¿Qué es el contenido duplicado en SEO y cómo identificarlo en tu sitio web?
Fácil de crear, difícil de eliminar y extremadamente perjudicial para tu sitio web: eso es el contenido duplicado en pocas palabras. Pero, ¿cuánto afecta realmente el contenido duplicado al SEO? ¿Cuáles son las razones técnicas y no técnicas detrás de la existencia de contenido duplicado? ¿Y cómo puedes encontrarlo y solucionarlo sobre la marcha? Sigue leyendo para obtener las respuestas a estos problemas clave y más.
¿Qué es el contenido duplicado?
El contenido duplicado es básicamente contenido copiado y pegado, reciclado (o ligeramente modificado), clonado o reutilizado que aporta poco o ningún valor a los usuarios y confunde a los motores de búsqueda. La duplicación de contenido ocurre con mayor frecuencia dentro de un solo sitio web o en diferentes dominios.
Tener contenido duplicado dentro de un solo sitio web significa que varias URL de tu sitio muestran el mismo contenido (a menudo sin intención). Este contenido generalmente toma la forma de:
- Publicaciones antiguas de blog que se volvieron a publicar sin valor agregado.
- Páginas con contenido idéntico o ligeramente modificado.
- Contenido extraído o agregado de otras fuentes.
- Páginas generadas por IA con texto mal reescrito.
El contenido duplicado en diferentes dominios significa que tienes contenido que aparece en más de un lugar en diferentes sitios externos. Esto podría verse así:
- Contenido copiado o robado publicado en otros sitios web.
- Contenido que se distribuye sin permiso.
- Contenido idéntico o apenas editado en sitios de la competencia.
- Artículos reescritos que están disponibles en varios sitios web.
¿El contenido duplicado perjudica al SEO?
¿La respuesta rápida? Sí, lo hace. Pero el impacto del contenido duplicado en SEO depende en gran medida del contexto y los parámetros técnicos de la página con la que estás tratando.
Según los motores de búsqueda, tener contenido duplicado en tu sitio web (por ejemplo, publicaciones de blog o páginas de productos muy similares) puede reducir el valor y la autoridad de ese contenido. Esto se debe a que los motores de búsqueda tendrán dificultades para determinar qué página debería tener una posición más alta. Sin mencionar que los usuarios se sentirán frustrados si no pueden encontrar nada útil después de llegar a tu página.
Por otro lado, si otro sitio web toma o copia tu contenido sin permiso (lo que significa que no estás sindicando tu contenido), es probable que no dañe directamente el rendimiento de tu sitio web ni la visibilidad de búsqueda. Mientras tu contenido sea la versión original, sea de calidad y realices pequeños ajustes con el tiempo, los motores de búsqueda seguirán identificando tus páginas como tales. El sitio que extrae contenido duplicado puede tomar algo de tráfico, pero es casi seguro que no superará a tu sitio original en las SERP, según las explicaciones de Google.
Cómo aborda Google el contenido duplicado
Si bien Google dice oficialmente que “no existe una “penalización por contenido duplicado”, siempre hay algunos peros, lo que significa que debes leer entre líneas. Incluso si no hay una penalización directa, aún puede dañar tu SEO de manera indirecta.
En concreto, Google ve como una señal de alerta si copias contenido intencionalmente de otros sitios y lo vuelves a publicar sin agregar ningún valor. Google se esforzará por identificar la versión original entre páginas similares e indexar esa. Todas ellas tendrán dificultades para posicionarse. Esto significa que el contenido duplicado puede generar posiciones más bajas, menor visibilidad y poco tráfico.
Otro caso de “detención” es cuando intentas crear numerosas páginas, subdominios o dominios que muestran contenido notablemente similar. Esto puede convertirse en otra razón por la que tu rendimiento SEO disminuye.
Además, ten en cuenta que cualquier motor de búsqueda es esencialmente un negocio. Y como cualquier negocio, no quiere desperdiciar sus esfuerzos en vano. Por lo tanto, existe un presupuesto de rastreo establecido para un solo sitio web, que es un límite de recursos web que los robots de búsqueda rastrearán e indexarán. El presupuesto de rastreo de Googlebot se agotará antes si tiene que dedicar más tiempo y recursos a cada página duplicada. Esto limita sus posibilidades de llegar al resto de tu contenido.
Otro caso de “detención” es cuando vuelves a publicar contenido de afiliados de Amazon u otros sitios web sin agregarle mucho valor único. Al proporcionar exactamente los mismos listados, estás dejando que Google maneje estos problemas de contenido duplicado por ti. Luego, el buscador realizará los ajustes necesarios de indexación y posicionamiento del sitio lo mejor que pueda.
Esto sugiere que los propietarios de sitios web bien intencionados no serán penalizados por Google si encuentran problemas técnicos en su sitio, siempre que no intenten manipular intencionalmente los resultados de búsqueda.
Por lo tanto, si no creas contenido duplicado a propósito, está bien. Además, como dijo Matt Cutts sobre cómo Google ve el contenido duplicado: “Alrededor del 25 o 30% de todo el contenido de la web es contenido duplicado”. Como siempre, solo debes seguir la regla de oro: crea contenido único y de valor para brindar mejores experiencias de usuario y rendimiento del motor de búsqueda.
Contenido duplicado y generado por IA
Otro problema creciente que hay que tener en cuenta hoy en día es el contenido creado con herramientas de IA. Esto puede provocar contenido duplicado si no se tiene cuidado. Una cosa está clara: el contenido generado por IA básicamente reúne información de otros lugares sin añadir ningún valor adicional. Si utiliza las herramientas de IA sin cuidado, simplemente escribiendo una indicación y copiando el resultado, no te sorprendas si es marcado como contenido duplicado y arruina el rendimiento de tu SEO. Recuerda también que tus competidores pueden hacer lo mismo y generar contenido muy similar.
Aunque dicho contenido de IA puede pasar técnicamente las comprobaciones de plagio (cuando se verifica con herramientas especiales), Google es capaz de determinar el texto creado con poco valor añadido y su experiencia original según sus estándares EEAT. Aunque no se trata de una penalización directa, solo hay que saber que utilizar solo contenido generado por IA puede dificultar que tu contenido tenga un buen rendimiento en las búsquedas, ya que su naturaleza repetitiva se hace evidente con el tiempo.
Para evitar el contenido duplicado en SEO, es fundamental asegurarse de que todo el contenido de un sitio web sea único y ofrezca valor. Esto se puede lograr creando contenido original, utilizando correctamente las etiquetas canónicas y evitando el scraping de contenido u otras tácticas de black hat SEO.
