17 häufige Google-Indexierungsprobleme: So erkennst und behebst du sie
Du hast alles gegeben, hochwertigen Content erstellt und stellst dann fest, dass deine Seiten in den Suchergebnissen nicht auftauchen. Der Inhalt bleibt unsichtbar, egal wie gut du optimierst. Der Grund dafür sind meist Indexierungsprobleme.
Dieser Leitfaden erklärt die häufigsten Ursachen, die Suchmaschinen davon abhalten, deine Seiten zu indexieren, und zeigt dir, wie du sie konkret behebst. Wer seine Google-Indexierungsprobleme beseitigt, legt den Grundstein dafür, dass die eigene Website in den SERPs erscheint und organisch wächst.
Die wichtigsten Punkte
Indexierungsprobleme verhindern, dass Suchmaschinen Seiten finden und in ihren Suchindex aufnehmen. Diese Seiten können daher weder in den SERPs erscheinen noch ranken.
Gleichzeitig gibt es Seiten, die nicht indexiert werden sollten: dazu zählen Duplikate und alternative Inhaltsseiten, geschützte Bereiche (Login-Seiten, Kontoseiten, Seiten mit vertraulichen Informationen) sowie Filter- und Sortierseiten.
Mögliche Ursachen für Indexierungsprobleme:
- Schlechte Inhaltsqualität (Thin oder doppelter Content)
- Technische Fehler (robots.txt-Blockierungen, fehlerhafte Canonical-Tags oder HTTP-Statuscodes wie 404-Fehler)
- Seitenstruktur und Ladegeschwindigkeit (schwache interne Verlinkung, langsame Ladezeiten oder blockierte Ressourcen wie JavaScript, CSS und Bilder)
- Penalties (manuelle Maßnahmen von Google können die Indexierung komplett verhindern)
- Weitere Faktoren (verdächtiger Code, überschrittenes Crawl-Budget, neue Website oder Indexierungsprobleme auf Googles Seite)
Die häufigsten Google-Indexierungsprobleme entstehen durch:
- Server-Fehler (5xx)
- Weiterleitungsfehler
- Versteckte Seiten (URL mit „noindex”-Tag; URL durch robots.txt blockiert)
- Fehlender Inhalt oder fehlende Zugriffsberechtigung (Soft 404; Blockiert wegen unberechtigter Anfrage (401); Nicht gefunden (404); Blockiert wegen verbotenem Zugriff (403); URL durch anderen 4xx-Fehler blockiert; Server-Fehler (5xx))
- Widersprüchliche Indexierungssignale (Duplikat ohne benutzerdefinierte Canonical; Duplikat, Google hat anderen Canonical gewählt; Seite mit Weiterleitung; Indexiert, obwohl durch robots.txt blockiert; Seite ohne Inhalt indexiert)
SEO-Profis erkennen Indexierungsprobleme, indem sie die Google Search Console (GSC) mit spezialisierten SEO-Tools wie SE Ranking kombinieren.
Website-Indexierungsprobleme verstehen
Fangen wir mit den Grundlagen an.
Indexierung beschreibt, wie Suchmaschinen die Inhalte deiner Website entdecken, analysieren und speichern. Googles Webcrawler folgen dabei externen Links auf bestehenden Seiten und werten die Sitemaps aus, die Website-Betreiber einreichen. So baut Google seinen Index aller Webseiten im Netz auf.
Hat deine Website Indexierungsprobleme, wird sie für Suchmaschinen unsichtbar. Potenzielle Besucher finden sie über die organische Suche schlicht nicht mehr.
Ob Google eine Seite indexiert, entscheidet ein Algorithmus, der Relevanz und Qualität jeder einzelnen Seite bewertet. Dabei spielen viele Faktoren eine Rolle: Zweck, Aktualität, Verständlichkeit und die Einhaltung der E-E-A-T-Kriterien – aber auch interne Verlinkung, Ladegeschwindigkeit, Canonical-Tags sowie das robots-Meta-Tag und der X-Robots-Tag.
