Le guide SEO pour trouver toutes les pages d’un site Web
Dans le monde du référencement, les données permettent de prendre des décisions éclairées et de mettre en place des stratégies efficaces. Pour réussir, vous devez vous concentrer sur deux choses : la connaissance du marché et une compréhension approfondie de votre site.
Cet article se concentre sur le second point : connaître votre site de fond en comble, car les problèmes les plus importants et les opportunités de croissance résident souvent dans les pages que vous pourriez oublier. Pour réussir un audit SEO complet, il est essentiel de savoir comment récupérer toutes les URLs d’un site afin d’obtenir une vision claire de sa structure et de ses contenus.
Permettez-moi de vous expliquer quelques raisons possibles pour lesquelles vous pourriez avoir besoin de trouver toutes les pages d’un site Web, quels outils vous aideront à le faire efficacement et comment exactement.
-
Audit du site Web de SE Ranking :
cet outil explore votre site et rassemble toutes les URL que les moteurs de recherche peuvent indexer. Il permet de personnaliser l’analyse de sections spécifiques du site et fournit des mesures telles que les erreurs, la structure des URL et l’état d’indexation.
-
La console de recherche Google :
GSC affiche toutes les pages indexées par Google sur votre site, y compris celles qui n’ont pas été indexées en raison d’erreurs. Vous pouvez exporter des données pour suivre et améliorer la visibilité de votre site.
-
Google Analytics :
il enregistre toutes les pages visitées par les utilisateurs, offrant ainsi un aperçu des pages qui pourraient être négligées mais qui restent utiles pour le référencement ou le marketing.
-
Outils Bing pour les webmasters :
cet outil révèle toutes les pages indexées par Bing, offrant une alternative à l’indexation de Google et aidant à optimiser votre site pour les différents moteurs de recherche.
-
Ligne de commande :
à l’aide d’outils tels que Wget, vous pouvez télécharger et répertorier toutes les URL d’un site, y compris celles situées au plus profond de la structure du site.
-
Plan du site :
en accédant au fichier sitemap.xml, vous pouvez trouver toutes les pages qu’un propriétaire de site souhaite indexer.
-
Plugins WordPress :
des plugins tels que List all URL et Export All URLs simplifient le processus d’extraction de toutes les pages du site, en particulier pour les utilisateurs de WordPress.
Pourquoi ai-je besoin de trouver chaque page ?
Les moteurs de recherche mettent régulièrement à jour leurs algorithmes et appliquent des pénalités manuelles aux pages et aux sites. Ne pas connaître toutes les pages de votre site Web vous met donc en danger.
Pour éviter des problèmes majeurs, vous devez surveiller chaque page de votre site. Cela vous aidera également à retrouver les pages oubliées ou cachées que vous n’auriez pas repérées autrement.
Différentes méthodes permettent de récolter tous les URLs d’un site Web, ce qui constitue la première étape incontournable pour analyser sa visibilité et optimiser son référencement. Il existe plusieurs scénarios possibles lorsqu’il devient essentiel de trouver toutes les pages Web d’un site :
- Modification de l’architecture du site Web
- Déplacement vers un nouveau domaine ou modification de la structure de l’URL
- Recherche de pages orphelines
- Recherche de pages en double
- Trouver 404 pages
- Création de redirections
- Création d’un fichier hreflang de site web
- Vérification des balises canoniques et noindex
- Mise en place du maillage interne
- Création d’un sitemap XML ou d’un fichier robots.txt
Avant même de lancer un audit technique et de repérer toutes les pages de votre site, assurez-vous qu’un fichier robots.txt est bien en place. Ce fichier permet de contrôler l’exploration de votre site par les moteurs de recherche. Si vous n’en avez pas encore, vous pouvez en créer un facilement avec notre générateur de fichier robots.txt, conçu pour les webmasters, les experts SEO et les marketeurs.
Comment trouver toutes les pages d’un site web
Désormais, lorsqu’il s’agit de rechercher toutes les pages Web appartenant à un seul site Web, les options suivantes sont disponibles :
- Utilisez l’audit de site Web de SE Ranking pour trouver toutes les pages Web explorables.
- Utilisez la console de recherche Google pour découvrir les pages qui ne sont visibles que par Google.
- Utilisez Google Analytics pour détecter toutes les pages qui ont déjà été visitées.
- Utilisez les outils Bing Webmaster pour détecter les pages qui ne sont visibles que par Bing.
- Téléchargez la liste des pages du site Web à l’aide des commandes de ligne de commande.
- Extrayez les URL des sites Web à partir du fichier Sitemap.xml.
- Afficher toutes les pages d’un site Web via WordPress et d’autres plugins.
Voyons comment utiliser ces outils pour scanner toutes les pages d’un site Web.
Trouver des pages explorables grâce à l’audit du site Web de SE Ranking
Commençons par collecter toutes les URL que les internautes et les robots des moteurs de recherche peuvent consulter en suivant les liens internes de votre site. L’analyse de ces pages devrait être votre priorité absolue car elles attirent le plus d’attention.
Pour ce faire, accédez à SE Ranking, ouvrez l’outil d’audit du site Web et appuyez sur le bouton Nouvel audit pour démarrer.
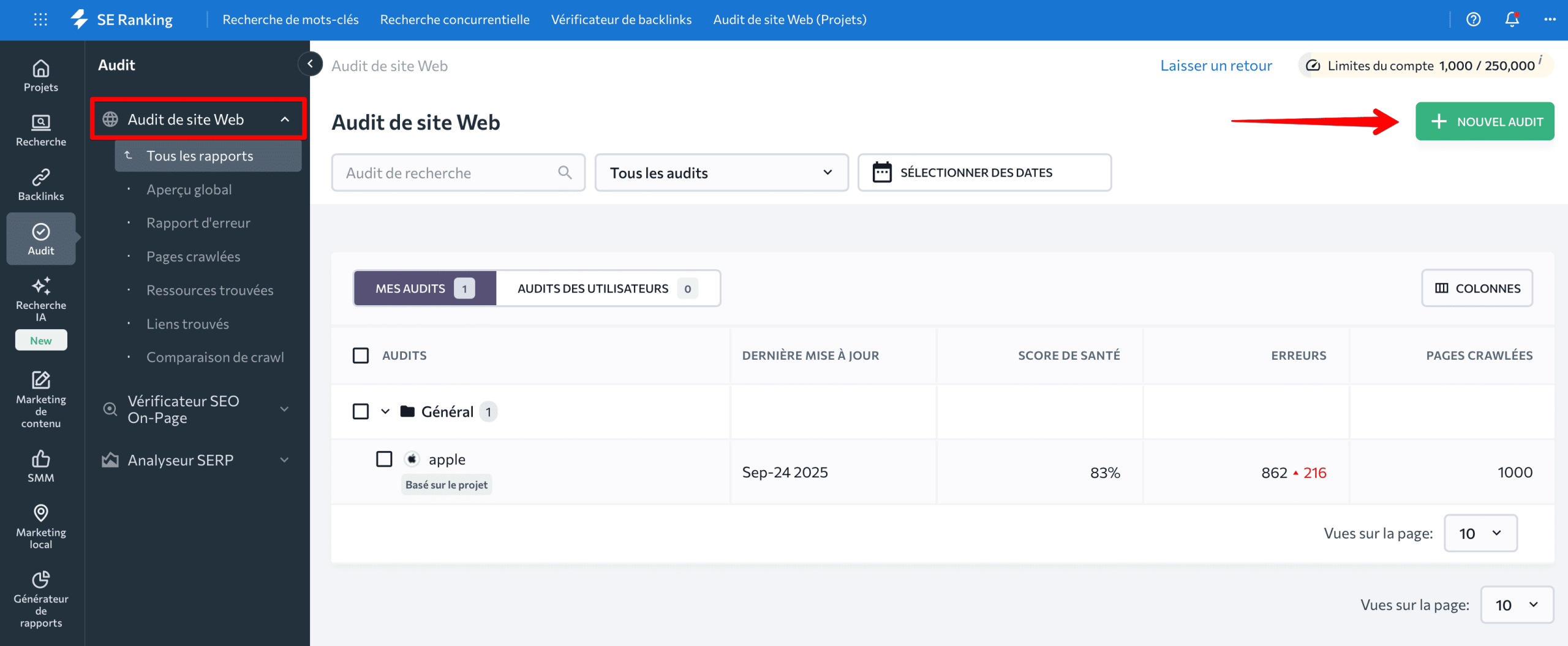
Vous pouvez également configurer des audits automatiques de sites Web dans les paramètres avancés lors de la configuration du projet.
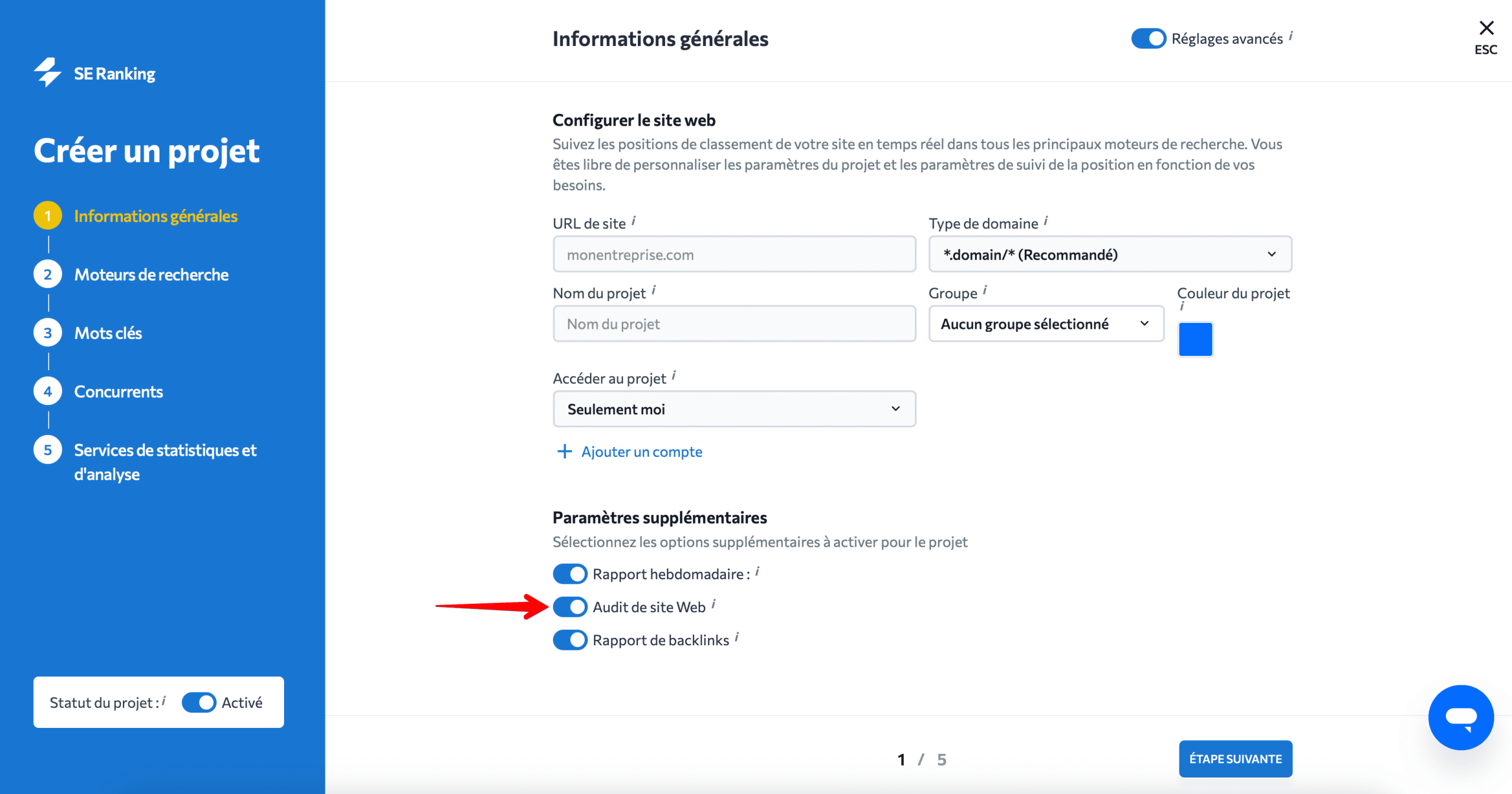
Remarque : L’essai gratuit de 14 jours vous donne accès à tous les outils et fonctionnalités disponibles de SE Ranking, y compris l’audit de site Web.
