Test robots.txt
En attendant...
Lancez un audit SEO pour avec un compte d'essai gratuit !
- Vérifiez quelles pages sont bloquées par robots.txt ou autrement
- Détectez les erreurs d'exploration et d'indexation, les problèmes de cannibalisation, etc.
- Inspectez le trafic du site Web, les mots-clés les plus performants et les pages.
- Examinez les backlinks, les classements, les caractéristiques des SERP et les aperçus AI (AI Overviews)
Comment lire un fichier robots.txt ?
Comment utiliser notre testeur de robots.txt ?
Pourquoi un fichier robots.txt est-il nécessaire ?
Les fichiers robots.txt fournissent aux moteurs de recherche des informations importantes sur l’exploration des fichiers et des pages Web. Ce fichier est principalement utilisé pour gérer le trafic des robots vers votre site Web afin d’éviter de surcharger votre site de requêtes.
Vous pouvez résoudre deux problèmes avec son aide :
- Tout d’abord, réduisez la probabilité que certaines pages soient explorées, y compris leur indexation et leur apparition dans les résultats de recherche.
- Deuxièmement, économisez le budget d’exploration en fermant les pages qui ne devraient pas être indexées.
Toutefois, si vous souhaitez empêcher une page ou un autre actif numérique d’apparaître dans la recherche Google, une option plus fiable consisterait à ajouter l’attribut no-index à la balise méta robots.
Comment s'assurer que robots.txt fonctionne correctement ?
Un moyen rapide et simple de vous assurer que votre fichier robots.txt fonctionne correctement consiste à utiliser des outils spéciaux.
Par exemple, vous pouvez valider votre robots.txt en utilisant notre outil : saisissez jusqu’à 100 URL et il vous montrera si le fichier empêche les robots d’accéder à des URL spécifiques sur votre site.
Pour détecter rapidement les erreurs dans le fichier robots.txt, vous pouvez également utiliser Google Search Console.
Problèmes robots.txt courants
- Le fichier n’est pas au format .txt. Dans ce cas, les robots ne pourront pas trouver et explorer votre fichier robots.txt en raison de la non-concordance du format.
- Robots.txt ne se trouve pas dans le répertoire racine. Le fichier doit être placé dans le répertoire le plus haut du site Web. S’il est placé dans un sous-dossier, votre fichier robots.txt ne sera probablement pas visible pour les robots de recherche. Pour résoudre ce problème, déplacez votre fichier robots.txt vers votre répertoire racine.
Dans la directive Refuser, vous devez spécifier des fichiers ou des pages particuliers qui ne doivent pas apparaître sur les SERP. Il peut être utilisé avec la directive User-agent afin de bloquer le site Web d’un robot d’exploration particulier.
- Disallow sans valeur. Une directive disallow vide indique aux robots qu’ils peuvent visiter n’importe quelle page du site Web.
- Lignes vides dans le fichier robots.txt. Ne laissez pas de lignes vides entre les directives. Sinon, les robots ne pourront pas explorer le fichier correctement. Une ligne vide dans le fichier robots.txt doit être placée seulement avant d’indiquer un nouveau User-agent.
Bonnes pratiques pour les robots.txt
- Utilisez la case appropriée dans robots.txt. Les robots traitent les noms de dossiers et de sections comme étant sensibles à la case. Ainsi, si le nom d’un dossier commence par une lettre majuscule, le nommer avec une lettre minuscule désorientera le robot, et vice versa.
- Chaque directive doit commencer sur une nouvelle ligne. Il ne peut y avoir qu’un seul paramètre par ligne.
- L’utilisation d’espaces en début de ligne, de guillemets ou de points-virgules pour les directives est strictement interdite.
- Il n’est pas nécessaire de répertorier tous les fichiers que vous souhaitez bloquer des robots d’exploration. Il vous suffit de spécifier un dossier ou un répertoire dans la directive Refuser, et tous les fichiers de ces dossiers ou répertoires seront également bloqués lors de l’exploration.
- Vous pouvez utiliser des expressions régulières pour créer un fichier robots.txt avec des instructions plus flexibles.
- L’astérisque (*) indique toute variation de valeur.
- Le signe dollar ($) est une restriction de type astérisque qui s’applique aux adresses URL des sites Web. Il est utilisé pour spécifier la fin du chemin de l’URL.
- Utilisez l’authentification côté serveur pour bloquer l’accès au contenu privé. De cette façon, vous pouvez vous assurer que vos données importantes ne seront pas volées.
- Utilisez un fichier robots.txt par domaine. Si vous devez définir des directives d’exploration pour différents sites, créez un robots.txt distinct pour chacun.
Autres façons de tester votre fichier robots.txt
Vous pouvez analyser votre fichier robots.txt à l’aide de l’outil Google Search Console.
Ce testeur robots.txt vous montre si votre fichier robots.txt empêche les robots d’exploration de Google d’accéder à des URL spécifiques sur votre site Web. L’outil n’est pas disponible dans la nouvelle version de GSC, mais vous pouvez y accéder en cliquant sur ce lien.