Por ejemplo, utilizando la herramienta de Auditoría SEO On-page de SE Ranking, puedes realizar un análisis detallado de la singularidad del contenido, la densidad de palabras clave, el recuento de palabras en comparación con las páginas de la competencia que mejor se posicionan, así como el uso de encabezados en la página. Además del contenido, esta herramienta analiza elementos clave en la página como etiquetas de título, meta descripciones, etiquetas de encabezado, enlaces internos, estructura de URL y palabras clave. Por lo que, aprovechando esta herramienta, puedes producir contenido que sea único y valioso.
Tipos de contenido duplicado
Existen dos tipos de problemas de contenido duplicado en SEO:
- Contenido duplicado en todo el sitio o entre dominios
Esto ocurre cuando se publica el mismo contenido o contenido muy similar en varias páginas de un mismo sitio o en dominios separados. Por ejemplo, una tienda online puede usar las mismas descripciones de productos en el dominio principal store.com, m.store.com o la versión de dominio local store.ca, lo que genera contenido duplicado. Si el contenido duplicado se extiende a lo largo de dos o más sitios web, se trata de un problema mayor que podría requerir una solución diferente.
- Contenido copiado o problemas técnicos
El contenido duplicado puede surgir de la copia directa de contenido a varios lugares o de problemas técnicos que hacen que el mismo contenido aparezca en varias URL diferentes. Algunos ejemplos incluyen la falta de etiquetas canónicas en las URL con parámetros, páginas duplicadas sin la directiva noindex y contenido copiado que se publica sin la redirección adecuada. Sin una configuración adecuada de etiquetas canónicas o redirecciones, los motores de búsqueda pueden indexar e intentar posicionar versiones casi idénticas de las páginas.
Cómo comprobar si hay problemas de contenido duplicado
Para comenzar, definamos los diferentes métodos para detectar problemas de contenido duplicado. Si te centras en los problemas dentro de un dominio, puedes utilizar:
La herramienta de Auditoría Web de SE Ranking. Esta herramienta puede ayudarte a encontrar todas las páginas de tu sitio web, incluidas las duplicadas. En la sección Contenido Duplicado de nuestra herramienta de Auditoría Web, encontrarás una lista de páginas que contienen el mismo contenido debido a razones técnicas: URL accesibles con y sin www, con y sin símbolos de barra, etc. Si has utilizado la etiqueta canonical para resolver el problema de duplicación, pero especificas varias URL canónicas, la auditoría también resaltará este error.
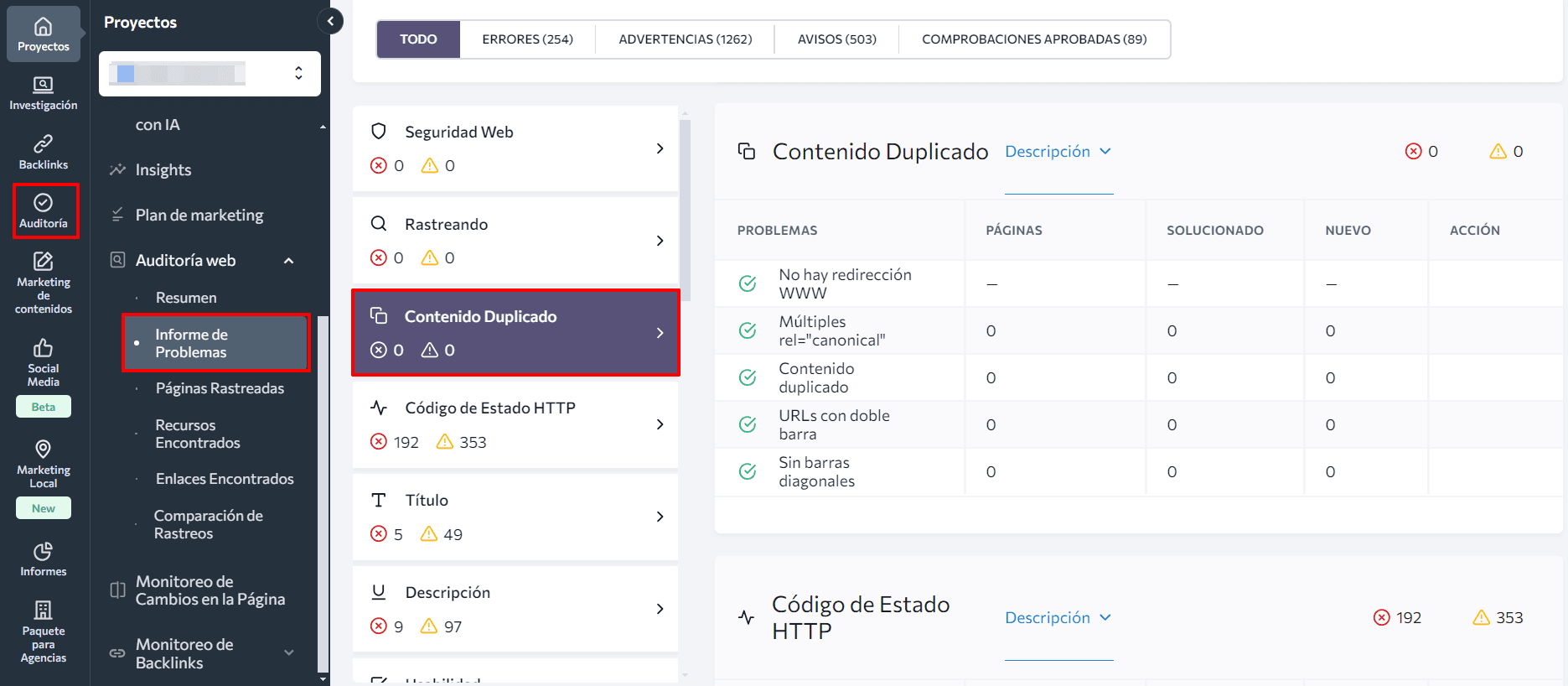
Después, mira la pestaña Páginas Rastreadas que aparece a continuación. Puedes encontrar más indicios de problemas de contenido duplicado si observas páginas con títulos o etiquetas de encabezado similares. Para ver un resumen, configura las columnas que necesitas.