Inhaltsqualität ist dabei der entscheidende Faktor. Schwacher Content wird am häufigsten ignoriert. Darunter fällt Content, der kaum Mehrwert bietet, der ausschließlich zur Manipulation von Rankings erzeugt wurde oder dem Originalität, Glaubwürdigkeit und Fachwissen fehlen. Wer dagegen hochwertige Inhalte erstellt, die den E-E-A-T-Kriterien entsprechen und Backlinks von relevanten Websites gewinnen, verbessert damit sowohl die Indexierbarkeit als auch das Ranking-Potenzial.
Technische SEO-Probleme verursachen ebenfalls häufig Google-Indexierungsprobleme. Robots.txt-Dateien, die wichtige Seiten blockieren, falsch konfigurierte Sitemaps oder das komplette Fehlen einer Sitemap können Suchmaschinen verwirren und ihre Fähigkeit beeinträchtigen, deine Website zu crawlen und zu indexieren. Unethische SEO-Praktiken wie Keyword-Stuffing können dazu führen, dass deine Website abgestraft und aus den SERPs entfernt wird.
In den folgenden Abschnitten gehen wir auf die häufigsten Ursachen von Indexierungsproblemen ausführlicher ein.
Warum manche Seiten nicht indexiert werden sollten
Nachdem klar ist, dass Google-Indexierungsprobleme die Sichtbarkeit und das Ranking einer Website schädigen, ist es ebenso wichtig zu verstehen: Nicht jede Seite muss von Suchmaschinen indexiert werden. Manche Seiten profitieren sogar davon, gezielt aus dem Index ausgeschlossen zu werden.
Folgende Seitentypen kannst du bedenkenlos aus der Indexierung herausnehmen:
1. Seiten hinter einem Login.
Dein Warenkorb oder dein Kundenkonto gehören nicht in den Suchindex. Diese Bereiche sind nur für eingeloggte Nutzer gedacht. Da Google dort den Statuscode „401 Unauthorized” erhält, ignoriert der Crawler ihren Inhalt ohnehin.
2. Duplikate und alternative Seiten.
Viele Websites erzeugen durch Filter- und Sortierfunktionen mehrfach ähnliche Inhalte. Suchmaschinen bevorzugen einzigartigen Content und indexieren in der Regel nur eine Version – die Canonical-URL. Das ist normales Verhalten, und die entsprechende Warnmeldung in der GSC bestätigt lediglich, dass Google die richtige Seite identifiziert hat.
3. Interne Suchergebnisseiten.
Website-interne Suchanfragen erzeugen dynamisch generierte Seiten, die für die Indexierung keinen Mehrwert bieten. Sie helfen Nutzern, Inhalte auf deiner Website zu finden, gehören aber nicht in die Suchergebnisse. Ein „noindex”-Tag hält Suchmaschinen davon ab, diese Seiten aufzunehmen.
4. Administrative Bereiche.
Das Backend deiner Website dient der Verwaltung, nicht der Öffentlichkeit. Admin-Bereiche sind in der Regel über die robots.txt-Datei blockiert, die Suchmaschinen anweist, diese Seiten nicht zu crawlen. Warnmeldungen dafür sind kein Grund zur Sorge.
Kurz gesagt: Wenn eine Seite aus einem triftigen Grund bewusst aus dem Index ausgeschlossen ist, sind GSC-Warnmeldungen ein positives Zeichen. Sie bestätigen, dass Suchmaschinen deine Anweisungen befolgen und sich auf die Teile deiner Website konzentrieren, die wirklich in den SERPs erscheinen sollten.
Mögliche Ursachen für Indexierungsprobleme
Viele Faktoren können verhindern, dass Suchmaschinen deine Seiten indexieren. Hier sind die häufigsten davon.