Configurons ensuite les paramètres pour nous assurer que nous demandons au robot d’exploration de parcourir les bonnes pages. Pour accéder aux paramètres d’audit du site Web, cliquez sur l’icône en forme d’engrenage en haut à droite :
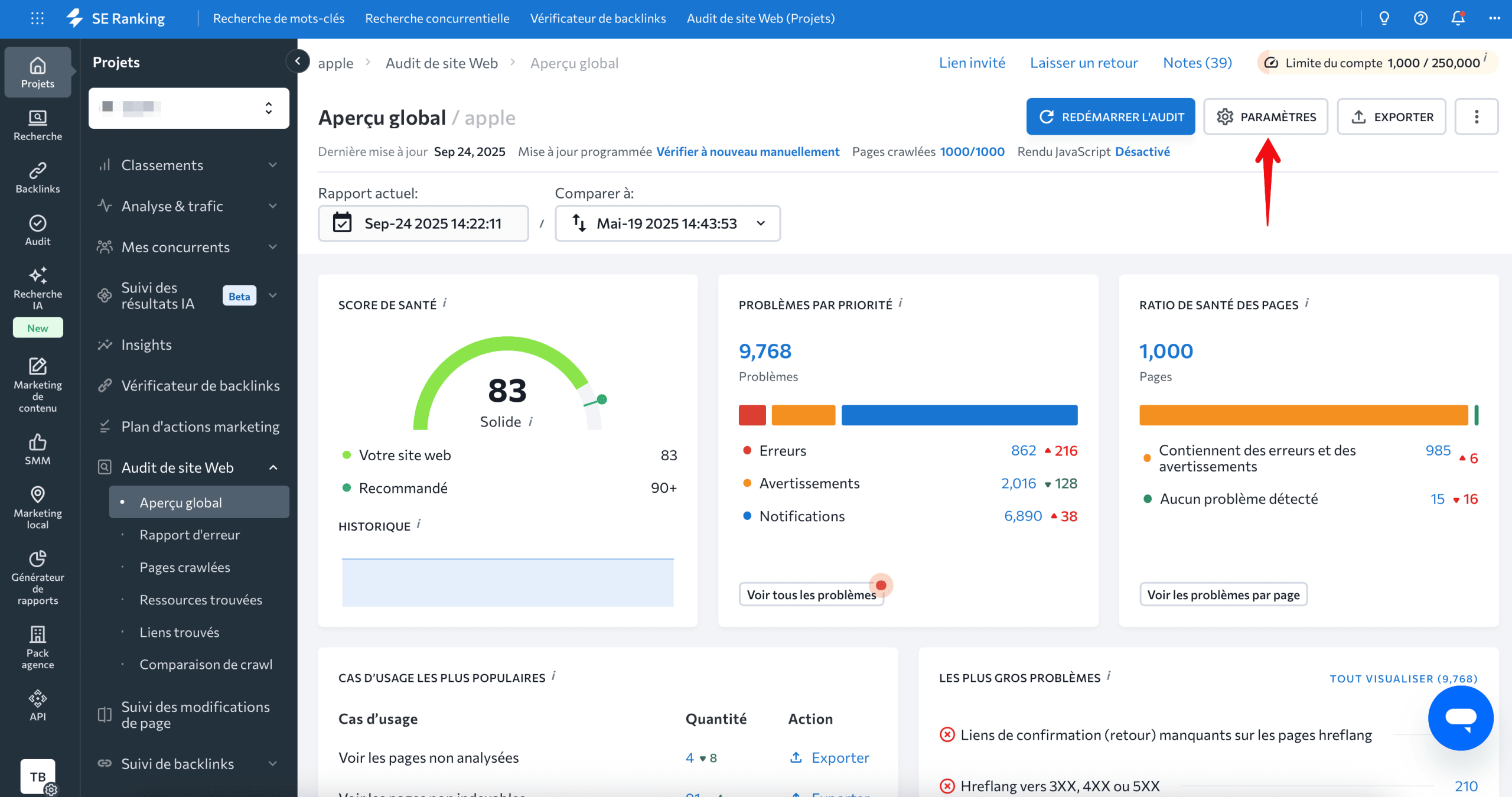
Sous Paramètres, accédez à l’onglet Source des pages pour l’audit de site Web, puis activez le système pour analyser les pages du site, les sous-domaines et le plan de site XML pour vérifier que nous n’analysons que ce qui a été clairement spécifié et que nous incluons les sous-domaines du site avec toutes leurs pages :
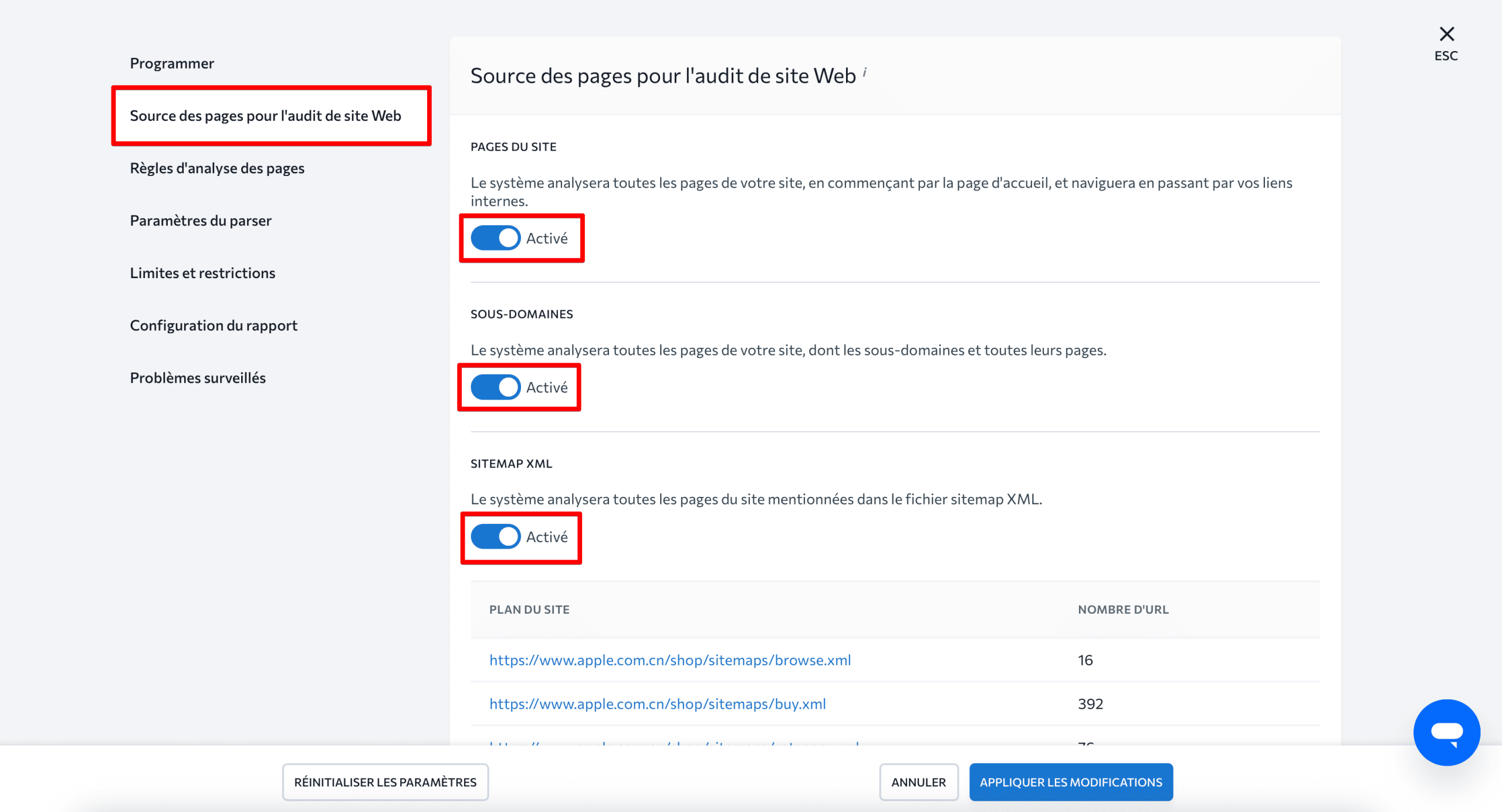
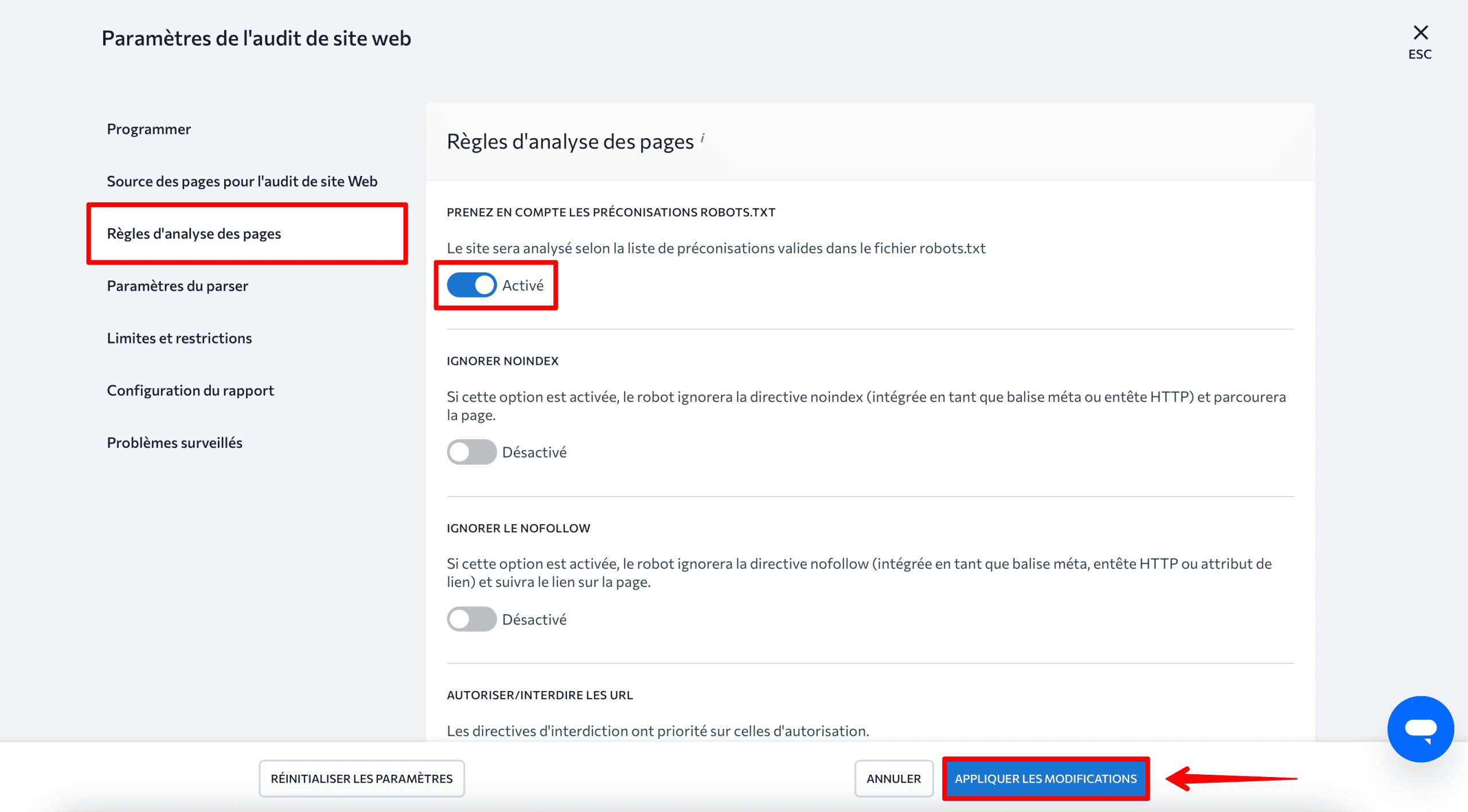
Ensuite, allez dans Règles de numérisation des pages, et activez l’option Prendre en compte les directives robots.txt pour indiquer au système de suivre les instructions spécifiées dans le fichier robots.txt. Cliquez sur « Appliquer les modifications » lorsque vous avez terminé :
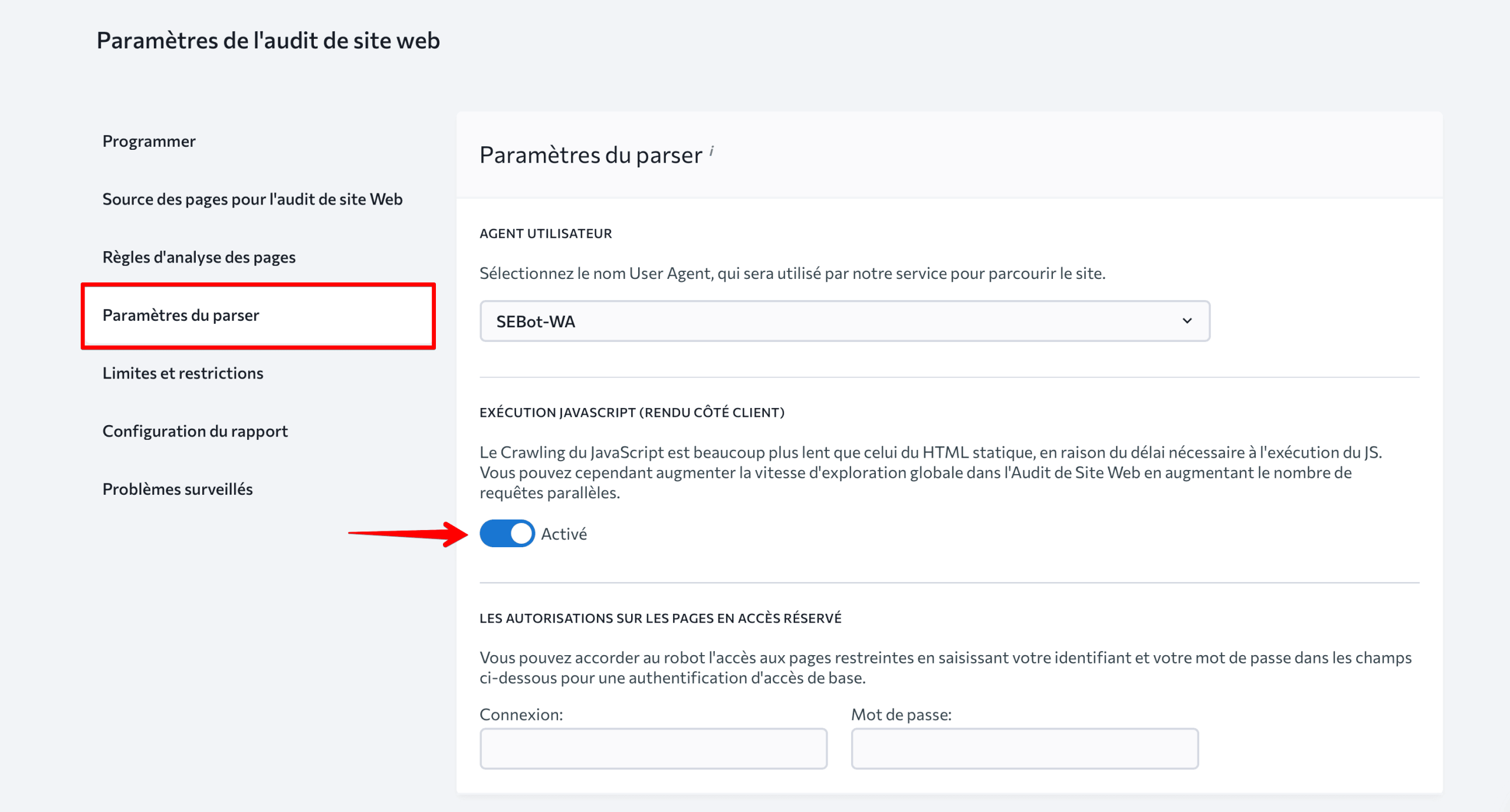
Si vous avez un site Web basé sur JS, accédez aux paramètres de l’analyseur et activez le rendu JavaScript pour vous assurer que l’outil analyse le contenu chargé dynamiquement sur votre site.