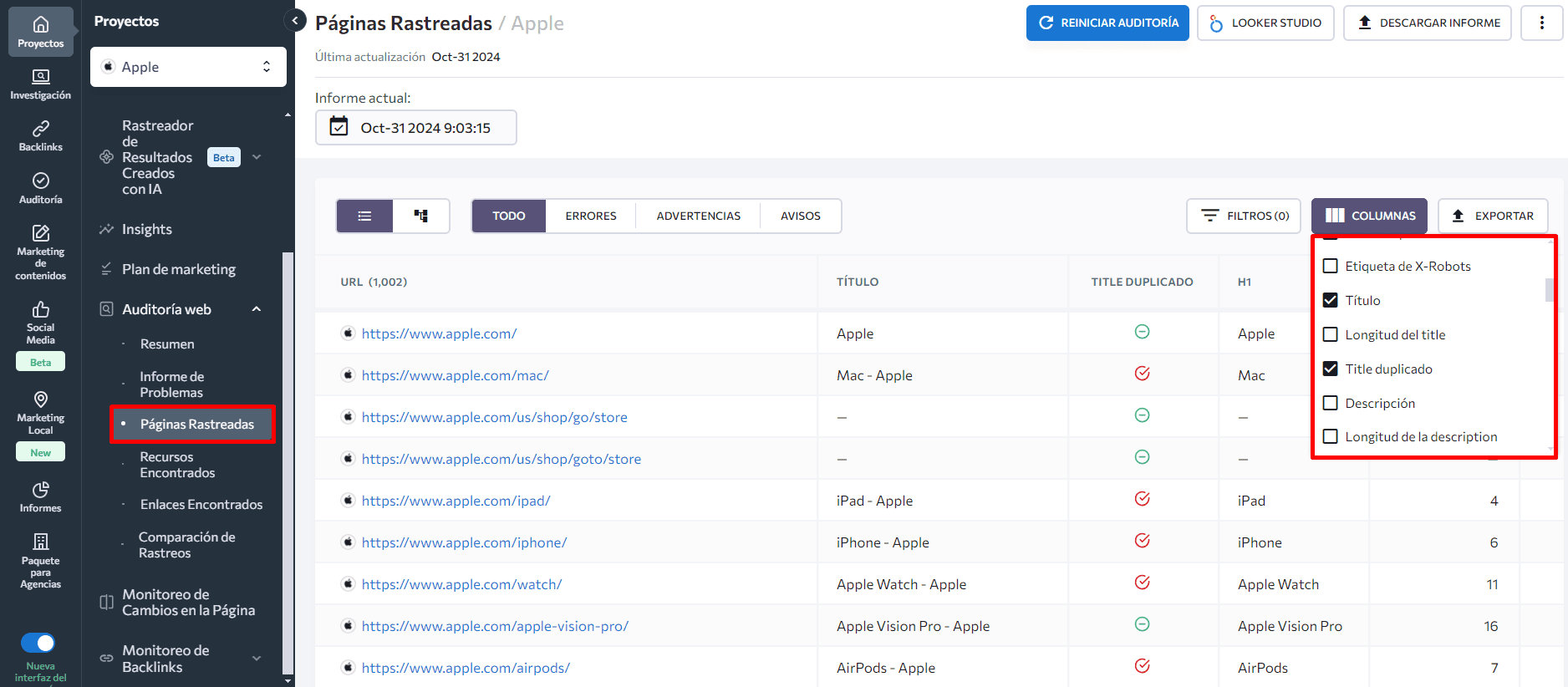
Para encontrar la mejor herramienta para tus necesidades, explora la herramienta de auditoría de SE Ranking y compárala con otras herramientas de auditoría web.
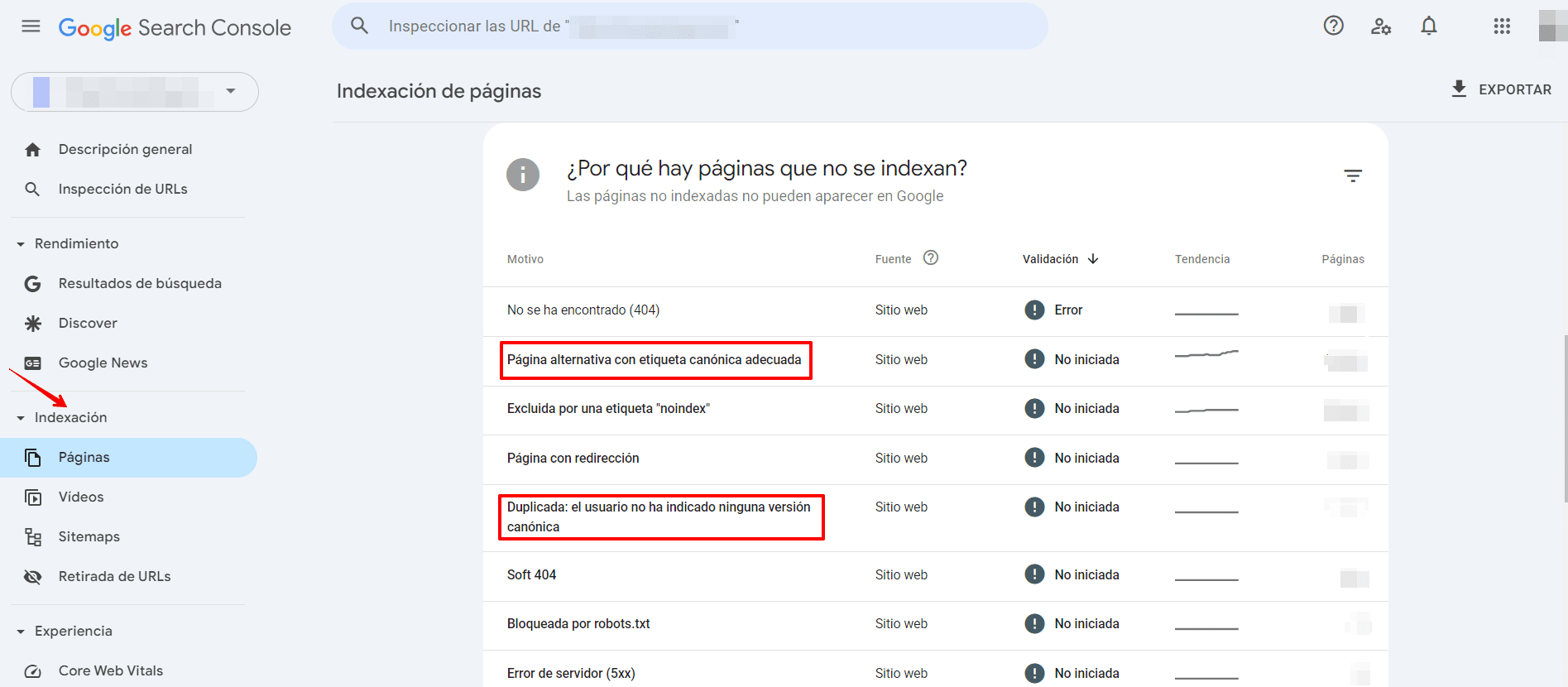
Google Search Console también puede ayudarte a encontrar contenido idéntico.