Doppelter Content
Gleicher oder sehr ähnlicher Inhalt auf mehreren Seiten führt zu Ranking- und Traffic-Verlusten. Google kann nicht einschätzen, welche Seite für eine bestimmte Suchanfrage am relevantesten ist. Geht Google davon aus, dass du doppelten Content absichtlich zur Manipulation der SERPs einsetzt, kann das dazu führen, dass die betroffenen Seiten komplett aus dem Index entfernt werden.
Schlechte Inhaltsqualität
Inhaltsqualität war schon immer ein wichtiger Rankingfaktor – mit dem Helpful-Content-System hat ihre Bedeutung jedoch noch einmal deutlich zugenommen. Content ohne Originalität oder Relevanz hat heute geringere Chancen, gut zu ranken oder überhaupt indexiert zu werden. Reduziere deshalb unoriginellen und irrelevanten Inhalt, der Nutzern keinen echten Mehrwert bietet oder primär darauf ausgelegt ist, Rankings zu verbessern. Das gilt insbesondere für KI-generierten Content oder maschinell übersetzte Inhalte ohne eigene Perspektive.
Durch robots.txt blockiert
Die Hauptfunktion der robots.txt-Datei ist es, Suchmaschinen mitzuteilen, welche Bereiche deiner Website sie crawlen dürfen und welche nicht. Wenn du das Crawlen untersagst, können Suchmaschinen-Bots den Inhalt nicht aufrufen und indexieren. Ob deine URLs durch die robots.txt blockiert werden, lässt sich mit dem robots.txt-Tester von SE Ranking prüfen.
Durch noindex-Tag oder Header blockiert
Über das robots-Meta-Tag und den X-Robots-Tag-HTTP-Header kannst du Suchmaschinen anweisen, eine bestimmte Seite nicht zu indexieren. Das ist sinnvoll für Seiten mit privaten Daten, Admin-Bereiche, doppelten Content und andere Seiten mit geringem Wert. Achte jedoch darauf: Wenn du diese Tags versehentlich auf wichtigen Seiten einsetzt, verschwinden sie vollständig aus den SERPs.
Fehlerhafte Canonical-Tags
Canonical-Tags geben Suchmaschinen an, welche Version einer Seite bei ähnlichem oder identischem Inhalt für die Indexierung bevorzugt werden soll. Gibst du keine Präferenz an, trifft Google die Entscheidung selbst, was gelegentlich dazu führt, dass die falsche Version indexiert wird.
Probleme mit HTTP-Statuscodes
HTTP-Statuscodes der Klassen 4xx und 5xx signalisieren Probleme beim Zugriff auf Inhalte. Stößt Google auf einen 4xx-Fehler, ignoriert es den Seiteninhalt. Das gilt auch für bereits indexierte URLs, die jetzt 4xx-Fehler zurückgeben. 5xx-Fehler (Server-Probleme) können Googles Crawling vorübergehend verlangsamen. Halten diese Fehler an, kann Google zuvor indexierte Seiten aus den Suchergebnissen entfernen.
Probleme mit der internen Verlinkung
Eine solide Website-Struktur mit guter interner Verlinkung verbessert nicht nur die Nutzererfahrung, sondern hilft Google auch beim Crawlen und Indexieren deiner Seiten. Probleme wie defekte Links oder verwaiste Seiten ohne eingehende interne Links erschweren es Suchmaschinen, deine Inhalte zu finden und richtig einzuordnen.
Langsame Ladezeiten
Da Google stets auf eine positive Nutzererfahrung abzielt, wirken sich langsame Ladezeiten zwangsläufig auf die Indexierung aus. Langsame Seiten frustrieren Nutzer, erhöhen die Absprungrate und signalisieren Google damit, dass der Inhalt keinen Mehrwert bietet. Dazu verschlechtern langsame Ladezeiten deine Core Web Vitals, was sich direkt auf das Ranking auswirkt. Wie schnell deine Website lädt, kannst du mit PageSpeed Insights oder dem Website-Speedtest von SE Ranking prüfen.