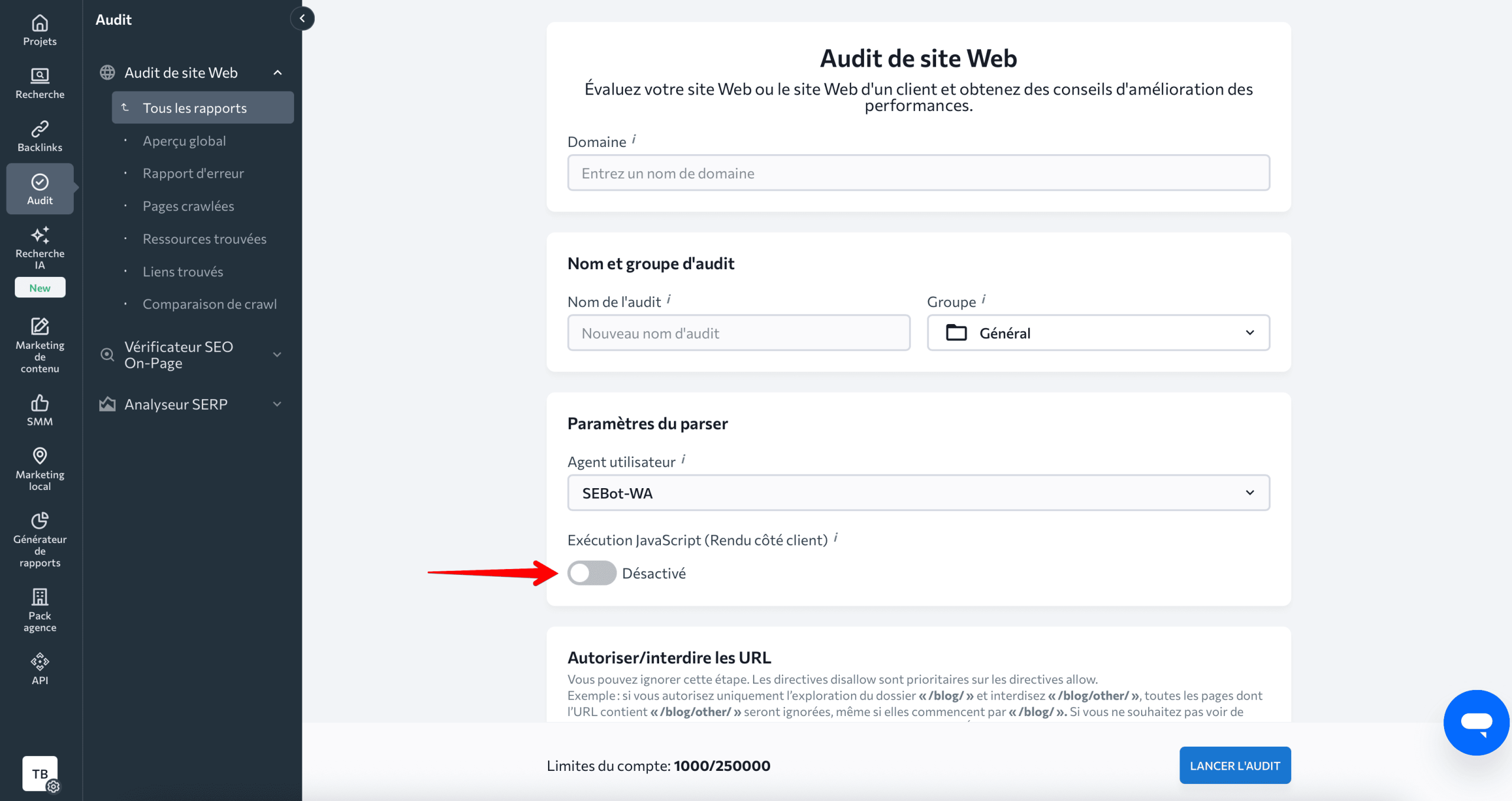
Vous pouvez également l’activer lorsque vous lancez un nouvel audit dans l’assistant d’audit du site Web.
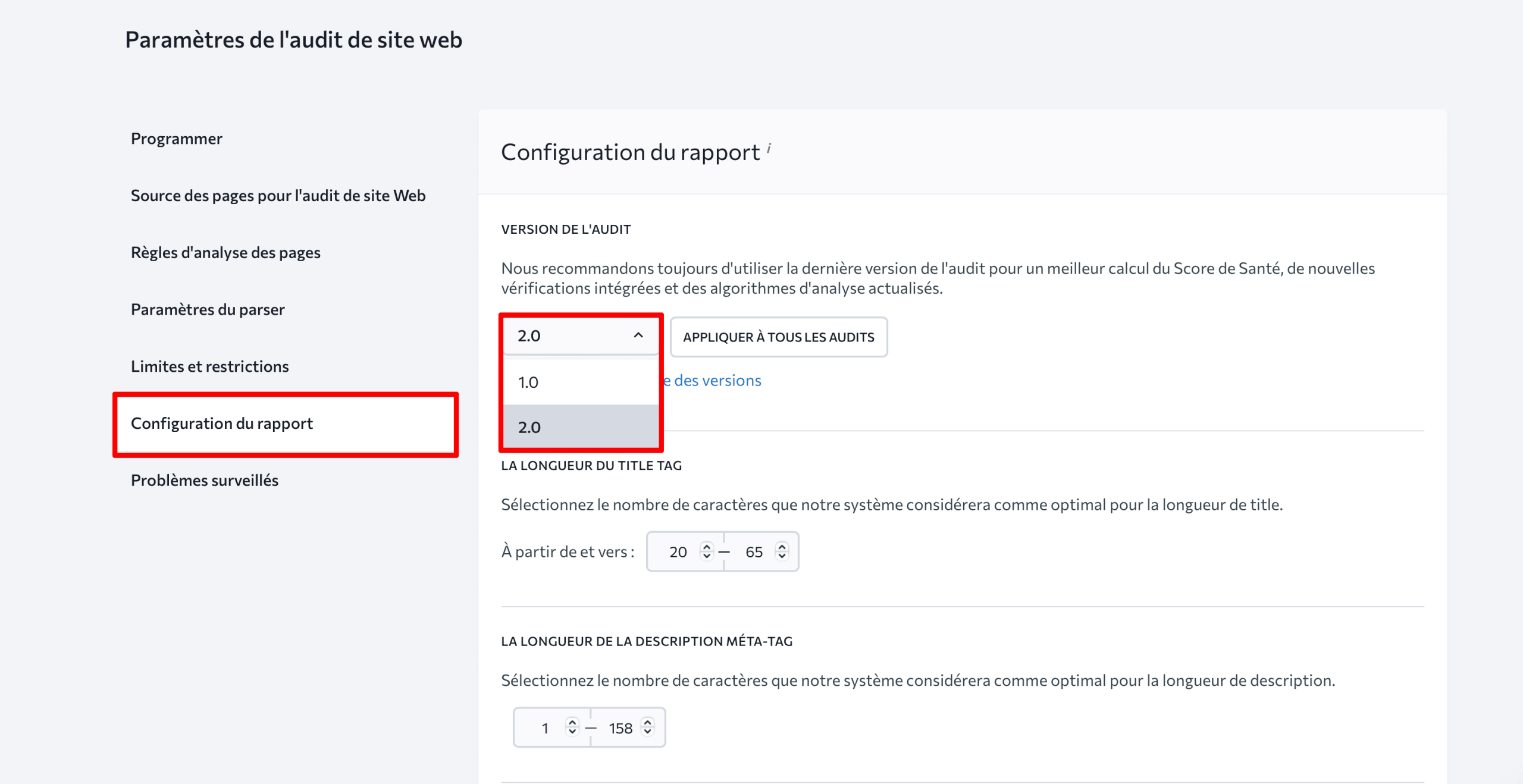
Notez également que nous proposons désormais Website Audit 2.0 que vous pouvez utiliser dans la section Configuration du rapport si vous avez des versions d’audit plus anciennes. Cette mise à jour inclut :
- Algorithmes d’analyse mis à jour qui permettent de mieux hiérarchiser les problèmes en fonction de leur impact réel sur les performances de votre site Web et de son score de santé global
- Calcul du score de santé amélioré qui prend en compte à la fois la gravité des erreurs et le nombre de pages concernées
- Nouveaux contrôles intégrés avec des catégories dédiées à l’exploration et à l’indexation, aux sitemaps, aux balises méta, au contenu, à la vitesse et aux performances, aux liens, etc.
Maintenant, retournez à l’onglet Aperçu et lancez l’audit avec les nouveaux paramètres appliqués en cliquant sur « Redémarrer l’audit » :
Une fois l’audit terminé, accédez à Pages explorées pour afficher la liste complète de toutes les pages explorables :
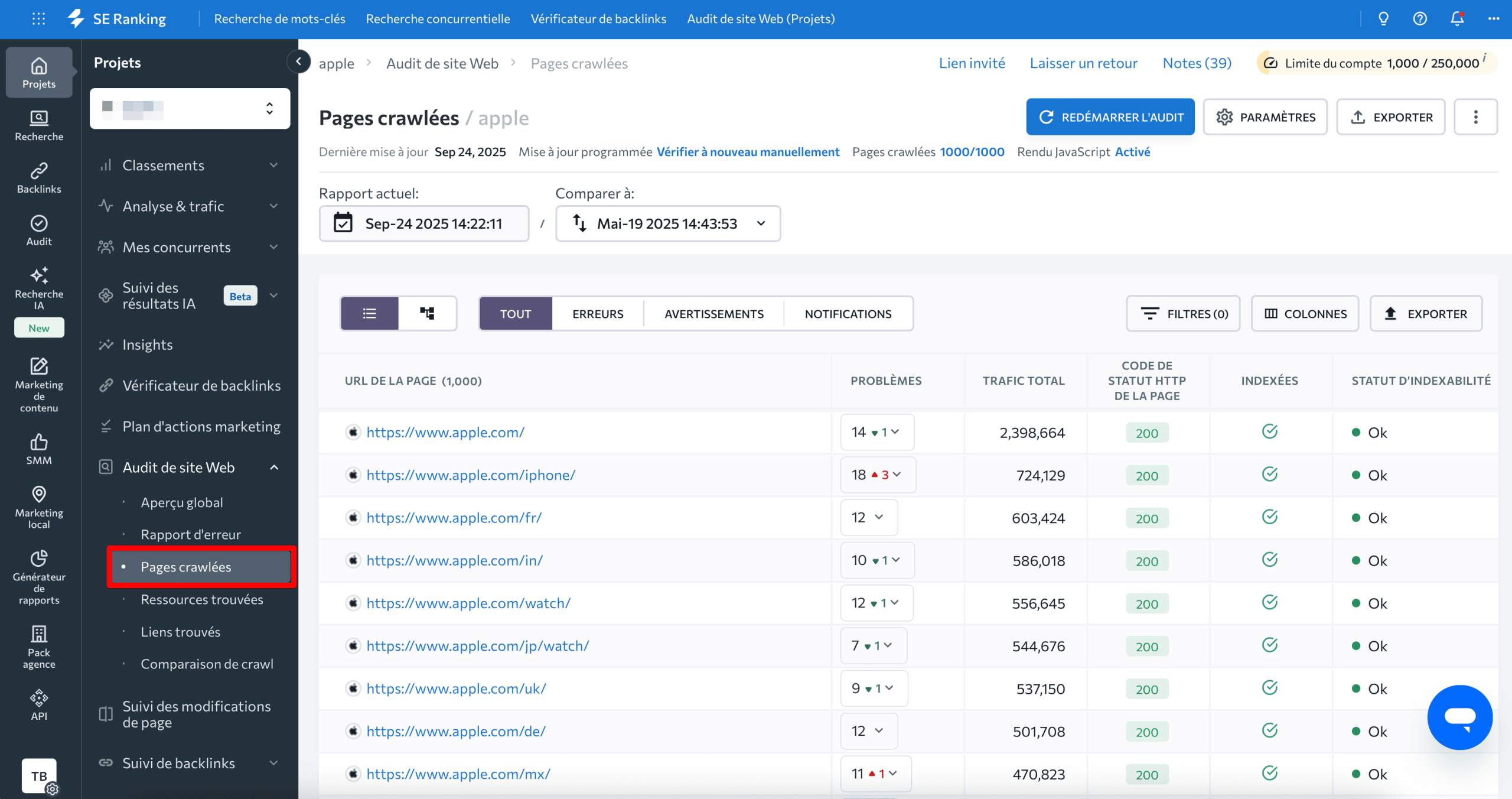
En plus d’une liste de toutes les URL trouvées, vous verrez toutes les statistiques de référencement essentielles du site, notamment :
- Pages de référence : le nombre de pages de votre site Web qui renvoient à l’URL spécifique.