- En la pestaña Indexación, ve a Páginas.
- Presta atención a los siguientes problemas:
- Duplicado sin la versión canónica seleccionada por el usuario: Google encontró URL duplicadas sin una versión preferida establecida. Usa la herramienta Inspección de URL para saber qué URL cree Google que es canónica para esta página. Ahora bien, esto no es un error. Sucede porque Google prefiere no mostrar el mismo contenido dos veces. Pero si crees que Google canonizó la URL incorrecta, marca la canónica de forma más explícita. O, si no crees que esta página sea un duplicado de la URL canónica seleccionada por Google, asegúrate de que las dos páginas tengan contenido claramente distinto.
- Página alternativa con la etiqueta canónica adecuada: Google ve esta página como una alternativa de otra página. Podría ser una página AMP con una versión canónica de escritorio, una versión móvil de una versión canónica de escritorio o viceversa. Esta página se vincula a la página canónica correcta, que está indexada, por lo que no es necesario cambiar nada. Ten en cuenta que Search Console no detecta páginas en otros idiomas.
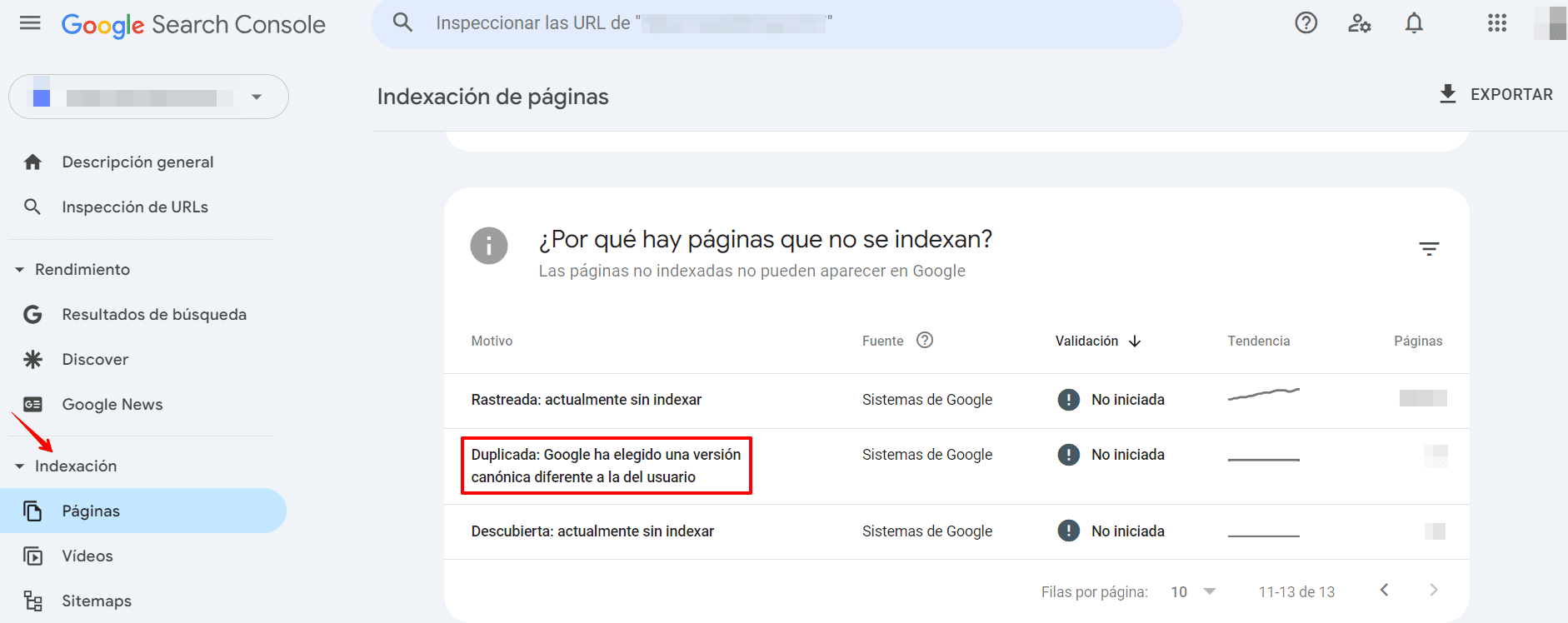
- Duplicado, Google ha eligido una URL canónica diferente a la del usuario: Google marca esta página como la canónica para un grupo de páginas, pero sugiere que una URL diferente sería la más apropiada. Google no indexa esta página en sí, sino la que considera canónica.
Elige uno de los métodos que se enumeran a continuación para encontrar problemas de contenido duplicado en diferentes dominios.
- Usa la Búsqueda de Google: los operadores de búsqueda pueden ser muy útiles. Intenta buscar contenido duplicado en Google usando un fragmento de texto de tu página entre comillas. Esto es útil porque el contenido copiado o distribuido puede tener una mejor posición que tu contenido original.