Blockierte JavaScript-, CSS- und Bilddateien
JavaScript, CSS und Bilder liefern wichtige Informationen zu Layout, interaktiven Funktionen und Inhalten selbst. Sind diese Ressourcen blockiert, erscheint die Seite für Suchmaschinen fehlerhaft. Google kann sie nicht vollständig rendern, was zu ungenauer Indexierung und schlechteren Rankings führt.
Überschrittenes Crawl-Budget
Jede Website hat ein festes Crawl-Budget: die Anzahl der Seiten, die Crawler innerhalb eines bestimmten Zeitraums aufrufen können. Wird dieses Budget überschritten, werden möglicherweise nicht alle Seiten gecrawlt und indexiert. Besonders betroffen sind große Websites mit 10.000 oder mehr Seiten.
Um innerhalb des Budgets zu bleiben, solltest du doppelten Content konsolidieren, entfernte Seiten mit einem 404- oder 410-Statuscode versehen, Sitemaps aktuell halten und lange Weiterleitungsketten vermeiden. Optimiere außerdem die Ladezeiten, prüfe das Crawling regelmäßig auf Erreichbarkeitsprobleme und setze in XML-Sitemaps Prioritäten für bestehende Seiten.
Neue Website
Auch wenn deine neue Website fertig aufgesetzt ist, braucht Google Zeit, um sie zu crawlen und zu indexieren. Da Google eine lange Warteschlange hat und Websites unterschiedlich schnell crawlt, kann es Stunden bis Wochen dauern, bis deine neue Website entdeckt wird.
Nutze die Wartezeit sinnvoll: Ergänze deine Website regelmäßig um relevante Inhalte, halte dich an SEO-Best-Practices und baue hochwertige Backlinks von vertrauenswürdigen Websites auf. Qualitätsbacklinks signalisieren Google die Relevanz deiner Website und können den Crawl- und Indexierungsprozess beschleunigen.
Verdächtiger Code
Um zu verstehen, worum es auf deiner Website geht, muss Google alle Inhalte sehen können – Texte, Links und Formatierungen. Erschwerst du Google-Bots durch aggressives Cloaking oder versteckte Inhalte den Zugriff auf deine Dateien, kann das die Indexierung beeinträchtigen. Noch gravierender ist es, wenn Hacker deinen Website-Code manipulieren – etwa durch eingeschleuste Skripte oder versteckte Links.
Priorisiere die Sicherheit deiner Website und achte darauf, dass dein Code nachvollziehbar und frei von verdächtigen Einträgen bleibt. Wer das vernachlässigt, riskiert Ranking-Einbußen oder die Entfernung aus dem Suchindex.
Manuelle Maßnahmen (Penalty)
Google-Penalties entfernen deine Website zwar nicht direkt aus den SERPs, aber schwerwiegende manuelle Maßnahmen – etwa wegen Spam oder irreführender Praktiken – können zur vorübergehenden oder dauerhaften Deindexierung führen. Google schützt damit Nutzer vor potenziell schädlichen Inhalten und verhindert, dass Website-Betreiber die Suchergebnisse manipulieren.
Indexierungsprobleme auf Googles Seite
Technische Probleme auf Googles Seite können die Indexierung verzögern und dazu führen, dass neuer Content später als erwartet in den SERPs erscheint. Beachte dabei: Die GSC bezieht ihre Daten aus Googles Index. Während einer solchen Phase kann die GSC unvollständige oder ungenaue Informationen anzeigen. Verfolge in solchen Situationen Googles offizielle Ankündigungen zum Problem.
Wie du Website-Indexierungsprobleme erkennst
Es gibt mehrere Methoden, um Indexierungsprobleme auf deiner Website aufzuspüren. Am effektivsten lassen sie sich mit der GSC oder einem zuverlässigen SEO-Tool finden.