- Nombre de problèmes techniques sur chaque page.
- Trafic total pour chaque page.
- Nombre total de mots-clés pour lesquels chaque page est classée.
- État d’indexabilité.
- Nombre de caractères dans l’URL de la page.
- Type et version du protocole URL.
- Si la page se trouve dans le plan du site.
- Code de réponse du serveur sur la page.
- Si la page est bloquée par robots.txt.
- Et plus encore.
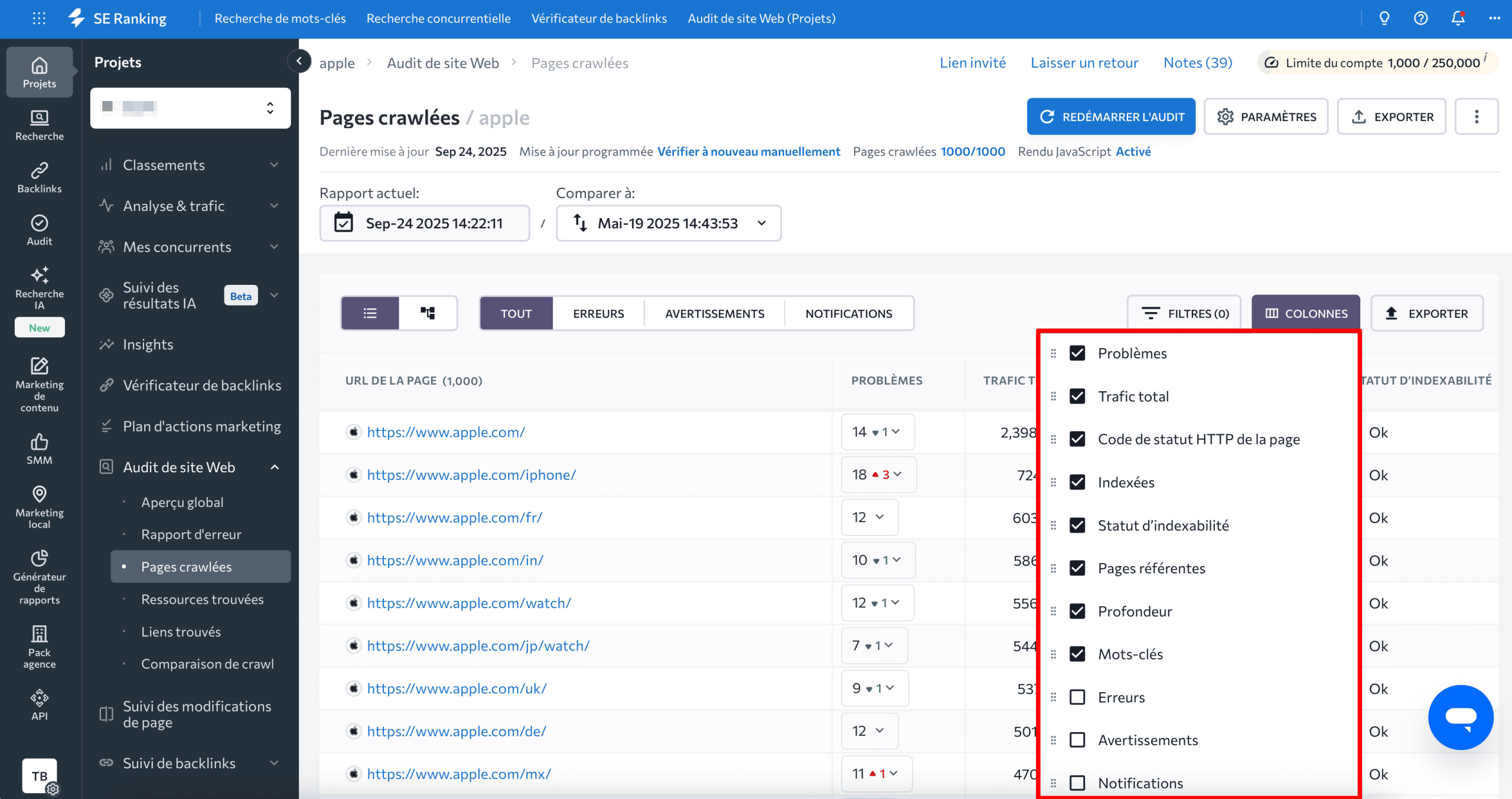
Les statistiques ci-dessus apparaîtront sous forme de colonnes par défaut dans l’onglet Pages explorées. Vous pouvez toutefois personnaliser le rapport pour répondre à vos besoins spécifiques en ajoutant d’autres paramètres. Accédez simplement à la section Colonnes au-dessus du tableau de droite et activez ou désactivez n’importe quelle métrique comme vous le souhaitez.
Les pages explorées peuvent être triées en fonction des erreurs, des avertissements et des notifications qu’elles contiennent. Cela vous permettra de hiérarchiser les pages lors de la résolution des problèmes. Vous pouvez également comparer les rapports une fois que vous avez audité votre site Web au moins deux fois. Cela vous permet d’observer l’évolution de vos pages explorées au fil du temps.
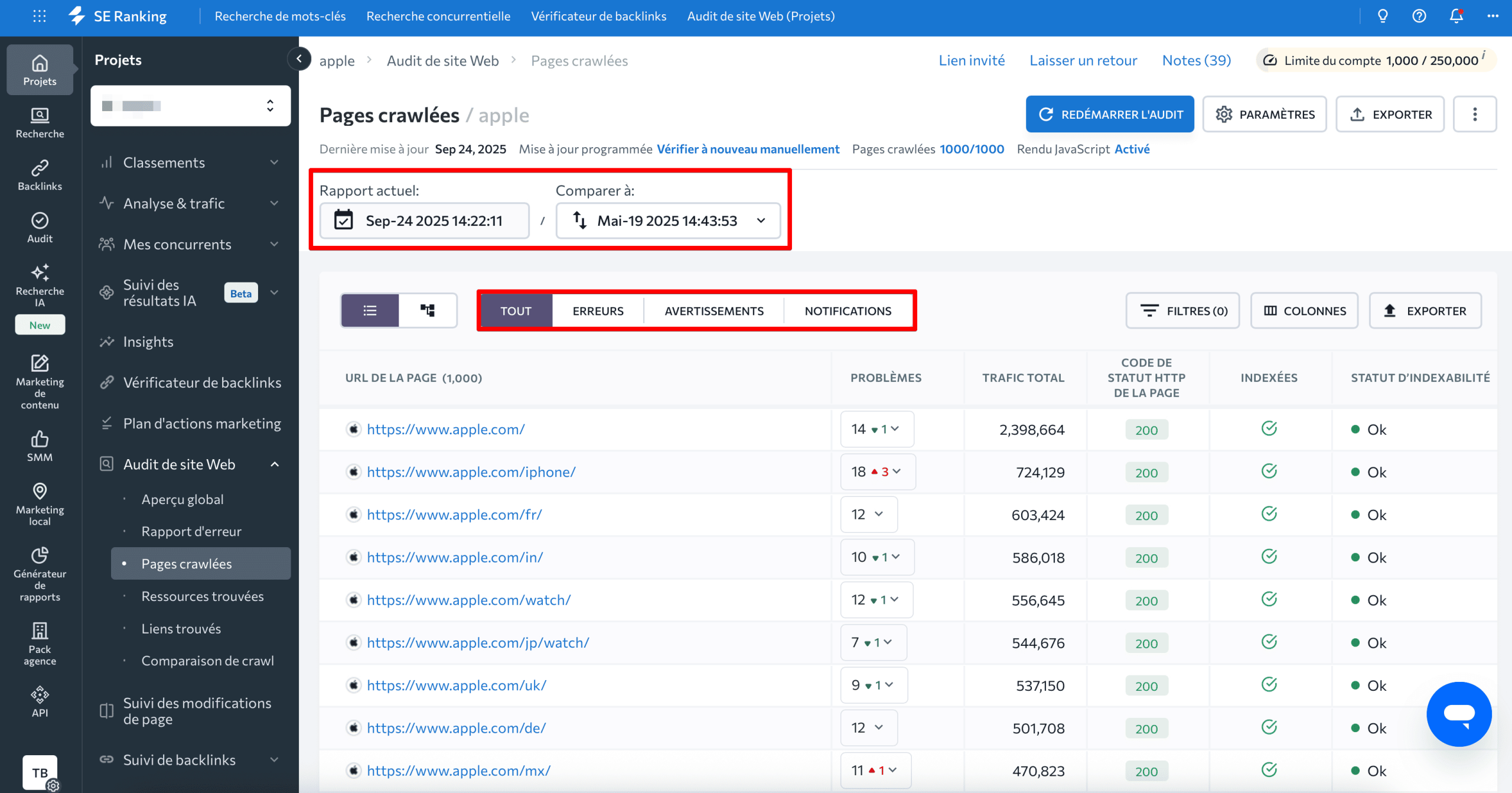
Il est également possible d’utiliser des filtres pour trier les pages selon différents paramètres. Par exemple, si vous ne voulez voir que 200 pages de code d’état, comme celles qui fonctionnent correctement, ajoutez un filtre comme celui-ci :
Il est maintenant temps d’exporter les résultats. Allez dans Exporter et choisissez d’enregistrer les données au format .xls ou .csv.
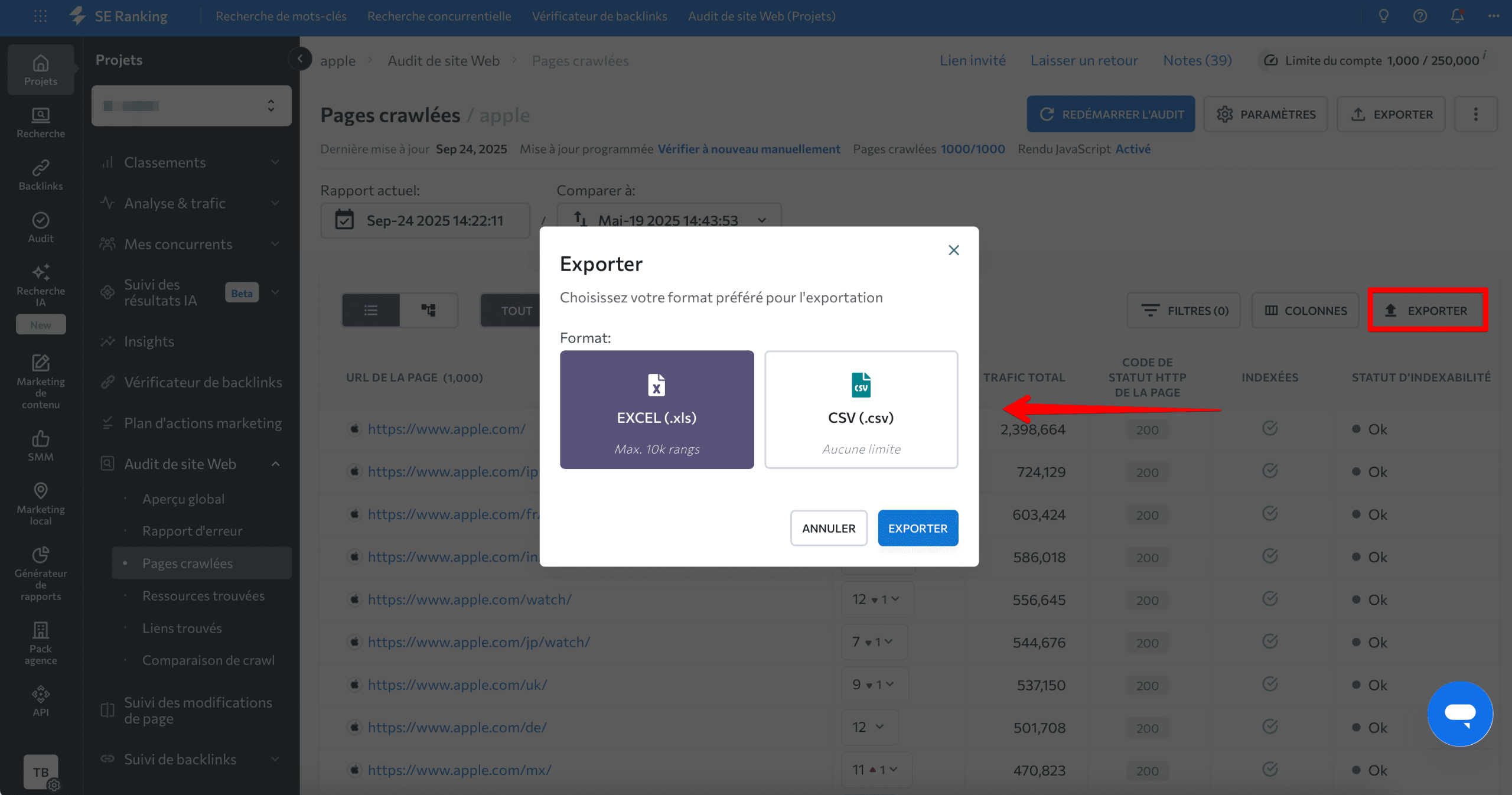
Trouver toutes les pages via Google Search Console
Un autre outil que vous pouvez utiliser pour trouver toutes les pages d’un site Web est Google Search Console. Gardez à l’esprit, cependant, que GSC ne vous montrera que les pages auxquelles Google peut accéder.