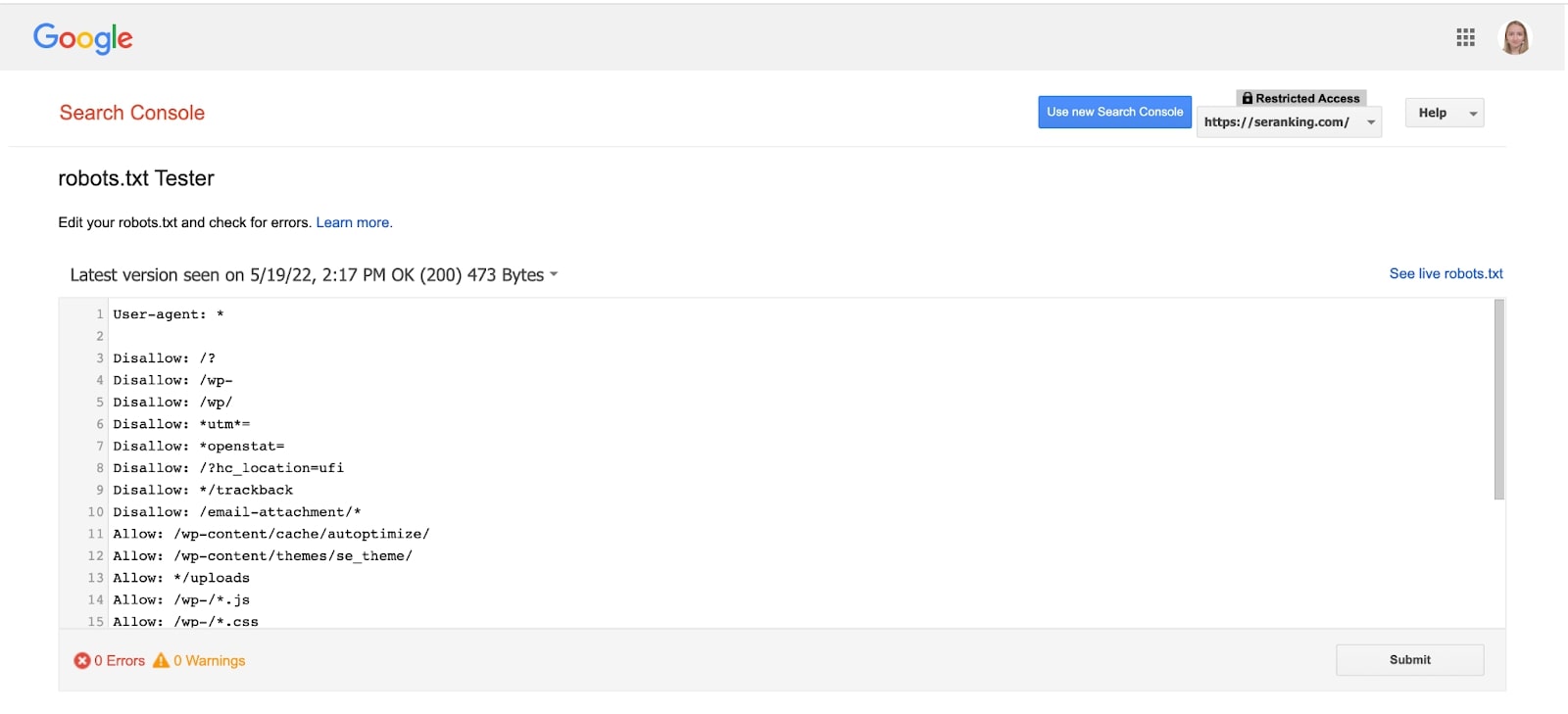
Choisissez votre domaine et l’outil vous montrera le fichier robots.txt, ses erreurs et ses avertissements.
Allez au bas de la page, où vous pouvez saisir l’URL d’une page dans la zone de texte. En conséquence, le testeur robots.txt vérifiera que votre URL a été correctement bloquée.

Que doit contenir un fichier robots.txt ?
Les fichiers robots.txt contiennent des informations qui indiquent aux robots d’exploration comment interagir avec un site particulier. Cela commence par une directive User-agent qui spécifie le robot de recherche auquel les règles s’appliquent. Ensuite, vous devez spécifier des directives qui autorisent et bloquent certains fichiers et pages des robots d’exploration. À la fin d’un fichier robots.txt, vous pouvez éventuellement ajouter un lien vers votre plan de site.
Les robots peuvent-ils ignorer le fichier robots.txt ?
Les robots d’exploration font toujours référence à un fichier robots.txt existant lorsqu’ils visitent un site Web. Bien que le fichier robots.txt fournisse des règles pour les robots, il ne peut pas appliquer les instructions. Le fichier robots.txt lui-même est une liste de directives destinées aux robots d’exploration, et non de règles strictes. Par conséquent, dans certains cas, les robots peuvent ignorer ces directives.
Comment réparer un fichier robots.txt ?
Un fichier robots.txt est un document texte. Vous pouvez modifier le fichier actuel via un éditeur de texte, puis l’ajouter à nouveau au répertoire racine du site Web. De plus, de nombreux CMS, y compris WordPress, disposent de divers plugins qui permettent d’apporter des modifications au fichier robots.txt. Vous pouvez le faire directement depuis le tableau de bord d’administration.