Google Search Console
Die Google Search Console liefert aufschlussreiche Informationen über den Indexierungsstatus deiner Website. Der Bericht zur Seitenindexierung (Seitenindexierung) zeigt dir, welche URLs Google erfolgreich gecrawlt und indexiert hat, und listet Probleme auf, die andere Seiten von der Indexierung ausschließen könnten.

Konzentriere dich im Bericht auf URLs mit dem Status Nicht indexiert und scrolle nach unten zum Abschnitt Warum Seiten nicht indexiert werden. Das zeigt dir, warum Google bestimmte URLs nicht in den Index aufgenommen hat.

Die häufigsten Gründe:
1. Rückgang der indexierten Seiten ohne neue Fehlermeldungen
Wenn du feststellst, dass deine Website weniger indexierte Seiten hat, ohne dass neue Fehlermeldungen erscheinen, hast du möglicherweise versehentlich Googles Zugriff auf bestehende Inhalte blockiert. Suche nach einem gleichzeitigen Anstieg der Nicht indexierten URLs. Das ist ein klares Signal dafür, dass etwas den Zugriff verhindert.
2. Mehr nicht indexierte als indexierte Seiten
Wenn mehr Seiten nicht in den Suchergebnissen erscheinen als indexiert sind, liegt das meistens an einem versehentlichen Crawl-Block wichtiger Bereiche oder an doppeltem Content (zum Beispiel durch Filter- und Sortierfunktionen), den Suchmaschinen als minderwertig einstufen.
3. Plötzliche Fehler-Spitzen
Plötzliche Sprünge bei Fehlermeldungen entstehen oft in zwei Situationen: Entweder enthält ein kürzlich aktualisiertes Design einen Bug, der diese Fehler verursacht. Oder eine neu eingereichte Sitemap enthält Seiten, auf die Google keinen Zugriff hat, weil sie durch die robots.txt blockiert, mit einem „noindex”-Tag versehen oder hinter einem Login versteckt sind.
4. 404-Fehler
Googlebot kann deine Seite nicht erreichen. Das passiert typischerweise, wenn eine Seite von der Website entfernt wurde oder ein interner Link ins Leere zeigt. Googlebot konnte die Seite dann nicht verarbeiten und hat die Anfrage abgebrochen.
5. Server-Fehler
Für eine reibungslose Indexierung benötigen Crawler einen stabilen Serverzugang. Server-Fehler können dazu führen, dass deine Website als qualitativ minderwertig oder instabil eingestuft wird. Im schlimmsten Fall wird sie bei der Indexierung herabgestuft oder ganz aus dem Suchindex entfernt.
Das URL-Inspektionstool hilft bei der Diagnose, aber beachte: Diese Fehler können vorübergehend sein, sodass dein Test möglicherweise erfolgreich ist, obwohl Google zuvor Server-Probleme festgestellt hat.
6. Fehlende Seiten oder Websites
Folgende Gründe können dazu führen, dass eine Seite im Bericht zur Seitenindexierung nicht auftaucht:
- Google kennt die neue Seite noch nicht (die Entdeckung braucht Zeit)
- Google findet keinen Link zur Seite und hat keine Sitemap erhalten
- Google kann die Seite nicht aufrufen (Login erforderlich, Zugriff blockiert usw.)
- Die Seite trägt ein „noindex”-Tag.
Neben dem Bericht zur Seitenindexierung überprüfen SEOs regelmäßig den Bereich Sicherheit & manuelle Maßnahmen. Penalties – etwa wegen Spam oder Missbrauchs der Site-Reputation – können zu schlechteren Rankings oder zur kompletten Entfernung aus den Suchergebnissen führen.

Der Bericht Manuelle Maßnahmen listet Probleme auf, die menschliche Prüfer bei Google identifiziert haben – in der Regel Versuche, Googles Suchsystem zu manipulieren. Der Bericht Sicherheitsprobleme hingegen warnt vor potenziellen Hacks oder schädlichen Inhalten wie Phishing-Angriffen, Malware oder unerwünschter Software. Wer in einem dieser Berichte auftaucht, muss mit erheblichen Google-Indexierungsproblemen rechnen.