Commencez par ouvrir votre compte et rendez-vous dans l’onglet Indexation. Choisissez le rapport Pages et sélectionnez « Toutes les pages connues » au lieu de « Toutes les pages soumises ».
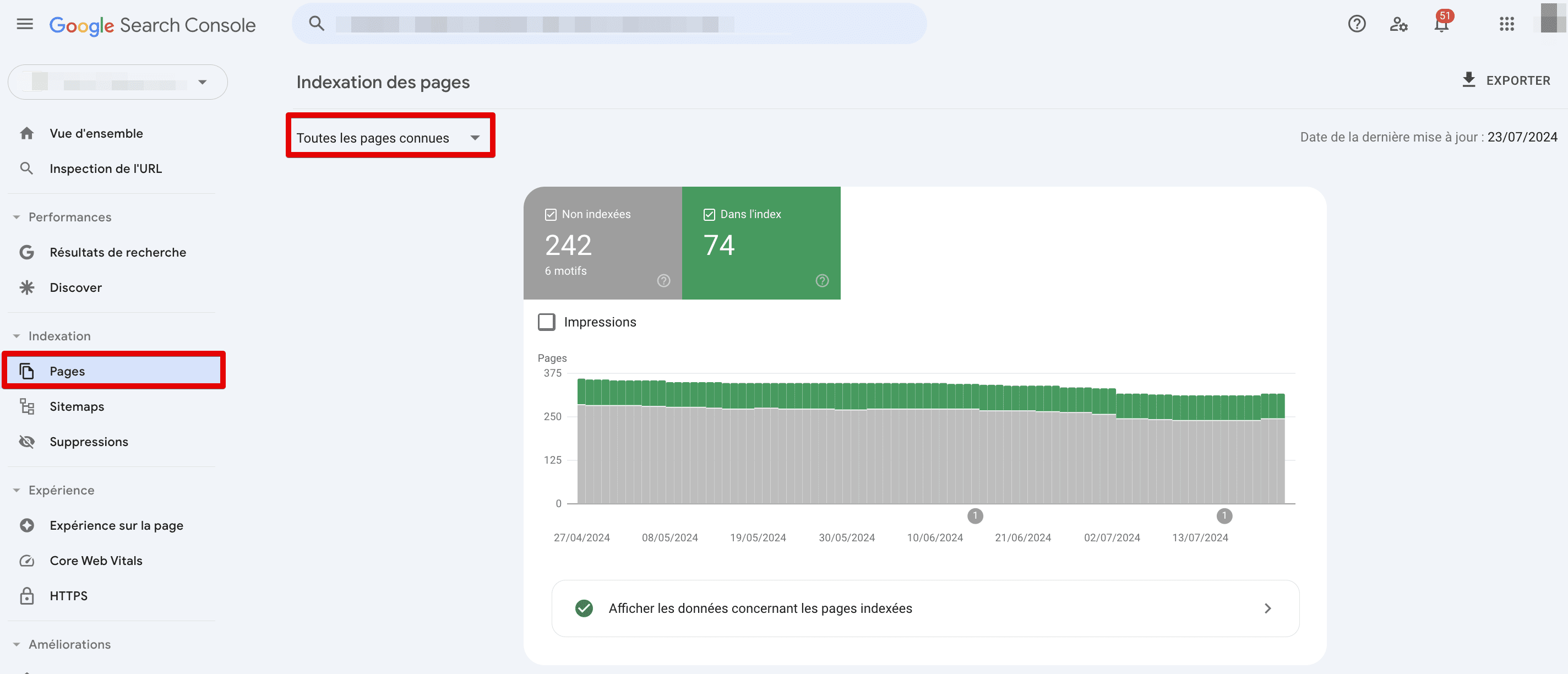
L’encadré vert intitulé « Indexé » vous indiquera le nombre d’URL indexées par Google. Cliquez sur « Afficher les données relatives aux pages indexées » sous le graphique. À partir de là, vous pouvez trouver toutes les URL d’un domaine indexé par Google, ainsi que la date de leur dernière exploration. Vous pouvez les exporter dans Google Sheets ou les télécharger sous forme de fichiers .xls ou .csv.
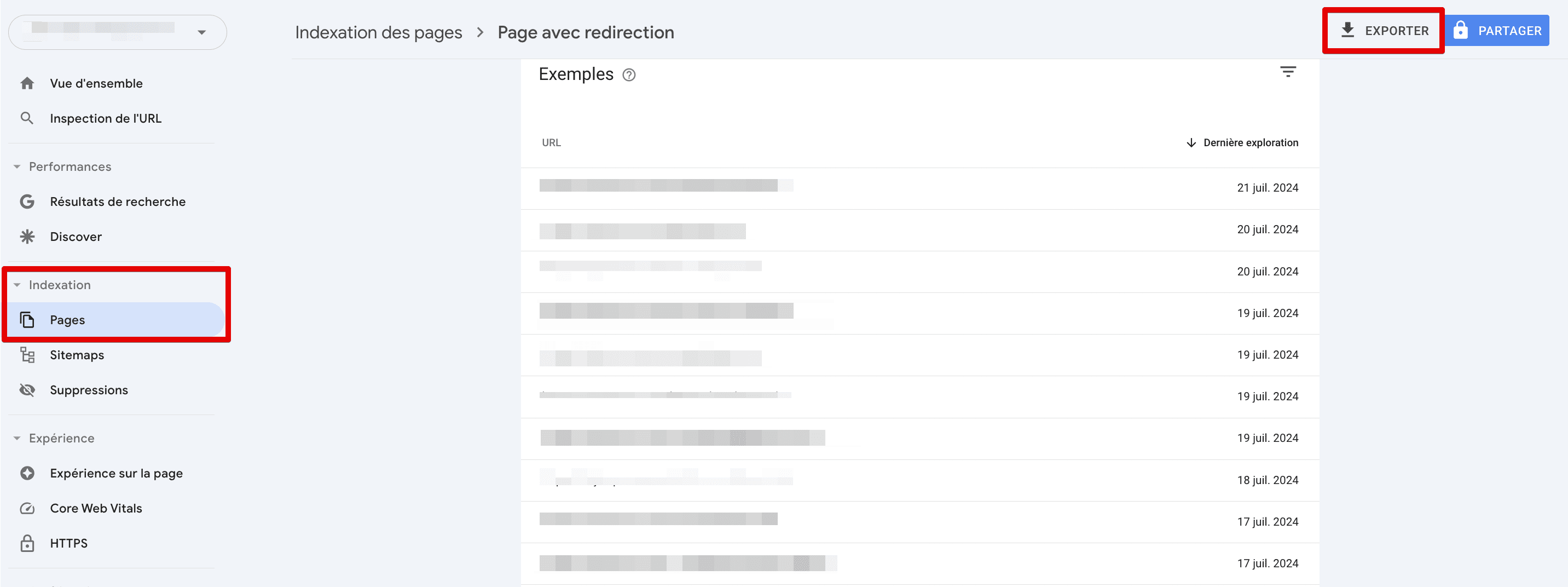
Revenons maintenant aux pages non indexées (pages qui n’ont pas été indexées et qui n’apparaîtront pas dans Google). Préparez-vous à faire du travail manuel.
Lorsque vous faites défiler la page vers le bas, vous verrez une liste des raisons pour lesquelles certaines pages de votre site Web ne sont pas indexées.
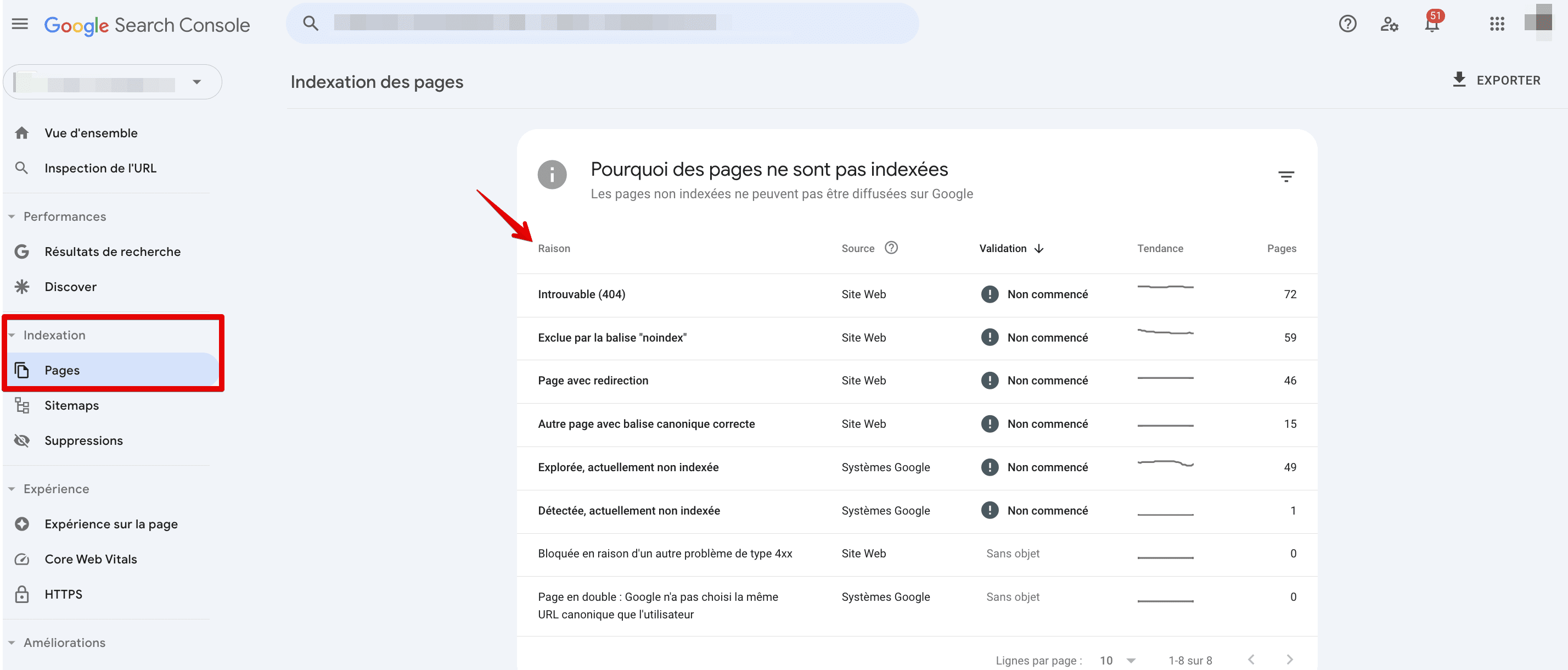
Vous pouvez afficher différentes catégories, telles que les erreurs de redirection, les pages exclues par la balise « noindex », celles bloquées par robots.txt, etc.
En cliquant sur la catégorie d’erreur, vous verrez la liste des pages concernées. En parcourant chacune d’entre elles, vous aurez un accès non filtré à chaque page découverte par Google sur votre site.
