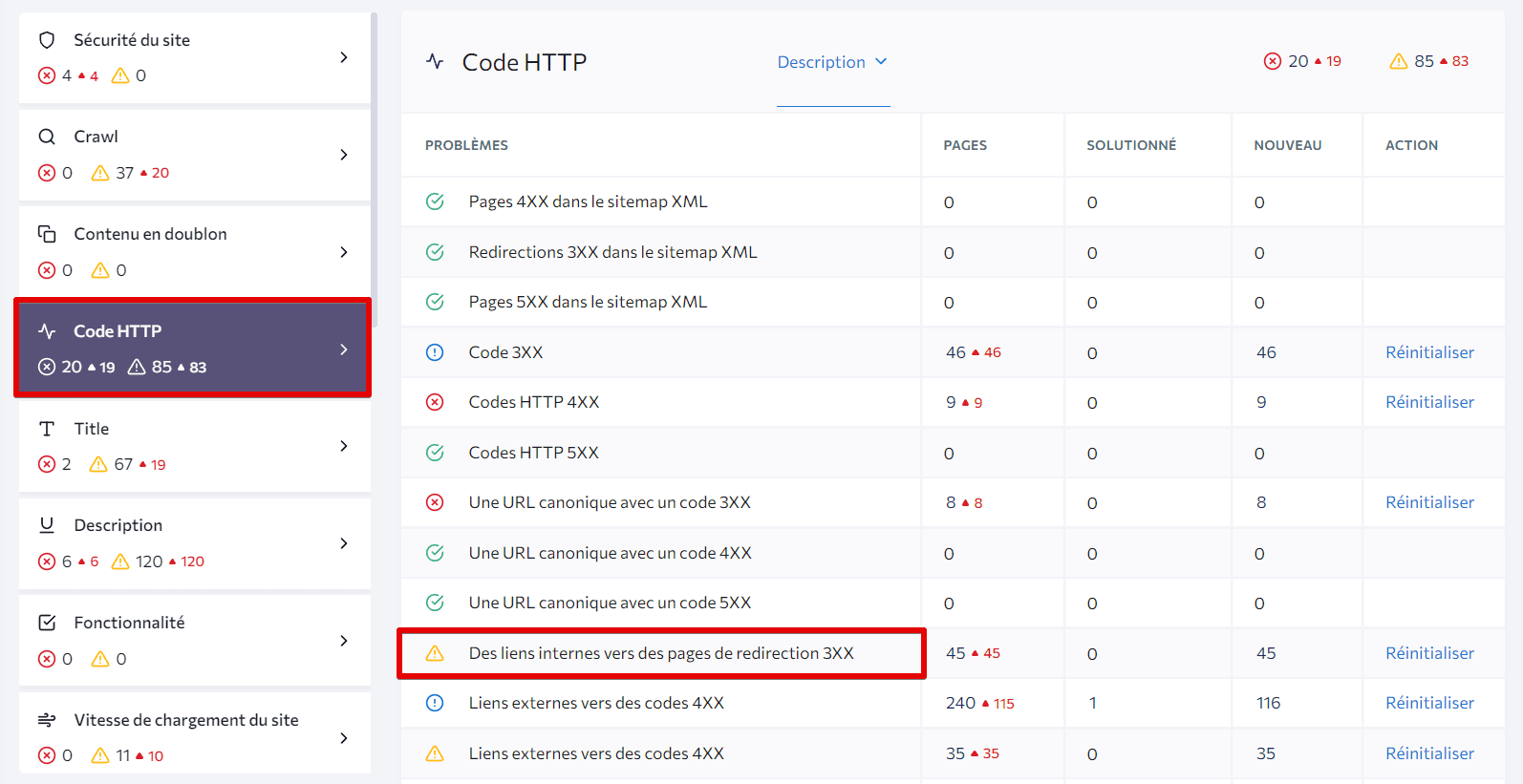
Après avoir enlevé une page dupliquée, vous devez mettre 301 redirections de cela vers la version principale de la page. Après cela, faites l’audit de votre site de nouveau pour retrouver les liens externes pointant vers une page qui a été effacée – vous devez les remplacer par l’URL de la page principale. Dans le L’audit du site web de SE Ranking, vous allez trouver cette information sous la section HTTP Status Code :
Éviter le contenu dupliqué ne se discute pas
Il est évident que les pages dupliquées peuvent causer du dommage à un site web, donc vous ne devez pas sous-estimer leur impact. La compréhension de la source du problème va vous aider de contrôler facilement vos pages web et d’éviter le contenu dupliqué. Si vous avez quand même les pages dupliquées, il est crucial d’agir à temps. Les audits des sites web, la mise des cibles des URLs pour les mots-clés et la vérification régulière du classement va vous aider d’identifier les problèmes une fois ils se produisent.
Avez-vous jamais eu des difficultés avec les pages dupliquées ? Comment avez-vous maîtrisé la situation ? Partagez votre expérience avec nous dans la section des commentaires !