SE Ranking
Den Indexierungsstatus über die GSC zu verfolgen ist nützlich, aber mit dem richtigen SEO-Tool lassen sich Probleme deutlich schneller aufspüren und beheben.
Das Website-Audit-Tool von SE Ranking führt auf Abruf einen SEO-Audit durch und liefert innerhalb weniger Minuten einen detaillierten Indexierungsbericht, sodass du sofort mit der Fehlerbehebung beginnen kannst.
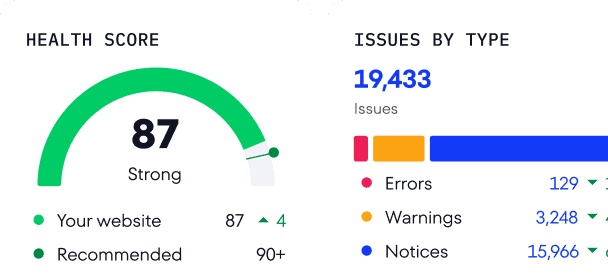
Sobald der Audit-Bericht bereit ist, navigiere zum Abschnitt Übersicht und scrolle zum Block Seiten-Indexierung.

Dort siehst du ein Dashboard mit einem Diagramm, das zeigt, wie viele deiner Seiten indexierbar sind und wie viele nicht. Das Dashboard liefert auch Hinweise darauf, warum Seiten möglicherweise nicht indexiert werden – etwa wegen robots.txt-Blockierungen, Meta-noindex-Tags oder nicht-kanonischen URLs. Per Klick auf das Diagramm gelangst du zum detaillierten Bericht über gecrawlte Seiten.

Dieser Bericht schlüsselt einzelne Seiten mit Parametern wie verweisenden Seiten, Anzahl der erkannten Probleme, Statuscodes, robots.txt-Direktiven und Canonical-URLs auf.

Mit den Filterfunktionen von SE Ranking kannst du Seiten, die durch noindex oder X-Robots-Tag blockiert sind, gezielt herausfiltern. Diese Seiten sollten ohnehin nicht indexiert werden und können von deiner Korrekturen-Liste gestrichen werden.

Der Bereich Crawling & Indexierung im Problembericht liefert ähnliche Indexierungsinformationen.

Du kannst ihn nutzen, um erkannte Probleme nach Fehlern zu sortieren und eine kategorisierte Liste von Schwachstellen zu erhalten, die die Indexierung beeinflussen: doppelter Content, HTTP-Statuscodes-Probleme, Weiterleitungsfehler, Ladegeschwindigkeit, Core Web Vitals und mehr.

Für eine schnelle Überprüfung des Indexierungsstatus über verschiedene Suchmaschinen hinweg eignet sich die Indexstatus-Prüfung von SE Ranking.

Sobald du Indexierungsprobleme behoben hast, solltest du die Such-Performance deiner Website weiter beobachten. So erkennst du, wie sich deine Verbesserungen auf Rankings, Sichtbarkeit und organischen Traffic auswirken. Der Rank Tracker von SE Ranking liefert dabei präzise, tägliche Ranking-Updates für Google (Desktop & Mobile), Bing, Yahoo und YouTube.
Indexierungsfehler in der Google Search Console – und wie du sie behebst
Jetzt weißt du, wie du Website-Indexierungsprobleme erkennst. Hier kommen die häufigsten Fehler und konkrete Lösungsansätze.
Serverfehler (5xx)
Serverfehler treten auf, wenn Googlebot eine Seite nicht aufrufen kann, zum Beispiel wegen Abstürzen, Timeouts oder Server-Ausfällen.