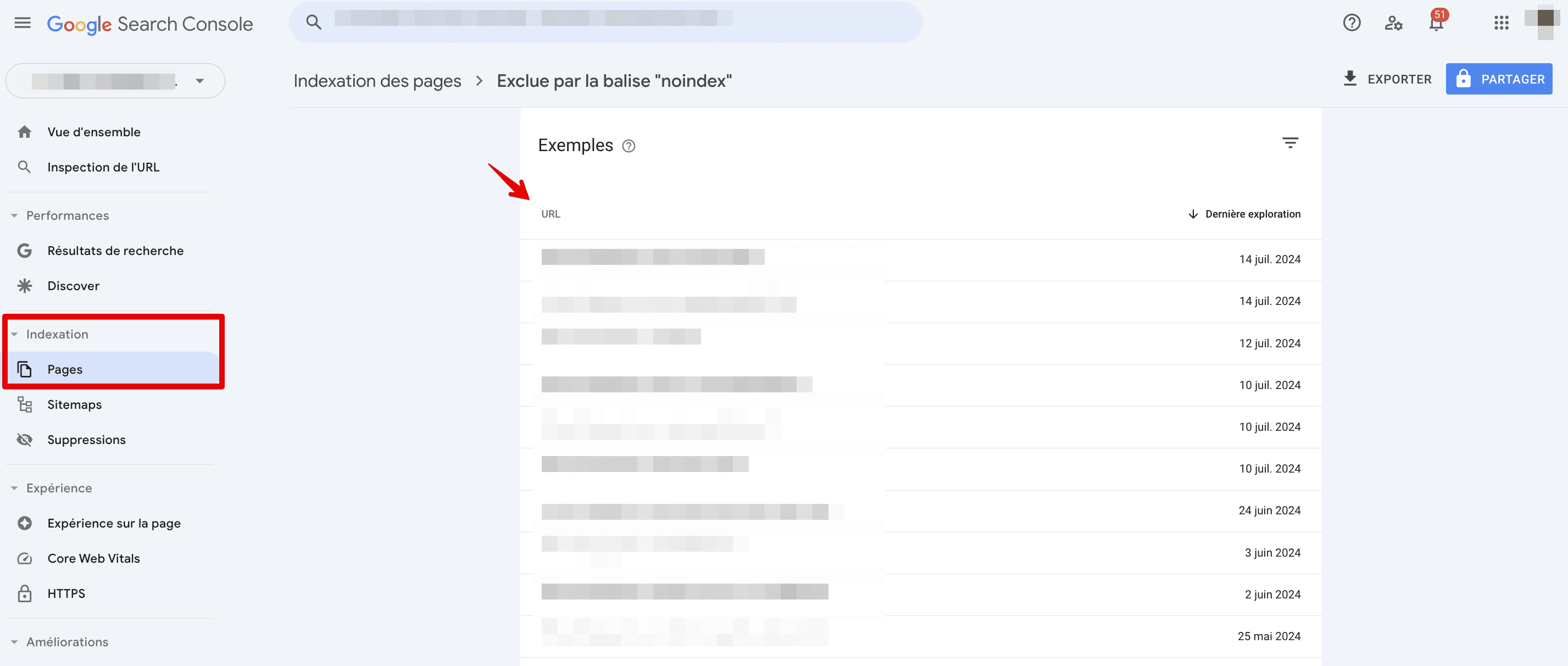
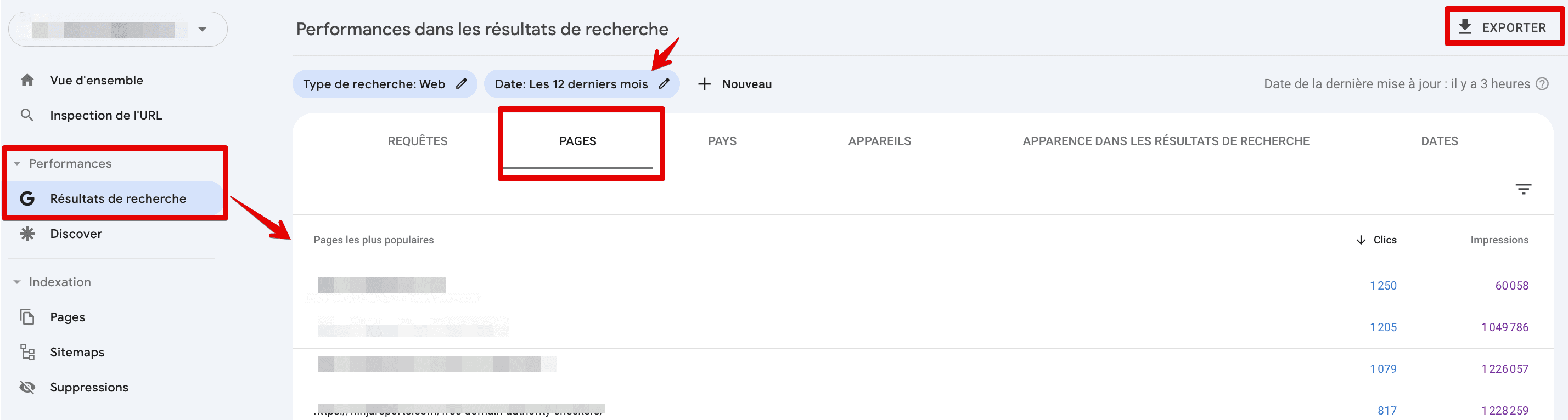
Le rapport sur les résultats de recherche est un autre rapport utile dans GSC pour trouver toutes les pages du site Web. Ce rapport affiche toutes les pages qui ont reçu au moins une impression dans les résultats de recherche. Pour y accéder, accédez aux résultats de recherche dans l’onglet Performances, définissez la période la plus longue possible et choisissez Pages. Enfin, exportez votre rapport.
Vous pouvez également utiliser le module complémentaire Search Analytics for Sheets pour récupérer les données de GSC à la demande et créer des sauvegardes automatiques dans Google Sheets.
Trouver toutes les pages grâce à Google Analytics
Vous pouvez également trouver toutes les pages du site Web en étudiant attentivement les données de votre compte Google Analytics. Il n’y a qu’une seule condition : votre site Web doit être lié à votre compte Google Analytics dès le départ, afin qu’il puisse collecter des données en arrière-plan.
La logique est simple : si quelqu’un a déjà visité une page de votre site Web, Google Analytics disposera des données pour le prouver. Et puisque ces visites sont effectuées par des personnes, nous devons nous assurer que ces pages ont un objectif de référencement ou de marketing distinct.
Commencez par accéder à Rapports → Engagement → Pages et écrans, puis cliquez sur Chemin de page et classe d’écran.
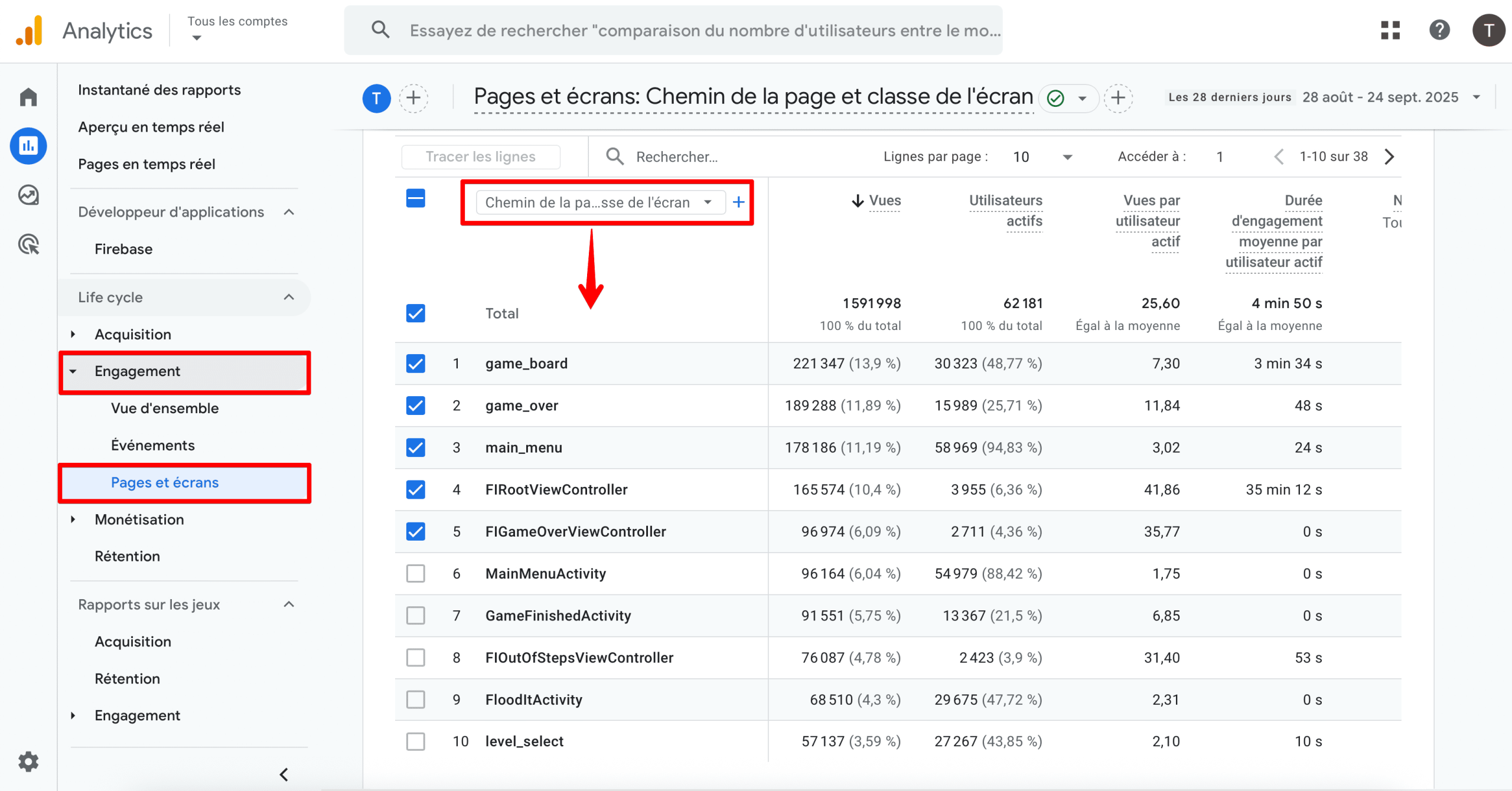
Vous pouvez également cliquer sur « Vues » pour faire pointer la flèche vers le haut et trier les URL des pages du moins au plus grand nombre de pages vues. En fin de compte, les pages les moins visitées seront affichées en haut de la liste.
Ensuite, partagez ou exportez les données dans un fichier .csv.
Recherche de toutes les pages du site Web à l’aide des outils Bing pour les webmasters
Google est considéré comme un géant de la recherche, mais Bing reste le deuxième moteur de recherche le plus populaire à ce jour. En janvier 2025, son marché de recherche mondial était de 4,04 %, ce qui fait de l’optimisation appropriée de votre site Web pour Bing une stratégie intelligente.
Vous pouvez également utiliser les outils Bing pour les webmasters pour trouver toutes les pages d’un site Web indexées par Bing. Le processus est simple, mais avant de commencer, assurez-vous d’avoir ajouté et vérifié votre site Web.
Une fois votre site configuré, accédez à Site Explorer dans la barre de navigation de gauche et choisissez de filtrer par « Toutes les URL ». Le rapport affichera toutes les pages que Bing voit sur votre site. Cliquez sur le bouton Télécharger pour exporter les données.
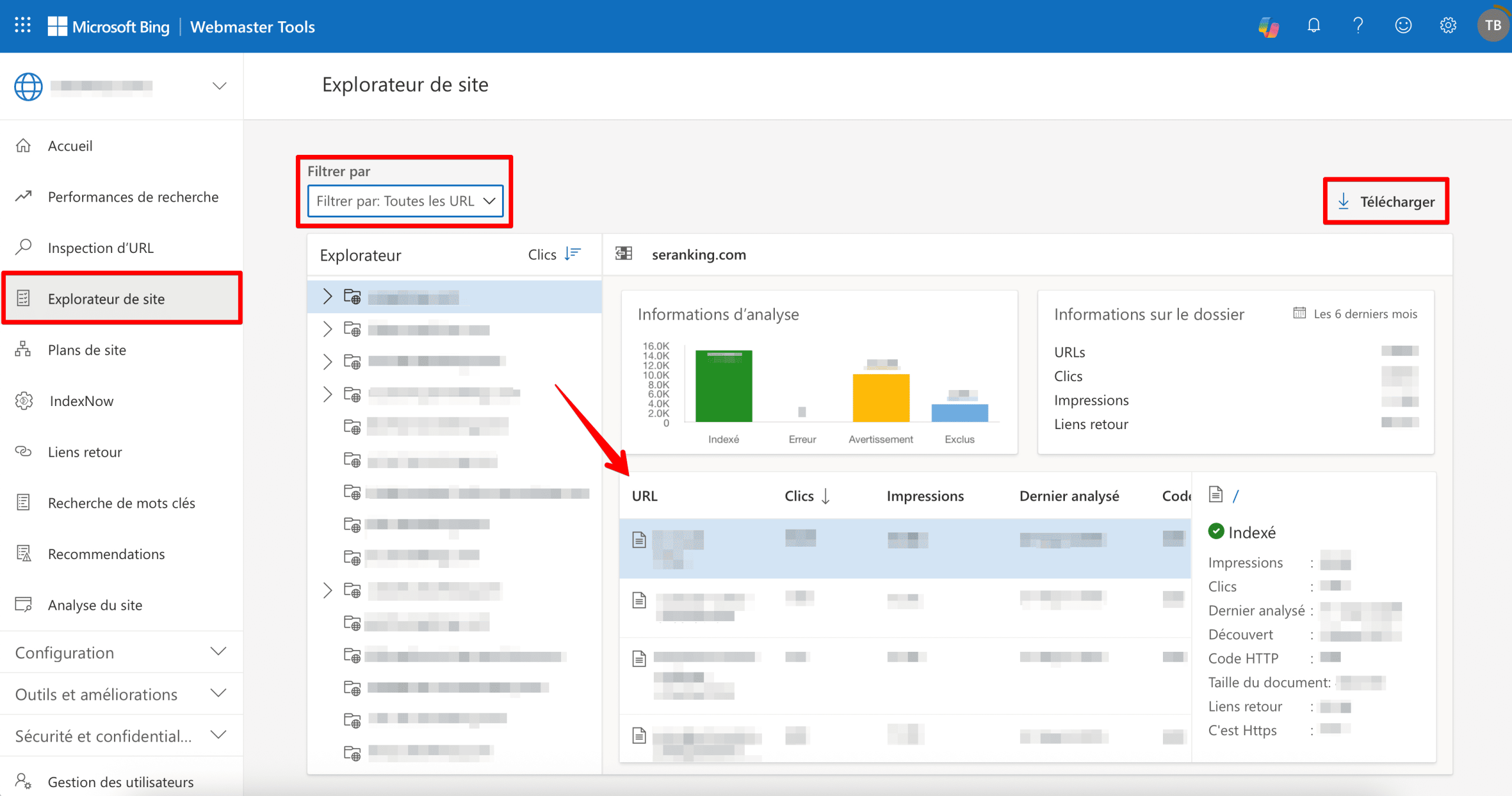
Rechercher toutes les pages d’un site Web à l’aide de Command Line Interface
Une approche plus technique pour trouver la liste de toutes les pages d’un site Web consiste à utiliser la ligne de commande. Cette méthode consiste à interagir avec un ordinateur par le biais de commandes textuelles.