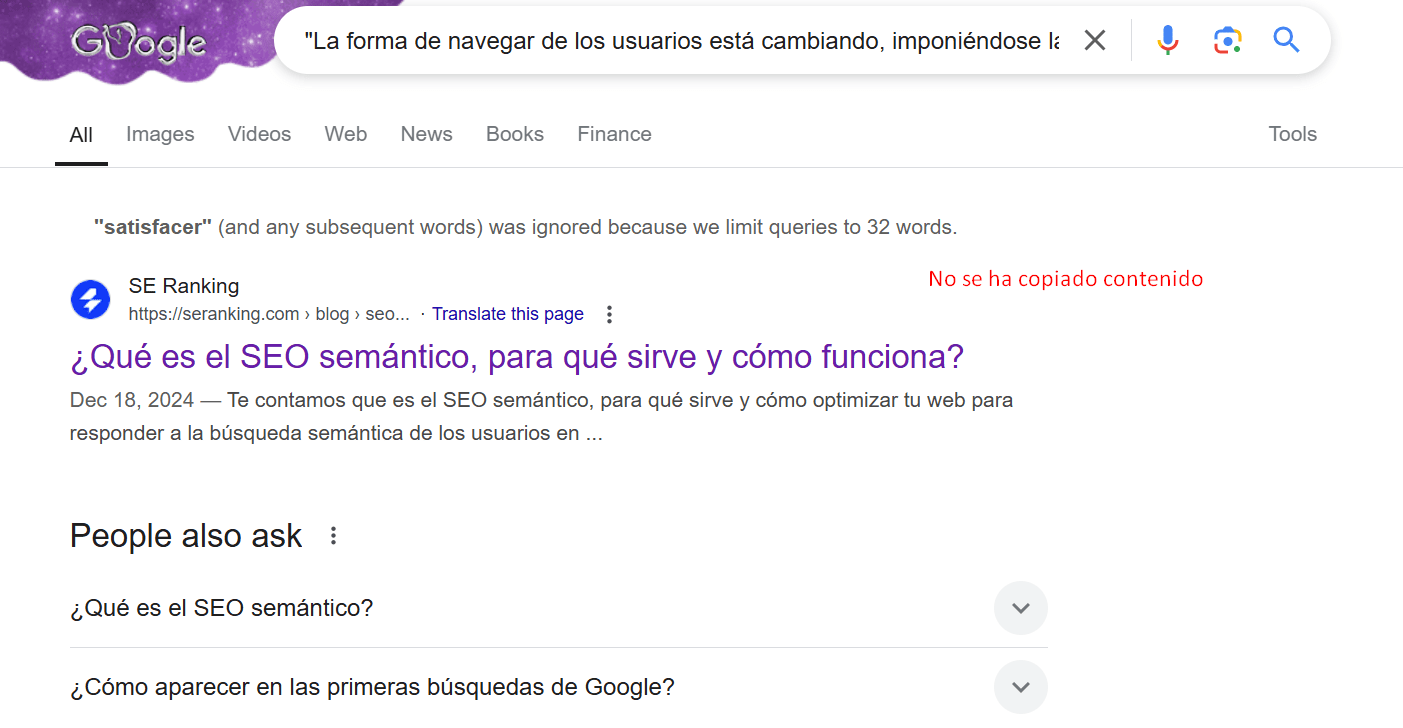
- Usa el Comprobador de SEO On-Page para examinar el contenido de URL específicas: esto intensifica tus esfuerzos en analizar el contenido manualmente. Esta herramienta utiliza 94 parámetros clave para evaluar tu página, incluida la singularidad del contenido.
Para ello, desplázate hacia abajo hasta la pestaña Contenido de texto dentro del Comprobador de SEO On-Page. Aquí verás si la singularidad de tu contenido se encuentra dentro del nivel recomendado.
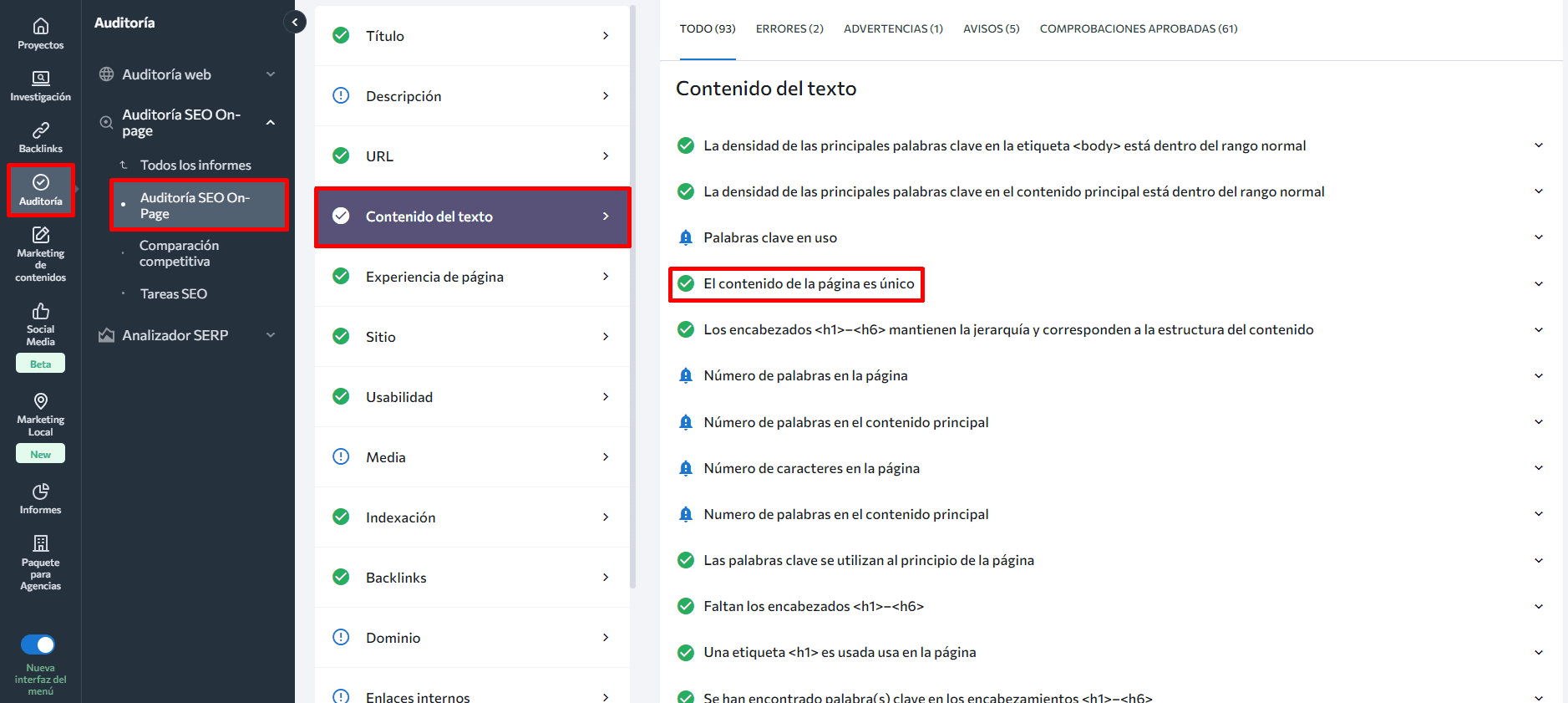
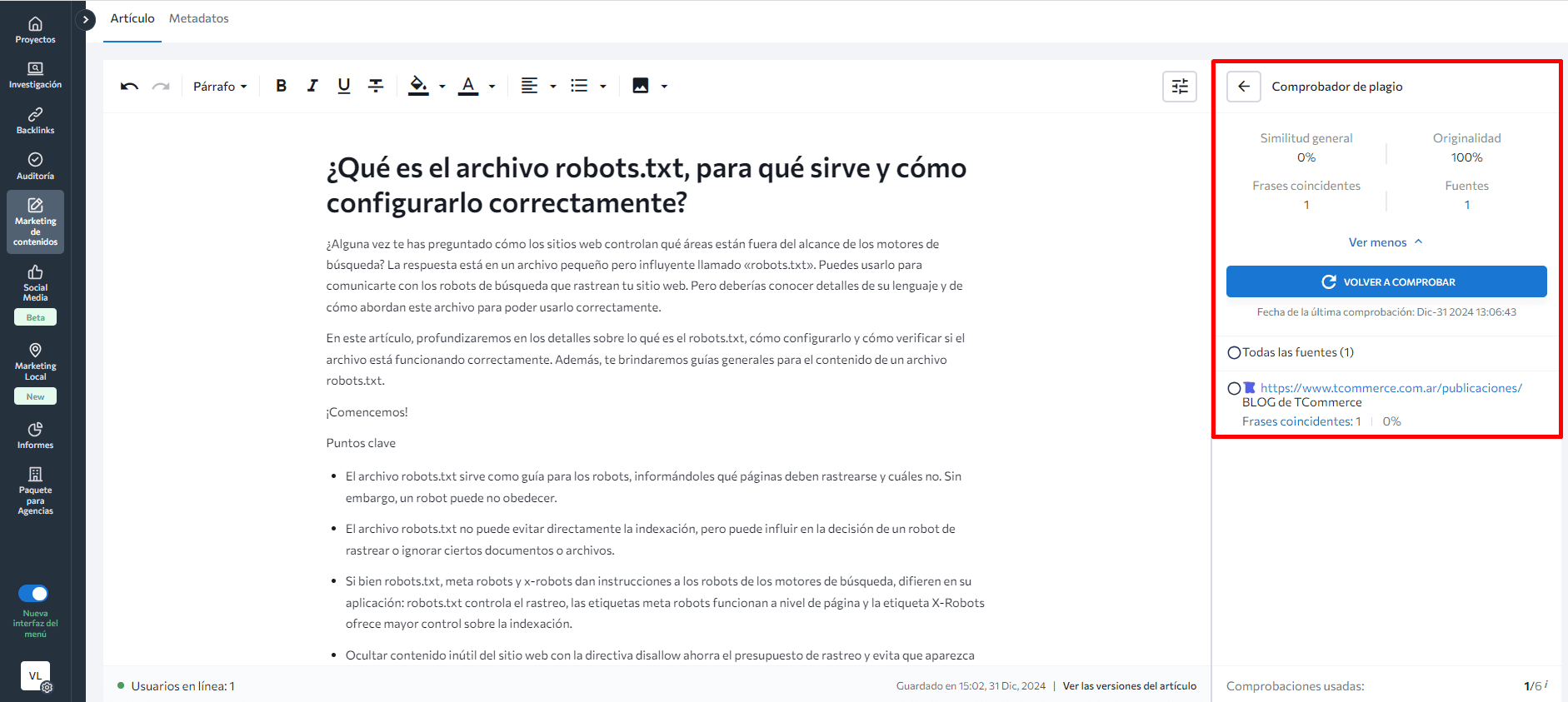