Lösung: Prüfe zunächst mit dem URL-Inspektionstool der GSC, ob der Fehler noch besteht. Ist er behoben, fordere eine Neuindexierung an. Bleibt der Fehler bestehen, hängt die Lösung vom spezifischen Fehler ab: Reduziere übermäßige Seitenladezeiten für dynamische Anfragen, überprüfe deinen Server auf Ausfälle, Überlastung oder Fehlkonfiguration und stelle sicher, dass du Google-Crawler nicht versehentlich blockierst. Danach fordere eine Neuindexierung an.
Weiterleitungsfehler
Folgende Weiterleitungsfehler kann Google auf deiner Website erkennen:
- Weiterleitungskette zu lang
- Weiterleitungsschleife
- Weiterleitungs-URL zu lang
- Defekte oder unvollständige URL in der Weiterleitungskette
Lösung: Nutze den kostenlosen Redirect-Checker von SE Ranking, um Weiterleitungsprobleme aufzudecken und zu beheben. Das Tool zeigt dir die Anzahl der Weiterleitungen pro URL, identifiziert Weiterleitungstypen, findet Weiterleitungsketten und zeigt an, wohin verkürzte verschlüsselte URLs führen.
URL wird von der robots.txt-Datei blockiert
Dieser Fehler bedeutet, dass Suchmaschinen auf eine bestimmte Seite nicht zugreifen können, weil die robots.txt-Datei den Zugriff einschränkt. Das kann gewollt sein oder auf einen Fehler in der Datei hinweisen.
Lösung: Überprüfe, ob wirklich nur die gewünschten Seiten blockiert sind. Findest du Seiten, die eigentlich indexiert werden sollen, passe die Regeln in deiner robots.txt-Datei entsprechend an: Entferne oder bearbeite spezifische Zeilen oder füge Allow-Direktiven hinzu.
Durch “noindex”-Tag ausgeschlossen
Google hat eine „noindex”-Direktive gefunden und die Seite daher nicht indexiert. Falls das deine Absicht war, läuft alles wie geplant. Wenn du möchtest, dass Google die Seite indexiert, entferne diese Direktive.
Lösung: Entferne „noindex”-Tags von wichtigen Seiten, die Crawler finden und indexieren sollen. Seiten, die du aus dem Suchindex ausschließen möchtest, lässt du wie sie sind.
Soft 404
Ein Soft-404-Fehler tritt auf, wenn eine URL zwar existiert (der Server sendet Statuscode 200), die Seite aber eine Meldung anzeigt, dass der Inhalt fehlt. Das kann verschiedene Ursachen haben: fehlende Server-Dateien, Verbindungsprobleme, interne Suchergebnisseiten, Probleme mit JavaScript-Dateien und mehr.
Lösung: Prüfe, ob die betroffenen URLs tatsächlich keinen Inhalt haben. Falls ja, gib einen korrekten 404-Statuscode zurück. Falls der Inhalt noch relevant ist, stelle sicher, dass die Seite das auch widerspiegelt und weder Nutzer noch Suchmaschinen in die Irre führt.
Wegen nicht autorisierter Anforderung (401) blockiert
Ein 401-Fehler bedeutet, dass Googlebot eine bestimmte Seite nicht aufrufen konnte, weil eine Autorisierung erforderlich ist.
Lösung: Wenn du möchtest, dass diese Seiten in den SERPs erscheinen, gewähre Googlebot Zugriff oder mache die Seiten öffentlich zugänglich.
Nicht gefunden (404)
Dieser Fehler bedeutet, dass Google Seiten auf deiner Website entdeckt hat, die einen 404-Fehler zurückgeben. Sie existieren nicht mehr. Diese URLs wurden möglicherweise von anderen Websites verlinkt oder existierten früher auf deiner Website.
Lösung: Wenn wichtige Seiten diesen Fehler zurückgeben, stelle entweder den ursprünglichen Inhalt wieder her oder leite die URL mit einem 301-Redirect auf eine passende Alternative weiter.