Pour obtenir toutes les URL d’un site Web via la ligne de commande, vous devez d’abord installer Wget. Cet outil en ligne de commande vous permet de récupérer des fichiers sur le Web. Le processus d’installation varie en fonction du système d’exploitation que vous utilisez. Par exemple, macOS nécessite que vous installiez d’abord le gestionnaire de packages Homebrew avant d’installer des outils de ligne de commande tels que Wget.
Pour installer Wget, ouvrez une fenêtre de terminal et saisissez la commande suivante :
brew install wget
Ensuite, téléchargez votre site web. Entrez :
wget -r www.examplesite.com
Wget télécharge votre site web de manière récursive. Cela commencera par la page principale du site Web et toutes ses pages liées, images et autres fichiers. À partir de là, il suivra les liens de ces pages et téléchargera les pages vers lesquelles elles renvoient, et poursuivra ce processus jusqu’à ce qu’il ait téléchargé l’intégralité du site Web.
Une fois le site Web téléchargé, vous pouvez demander à Wget de répertorier les URL en tapant :
find www.examplesite.com
Recherche de toutes les pages du site Web via Sitemap.xml
Le plan de site XML est également un excellent moyen de trouver toutes les URL d’un site Web, car il fournit une liste de toutes les pages que le propriétaire souhaite que les moteurs de recherche indexent. Il fonctionne comme une feuille de route, guidant les robots des moteurs de recherche dans la structure du site et leur permettant de comprendre plus facilement comment tout est organisé.
Pour obtenir la liste, procédez comme suit :
- Localisez votre plan du site.
Le plan du site se trouve généralement dans le répertoire racine du site Web ou en tapant « /sitemap.xml » à la fin de l’URL du site Web, comme dans http://sitename.com/sitemap.xml. Si le site Web possède plusieurs sitemaps, ceux-ci seront répertoriés dans le fichier de plan du site principal, généralement nommé sitemap-index.xml. Ici, vous pouvez trouver une liste de plans de site et choisir le plus pertinent pour obtenir une liste des pages du site Web.
- Extrayez les URL de votre plan du site dans Google Sheets.
Bien qu’il s’agisse d’une autre méthode gourmande en technologie, elle vous fera gagner beaucoup de temps et d’efforts en important toutes les URL dans Google Sheets en quelques secondes seulement. Cependant, vous devrez d’abord effectuer quelques travaux préparatoires. Commencez par créer une nouvelle feuille, puis allez dans Extensions. Ensuite, choisissez « Apps Script ».
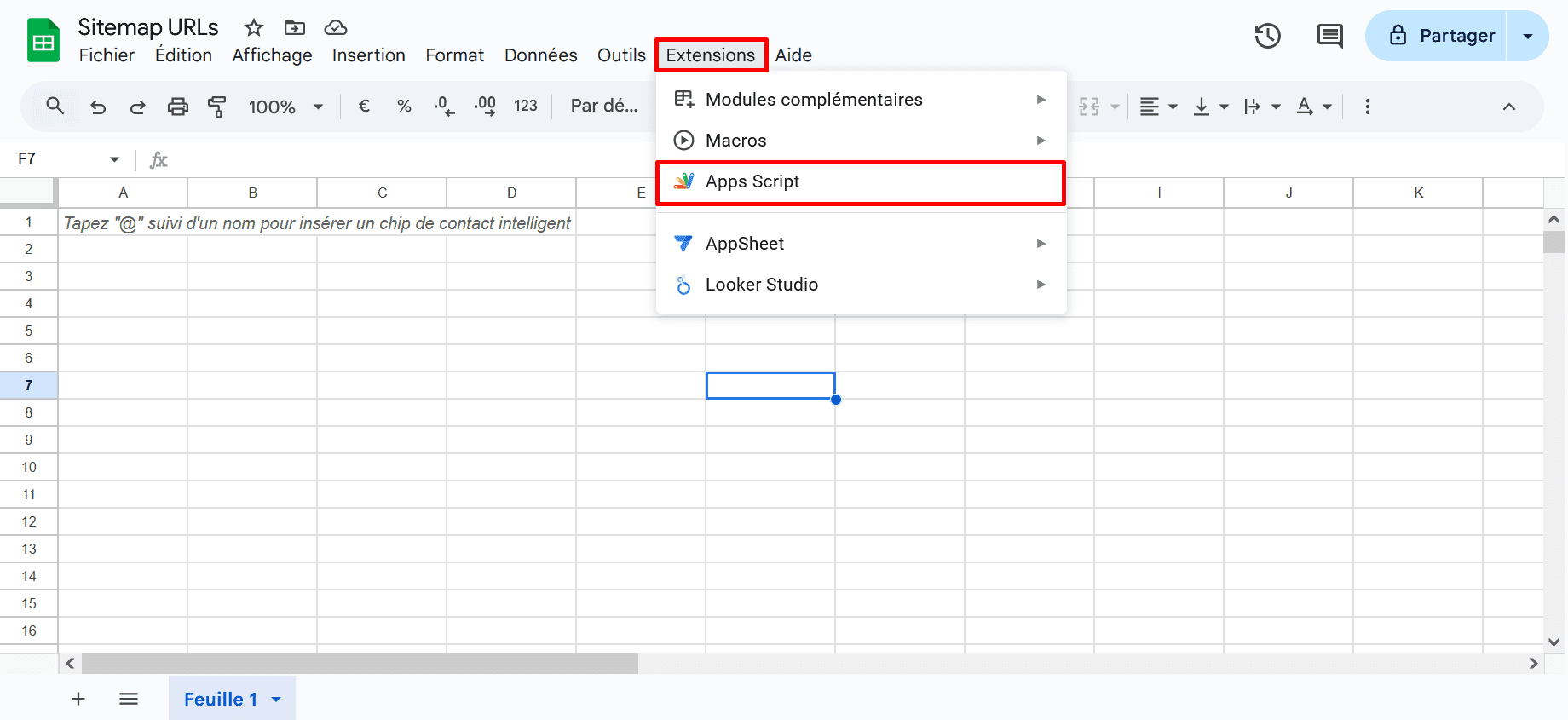
Vous devez maintenant copier et coller le code JavaScript personnalisé suivant dans l’éditeur de script pour créer une nouvelle fonction :
function sitemap(sitemapUrl,namespace) {
try {
var xml = UrlFetchApp.fetch(sitemapUrl).getContentText();
var document = XmlService.parse(xml);
var root = document.getRootElement()
var sitemapNameSpace = XmlService.getNamespace(namespace);
var urls = root.getChildren('url', sitemapNameSpace)
var locs = []
for (var i=0;i <urls.length;i++) {
locs.push(urls[i].getChild('loc', sitemapNameSpace).getText())
}
return locs
} catch (e) {
return e
}
}

À partir de là, enregistrez et exécutez le test. L’éditeur demandera une autorisation d’accès. Si le script est correctement implémenté, aucun message d’erreur n’apparaîtra. Au lieu de cela, vous verrez que l’exécution a commencé et s’est terminée.
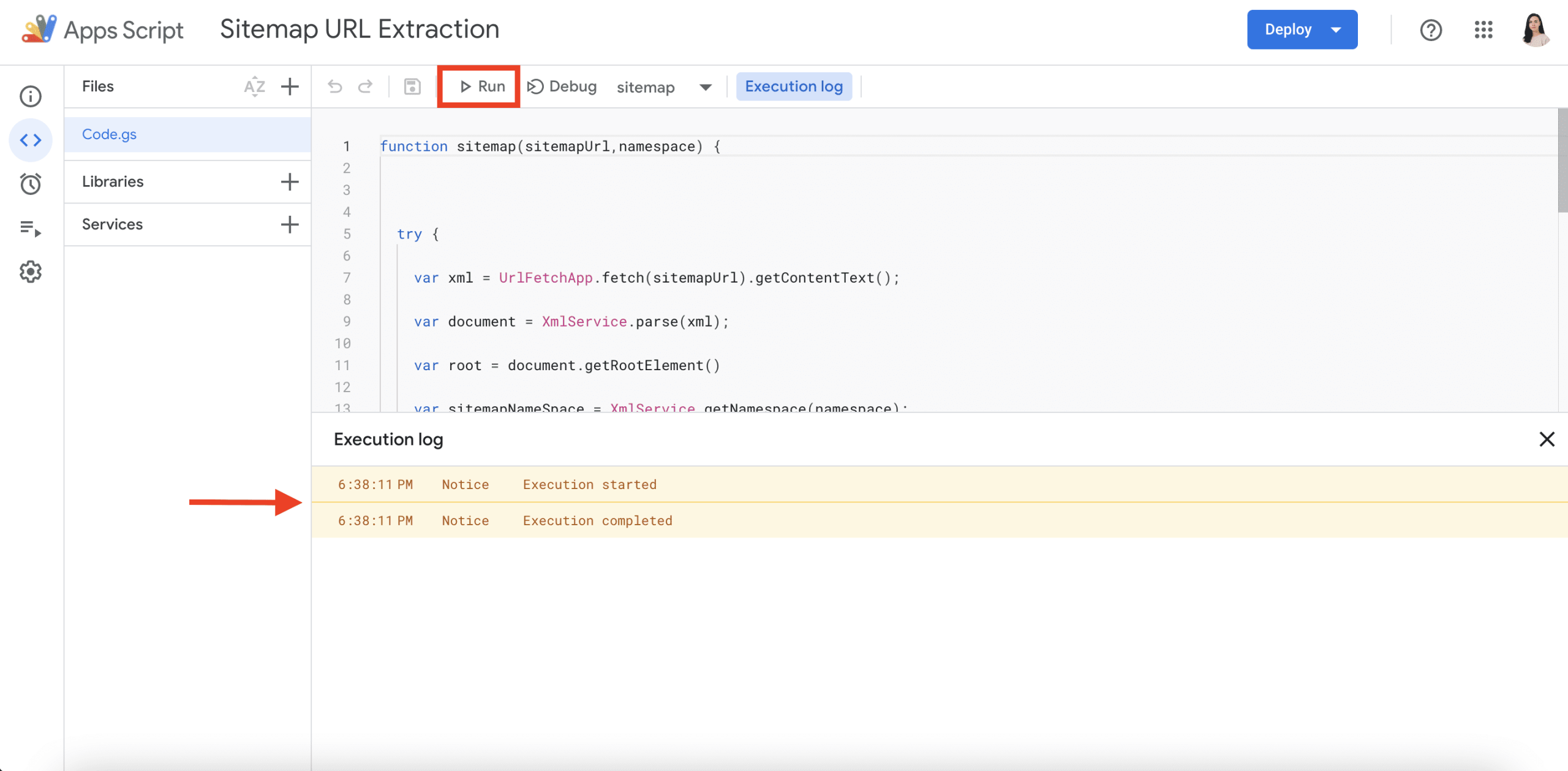
Vous pouvez maintenant revenir à votre feuille Google Sheet et saisir la formule suivante :
=sitemap("Sitemap Url", "Namespace Url")
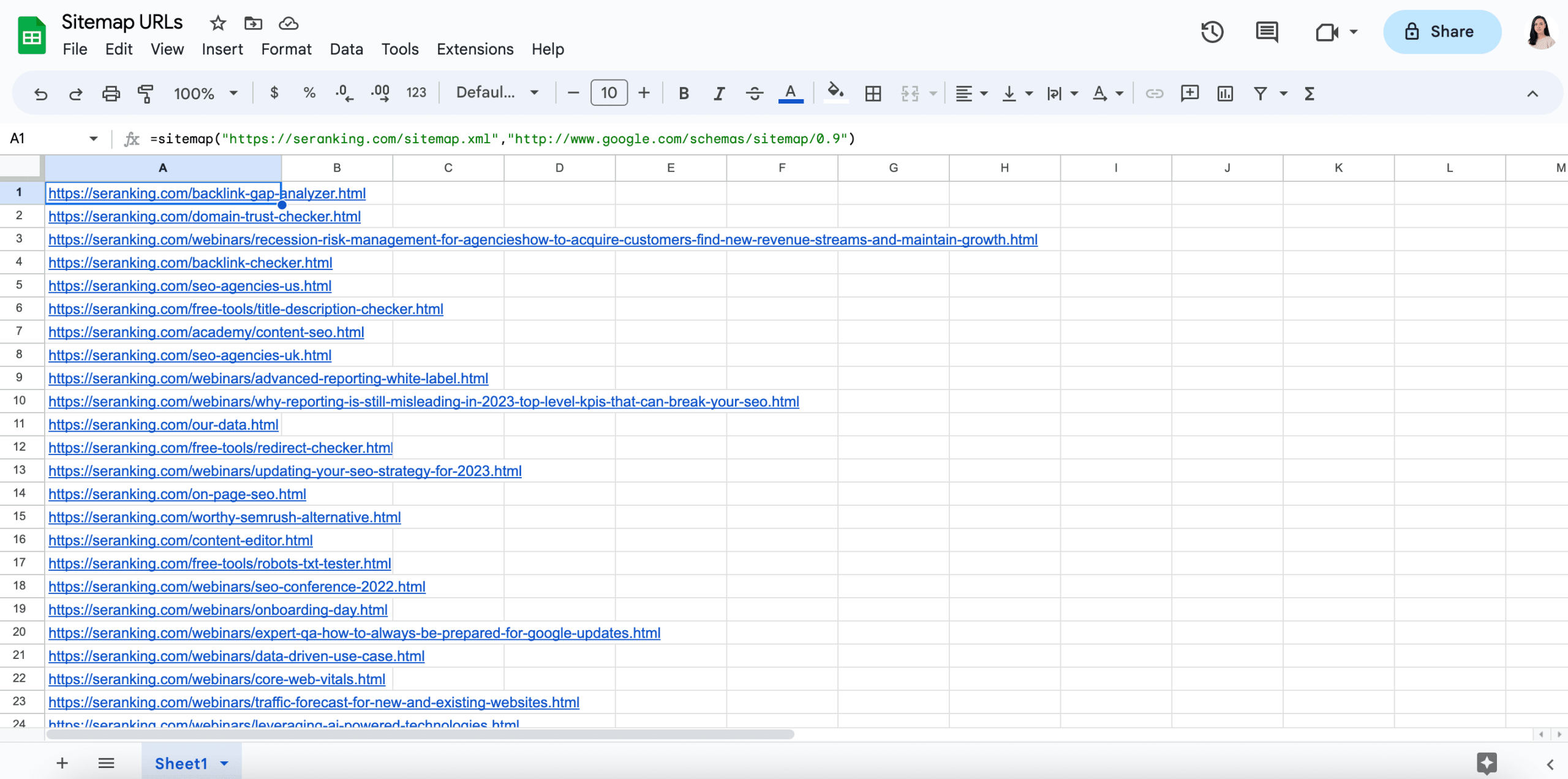
Une fois que vous avez localisé votre plan du site, vous devriez avoir l’URL du plan à portée de main, à partir de laquelle vous pouvez directement copier l’URL de l’espace de noms. Dans la capture d’écran ci-dessous, vous pouvez voir comment cela fonctionne avec le plan du site de SE Ranking :
- L’URL du plan du site se trouve dans la barre d’adresse du navigateur.