- Usa la herramienta Editor de Contenido impulsada por IA de SE Ranking para ahorrar tiempo. Cuenta con un Comprobador de plagio integrado que escanea tu contenido y lo analiza dentro de una gran base de datos para confirmar que es la versión original (no copiada). Muestra el porcentaje de palabras coincidentes, qué tan único es el texto, la cantidad de páginas con coincidencias y las frases coincidentes únicas entre todos los competidores.
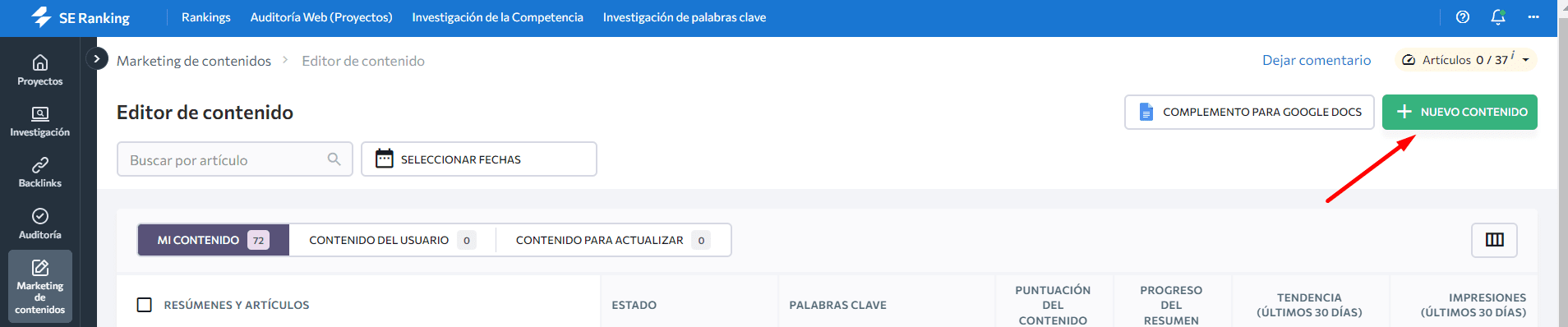
Para comenzar, busca el Editor de Contenido dentro de la plataforma SE Ranking, haz clic en el botón «Nuevo contenido» e indica los detalles de tu artículo.