- L’URL de l’espace de noms se trouve dans la première ligne du contenu du plan du site.
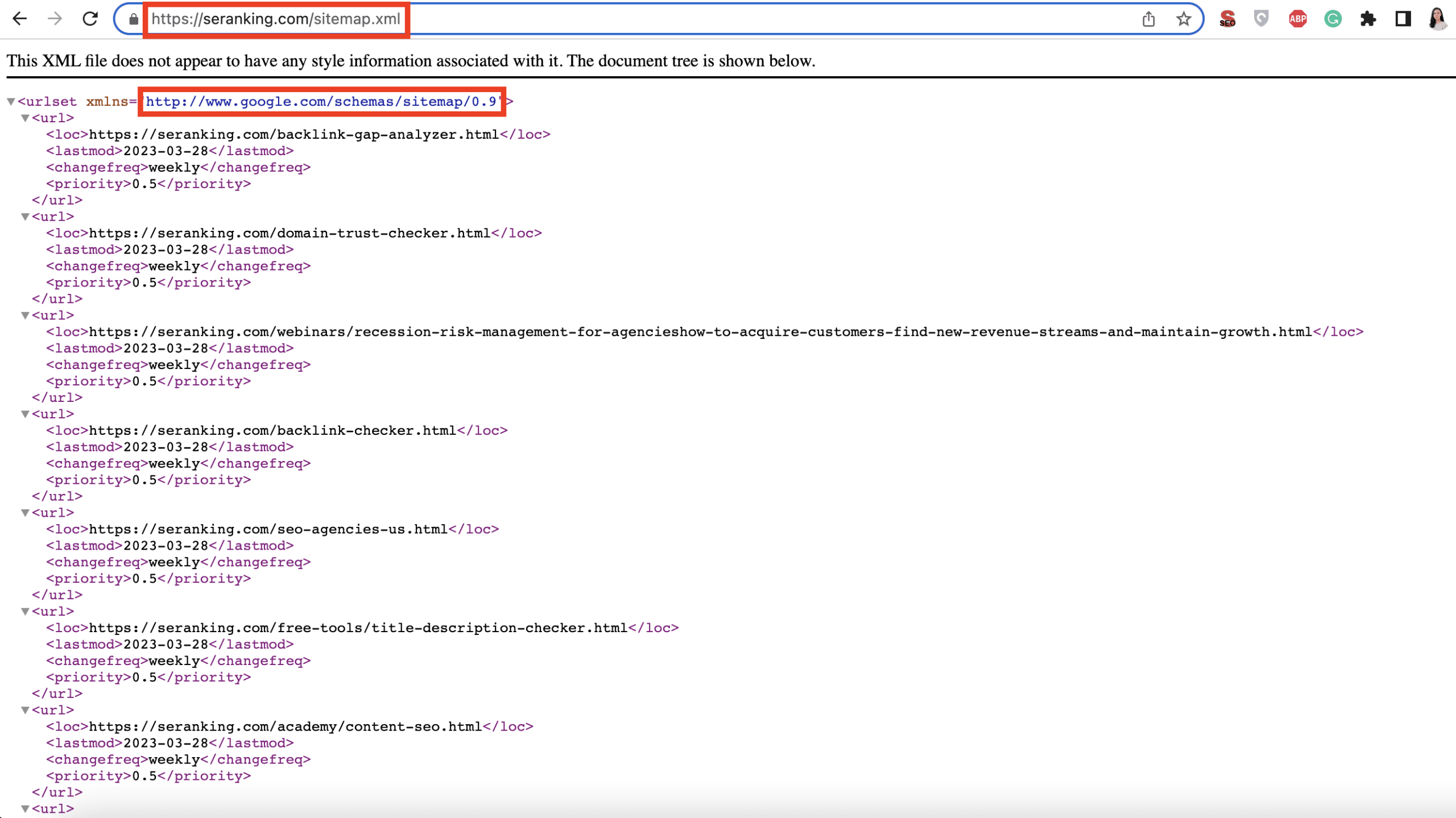
Copiez ces adresses et collez-les sous forme de liens dans la formule. Voici ce que vous devriez obtenir à la fin :
=sitemap("https://seranking.com/sitemap.xml","http://www.google.com/schemas/sitemap/0.9")
Collez cette formule dans votre feuille Google et appuyez sur Entrée pour obtenir toutes les URL extraites de votre plan du site.
Trouver toutes les pages du site Web via des plugins WordPress
Si votre site web fonctionne sur WordPress, il existe des plugins qui peuvent vous aider à retrouver toutes ses pages. Les deux options les plus couramment utilisées sont les suivantes :
Pour utiliser ces plugins, téléchargez-les et installez-les dans votre répertoire « /wp-content/plugins/ ». Une fois installés, activez-les depuis votre page Plugins dans WordPress. Une fois l’activation terminée, vous pouvez répertorier ou exporter toutes les URL de votre site Web.
Si vous utilisez un autre CMS, vérifiez s’il possède des plugins intégrés à cette fin ou s’il en a un distinct dans le répertoire des extensions. Par exemple, Joomla possède de nombreux plugins pour générer des plans de site afin de vous aider à obtenir une liste des pages du site Web. De même, Drupal dispose d’un module de plan du site qui peut s’avérer utile lors de la collecte des pages de votre site.
Comment voir toutes les pages d’un site Web sur Google
Nous avons discuté des différents outils qui peuvent vous aider à trouver toutes les pages de votre site Web, mais nous avons réservé l’option la plus simple pour la fin, et pour cause. Bien que cette méthode soit la plus simple, vous devez être prudent lorsque vous l’utilisez.
Recherchez votre site sur Google, mais faites-le correctement. Cela implique d’utiliser les opérateurs de recherche Google, qui sont des commandes spéciales qui affinent la recherche en fonction de critères définis.
Accédez simplement à la recherche Google et tapez « site:nom du site » comme dans « site:seranking.com ». Vous n’aurez pas besoin d’ajouter http:// ou www, mais assurez-vous qu’il n’y a pas d’espace entre l’opérateur et la requête ; sinon, les résultats seront incorrects.
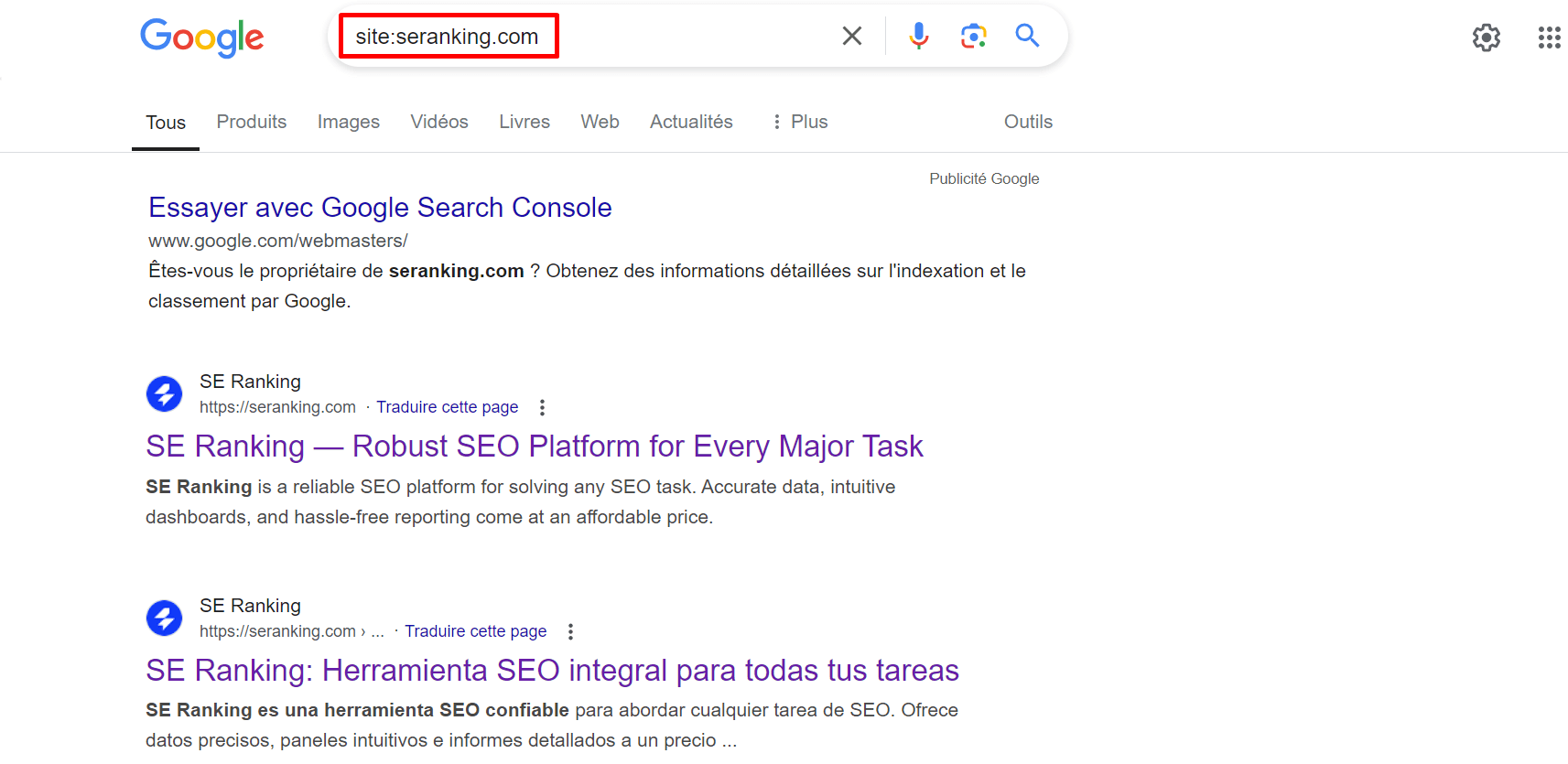
Vous devez tout de même tenir compte du fait que cette commande n’a pas été créée pour afficher toutes les pages indexées de votre site, ce que John Mueller de Google a confirmé.

Un dernier conseil est d’utiliser Google Search Console, mais d’une manière légèrement différente de celle expliquée dans les sections précédentes. Concentrez-vous sur les impressions de la page (le nombre de fois où la page a été affichée dans les résultats de recherche), mais pendant une courte période, par exemple sept jours.
Réflexions finales
Récupérer toutes les URLs d’un site permet de mieux comprendre la navigation. La localisation de toutes les pages de votre site Web est cruciale pour améliorer son référencement et constitue la première étape vers de nouvelles activités d’optimisation. Grâce à ces données, vous pouvez identifier les pages nécessitant une amélioration, mettre à jour le contenu obsolète, trouver tous les liens de sites Web et corriger ceux qui ne fonctionnent pas, et optimiser votre structure de liens interne globale.
En utilisant les outils et méthodes décrits dans cet article, vous pourrez rapidement voir toutes les pages d’un site Web et obtenir des informations précieuses sur ses performances. Alors, prenez un moment pour compiler une liste de pages afin de rester au top de vos efforts de référencement et de marketing. Prenez l’exemple de l’équipe SE Ranking : cela ne vous prendra pas beaucoup de temps lorsque vous utiliserez nos outils.