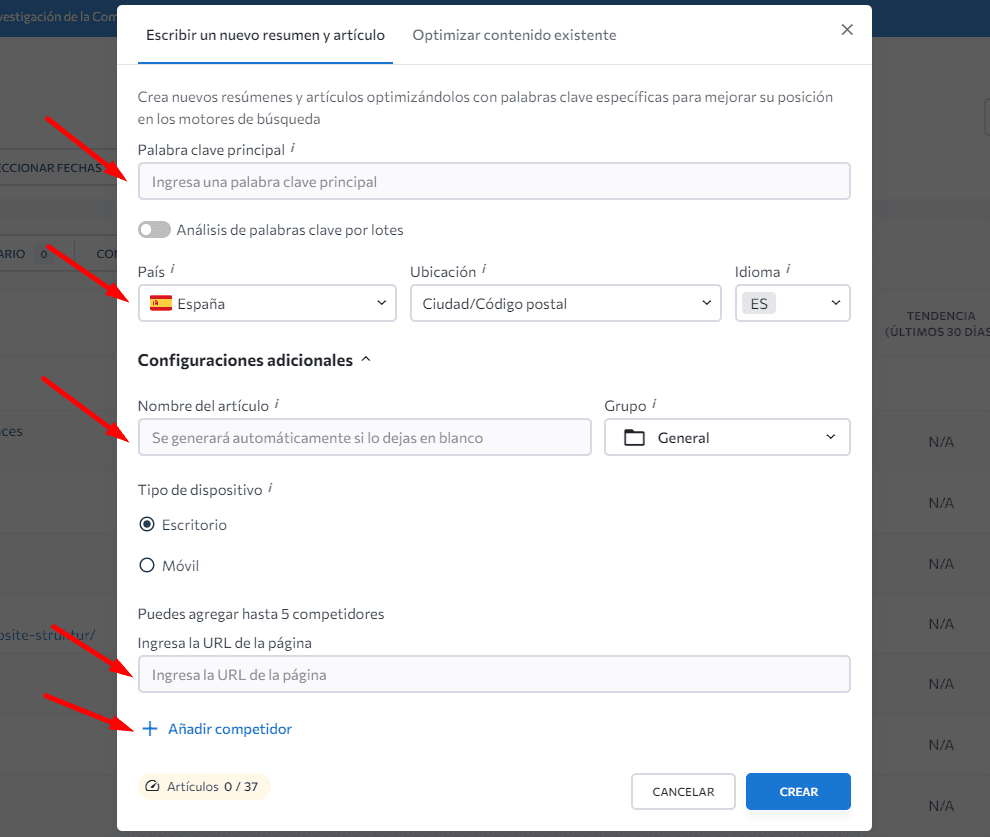
Añade tu artículo y abre la pestaña Calidad en la barra lateral derecha.
Desplázate hacia abajo hasta el Comprobador de Plagio y mira los detalles.
Las razones técnicas más comunes del contenido duplicado en SEO
Como lo mencionamos antes, el contenido duplicado involuntario en SEO es común, principalmente debido a la omisión de ciertos factores técnicos. A continuación, verás una lista de estos problemas y cómo solucionarlos.
Parámetros de URL
El contenido duplicado suele aparecer en sitios web cuando se puede acceder al mismo contenido o a uno muy similar a través de varias URL. A continuación, encontrarás dos formas técnicas comunes que lo provocan:
1. Parámetros de filtrado y clasificación: muchos sitios utilizan parámetros de URL para ayudar a los usuarios a filtrar u ordenar el contenido. Esto puede generar varias páginas con el mismo contenido o contenido similar, pero con ligeras variaciones en los parámetros. Por ejemplo, www.store.com/shirts?color=blue y www.store.com/shirts?color=red mostrarán camisetas azules y camisetas rojas, respectivamente. Si bien los usuarios pueden percibir las páginas de manera diferente según sus preferencias, los motores de búsqueda pueden interpretarlas como idénticas.
Los filtros pueden crear un montón de combinaciones, especialmente cuando tienes múltiples opciones. Esto se debe a que los parámetros se pueden reorganizar. Como resultado, las dos URL siguientes terminarían mostrando exactamente el mismo contenido:
- www.store.com/shirts?color=blue&sort=price-asc
- www.store.com/shirts?sort=price-asc&color=blue
Para evitar problemas de contenido duplicado en SEO y aumentar la autoridad de las páginas filtradas, usa URL canónicas para cada página principal y sin filtros. Sin embargo, ten en cuenta que esto no solucionará los problemas de presupuesto de rastreo. Como alternativa, puedes bloquear estos parámetros en tu archivo robots.txt para evitar que los motores de búsqueda rastreen versiones de filtros de tus páginas.
2. Parámetros de seguimiento: los sitios a menudo agregan parámetros como «utm_source» para rastrear la fuente del tráfico o «utm_campaign» para identificar una campaña o promoción específica, entre muchos otros parámetros. Si bien estas URL pueden parecer únicas, el contenido de la página seguirá siendo idéntico al que se encuentra en las URL sin estos parámetros. Por ejemplo, www.example.com/services y www.example.com/services?utm_source=twitter.
Todas las URL con parámetros de seguimiento deben ser canonizadas a la versión principal (sin estos parámetros).
Resultados de búsqueda
Muchos sitios web tienen cuadros de búsqueda que permiten a los usuarios filtrar y ordenar el contenido en el sitio web. Pero a veces, al realizar una búsqueda en el sitio, puedes encontrar contenido en la página de resultados de búsqueda que es muy similar o casi idéntico al contenido de otra página.
Por ejemplo, si buscas «contenido» en nuestro blog (https://seranking.com/blog/?s=content), el contenido que aparece es casi idéntico al contenido de nuestra página de categorías (https://seranking.com/blog/category-content/).
Esto se debe a que la función de búsqueda intenta proporcionar resultados relevantes en función de la consulta del usuario. Si el término de búsqueda coincide exactamente con una categoría, los resultados de búsqueda pueden incluir páginas de esa categoría. Esto puede causar problemas de contenido duplicado o casi duplicado.
Para corregir el contenido duplicado, usa etiquetas noindex o bloquea todas las URL que contengan parámetros de búsqueda en tu archivo robots.txt. Estas acciones le indican a los motores de búsqueda que omitan las páginas de resultados de búsqueda porque son solo duplicados. Los sitios web también deben evitar los enlaces a estas páginas. Y dado que los motores de búsqueda intentan rastrear los enlaces, eliminar los enlaces no deseados evita que rastreen las páginas duplicadas.
Versiones localizadas
Algunos sitios web tienen dominios específicos de cada país con el mismo contenido o contenido similar. Por ejemplo, es posible que tengas contenido localizado para países como EE. UU. y el Reino Unido. Dado que el contenido de cada configuración regional es similar con sólo ligeras variaciones, las versiones pueden verse como duplicadas.
Esta es una clara señal de que debes configurar etiquetas hreflang. Estas etiquetas ayudan a Google a comprender que las páginas son variaciones localizadas del mismo contenido.
Además, la probabilidad de encontrar duplicados sigue siendo alta incluso si usas subdominios o carpetas (en lugar de dominios) para tus versiones multirregionales. Esto hace que sea igualmente crucial usar hreflang para ambas opciones.
Con www vs. sin www
En ocasiones, los sitios web están disponibles en dos versiones diferentes: ejemplo.com y www.ejemplo.com. Aunque llevan al mismo sitio web, los motores de búsqueda las consideran URL distintas. Como resultado, las páginas de las versiones con www y sin www se indexan como duplicadas. Esta duplicación divide el valor del enlace y el tráfico en lugar de centrarse en una versión principal. También genera contenido repetitivo en los índices de búsqueda.
Para solucionar este problema, debes utilizar una redirección 301 de un nombre de host al otro. Esto significa redirigir la versión sin www a la versión con www o viceversa, según la versión que prefieras.
URL con barras diagonales
En ocasiones, las URL pueden incluir una barra diagonal final:
- example.com/page/
Y, en ocasiones, omitir la barra diagonal:
- example.com/page
Los motores de búsqueda las tratan como URL independientes, incluso si llevan a la misma página. Por eso, si se rastrean e indexan ambas versiones, el contenido termina siendo duplicado en dos URL distintas.
La mejor práctica es elegir un formato de URL (con o sin barras diagonales al final) y usarlo de manera uniforme en todas las URL del sitio web. Configura tu servidor web y los hipervínculos para usar el formato elegido. Luego, usa redirecciones 301 para consolidar todas las señales de relevancia en el estilo de URL seleccionado.
Paginación
Muchos sitios web dividen largas listas de contenido (es decir, artículos o productos) en páginas de paginación numeradas, como:
- /articles/?page=2
- /articles/page/2
Es importante asegurarse de que la paginación no sea accesible a través de diferentes tipos de URL, como /?page=2 y /page/2, sino solo a través de una de ellas (de lo contrario, se considerarán duplicadas). También es un error común identificar las páginas paginadas como duplicadas, ya que Google no las ve como tales.
Páginas de etiquetas y categorías
Los sitios web suelen mostrar productos tanto en las páginas de etiquetas como de categorías para organizar el contenido por tema.
Por ejemplo:
- example.com/category/shirts/
- example.com/tag/blue-shirts/
Si la página de categorías y la página de etiquetas muestran una lista similar de camisetas, entonces el mismo contenido se duplica en las páginas de etiquetas y categorías.
Las etiquetas suelen ofrecer un valor mínimo o nulo para tu sitio web, por lo que es mejor evitar su uso. En su lugar, puedes agregar filtros u opciones de clasificación, pero ten cuidado, ya que también pueden generar duplicados, como se mencionó anteriormente. Otra solución es usar etiquetas noindex en tus páginas, pero ten en cuenta que Google las rastreará de todos modos.
Entornos de prueba o ensayo indexables
Muchos sitios web utilizan entornos de prueba o ensayo independientes para probar nuevos cambios en el código antes de implementarlos en su producción. Los sitios de ensayo suelen tener contenido idéntico o muy similar al contenido que aparece en la versión activa del sitio web.
Pero si estas URL de prueba son de acceso público y se rastrean, los motores de búsqueda indexarán el contenido de ambos entornos. Esto puede provocar que el sitio en vivo compita contra sí mismo con la versión de prueba.
Por ejemplo:
- www.site.com
- test.site.com
Por lo tanto, si el sitio de prueba ya se ha indexado, elimínalo primero del índice. La opción más rápida es realizar una solicitud de eliminación de sitio a través de Search Console. Por otro lado, es posible utilizar la autenticación HTTP. Esto hará que Googlebot reciba un código 401, lo que le impedirá indexar esas páginas (Google no indexa URL 4XX).
Otras razones no técnicas que generan contenido duplicado
El contenido duplicado en SEO no solo se debe a problemas técnicos. También hay varios factores no técnicos que pueden generar contenido duplicado y otros problemas de SEO.
Por ejemplo, otros propietarios de sitios web pueden copiar deliberadamente contenido único de sitios que tienen una posición alta en los motores de búsqueda en un intento de beneficiarse de las señales de posicionamiento existentes. Como lo mencionamos antes, hacer scraping o volver a publicar contenido sin permiso crea versiones duplicadas no autorizadas que compiten con el contenido original.
Los sitios también pueden publicar blogs de invitados o contenido escrito por autónomos que aún no se ha examinado adecuadamente para determinar su puntuación de singularidad. Si el autor reutiliza o readapta contenido existente, el sitio puede publicar involuntariamente versiones duplicadas de artículos o información que ya están disponibles en línea en otros lugares.
Los resultados suelen ser bastante malos e inesperados en ambos casos.
Afortunadamente, la solución para ambos casos es simple. A continuación, te mostramos cómo abordarlo:
- Antes de publicar artículos invitados o contenido subcontratado, usa detectores de plagio para asegurarte de que sean completamente originales y no copiados.
- Controla tu contenido para detectar cualquier copia no autorizada por parte de otros sitios web.
- Establece medidas de protección con socios y afiliados para asegurarte de que tu contenido no se vuelva a publicar en exceso.
- Coloca la insignia de la DMCA en tu sitio web. Si alguien copia tu contenido mientras tienes la insignia, la DMCA de forma gratuita le exigirá que lo elimine. La DMCA también proporciona herramientas para ayudarte a encontrar tu contenido plagiado en otros sitios web. Eliminarán rápidamente cualquier texto, imagen o video copiado.
Cómo evitar contenido duplicado
Al crear un sitio web, asegúrate de tener los procedimientos adecuados para evitar que aparezca contenido duplicado en tu sitio (o en relación con él).
Por ejemplo, puedes evitar que URL innecesarias sean rastreadas con la ayuda del archivo robots.txt. Sin embargo, ten en cuenta que siempre debes comprobarlo (con nuestro Comprobador gratuito de Robots.txt). Esto evitará que robots.txt bloquee páginas importantes para los rastreadores de búsqueda.
Además, debes evitar que se indexen páginas innecesarias con la ayuda de <meta name=”robots” content=”noindex”> o la etiqueta X-Robots-Tag: noindex en la respuesta del servidor. Estas son las formas más fáciles y comunes de evitar problemas con la indexación de páginas duplicadas.
¡Importante! Si los motores de búsqueda ya han visto las páginas duplicadas y estás utilizando la etiqueta canónica (o la directiva noindex) para solucionar los problemas de contenido duplicado, espera hasta que los robots de búsqueda vuelvan a rastrear esas páginas. Solo entonces debes bloquearlas en el archivo robots.txt. De lo contrario, el rastreador no verá la etiqueta canónica ni la directiva noindex.
La eliminación de contenido duplicado no es negociable
Las consecuencias del contenido duplicado en SEO son muchas. Pueden causar graves daños a los sitios web, por lo que no debes subestimar su impacto. Si sabes de dónde viene el problema, puedes controlar fácilmente tus páginas web y evitar los duplicados. Si tienes páginas duplicadas, es fundamental tomar medidas a tiempo. Realizar auditorías web, establecer URL objetivos para palabras clave y realizar comprobaciones regulares de posición te ayudan a detectar el problema tan pronto como aparece.
¿Alguna vez has tenido problemas con páginas duplicadas? ¿Cómo has manejado la situación? ¡Comparte tu experiencia con nosotros en la sección de comentarios a continuación!