Wegen Zugriffsverbot (403) blockiert
Dieser Fehlercode bedeutet, dass der User-Agent Zugangsdaten angegeben hat, ihm aber die Berechtigung fehlt, auf die Ressource zuzugreifen. Da die Sicherheitseinstellungen deiner Website Googlebot versehentlich blockieren, kann der Inhalt nicht indexiert oder in den SERPs angezeigt werden.
Lösung: Wenn du möchtest, dass diese Seite indexiert wird, gewähre allen öffentlichen Nutzern oder zumindest Googlebot Zugriff und überprüfe dabei die Identität des Crawlers.
Wegen eines anderen 4xx-Problems blockiert
Dieser Fehler bedeutet, dass deine Seite von einem 4xx-HTTP-Antwortcode betroffen ist, der kein 401-, 403-, 404- oder Soft-404-Fehler ist.
Lösung: Nutze das URL-Inspektionstool, um den Fehler zu reproduzieren. Handelt es sich um wichtige Seiten, untersuche die Ursache – etwa Bugs im Code oder vorübergehende Serverprobleme – und behebe sie.
Gecrawlt – zurzeit nicht indexiert
Die URL wurde gecrawlt, aber noch nicht in Googles Suchindex aufgenommen. Google priorisiert, welche Seiten zuerst indexiert werden. Deine Seite wartet möglicherweise noch auf ihre Verarbeitung.
Lösung: Keine Neuindexierung erforderlich. Warte ab, bis Google die Seite indexiert, vorausgesetzt, keine Blockierungsanweisungen verhindern das.
Gefunden – zurzeit nicht indexiert
Google hat deine Seite entdeckt, aber noch nicht gecrawlt oder indexiert. Das passiert häufig, wenn Google den Crawl-Zeitplan anpasst, um die Website nicht zu überlasten.
Lösung: Genau wie im vorherigen Fall: Gib Google die nötige Zeit und warte geduldig, bis deine Seite gecrawlt und indexiert wird.
Alternative Seite mit richtigem kanonischen Tag
Diese URL wird nicht indexiert, weil sie ein Duplikat einer kanonischen Seite ist.
Lösung: Die Seite verweist korrekt auf die Canonical-URL – es gibt nichts zu tun.
Duplikat – vom Nutzer nicht als kanonisch festgelegt
Diese URL ist ein Duplikat einer anderen Seite auf deiner Website. Da du keine Canonical-URL festgelegt hast, hat Google selbst eine Version ausgewählt.
Lösung: Wenn du Googles Wahl nicht akzeptierst, gib Suchmaschinen an, welche URL du bevorzugst. Google dokumentiert gängige Methoden zur Festlegung einer Canonical-URL ausführlich in seiner Dokumentation. Bist du der Ansicht, dass diese Seite eigenständig in den Suchergebnissen erscheinen sollte und kein Duplikat der von Google gewählten Canonical ist, überarbeite den Inhalt beider Seiten so, dass er einzigartig ist.
Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt
Diese Meldung bedeutet: Du hast diese Seite als bevorzugte Version markiert, Google hat aber eine andere gewählt und die nicht-bevorzugte Version indexiert.
Lösung: Nutze das URL-Inspektionstool, um zu prüfen, welche URL Google als Hauptversion dieser Seite betrachtet.
Seite mit Weiterleitung
Diese nicht-kanonische URL leitet Besucher auf eine andere Seite weiter, die möglicherweise in den SERPs gelistet ist oder nicht. Google indexiert die URL mit dieser Meldung nicht.
Lösung: Analysiere mit dem URL-Inspektionstool den Indexierungsstatus der zugehörigen Canonical-URL. Beachte dabei, dass nicht alle Weiterleitungen von Suchmaschinen gleich behandelt werden. Ein 301-Redirect, wo eigentlich ein 302 nötig wäre (oder umgekehrt), kann die Indexierung und die Weitergabe von Link-Equity beeinflussen.
Indexiert, obwohl durch robots.txt-Datei blockiert
Obwohl du diese URL über die robots.txt-Datei blockiert hast, erscheint sie in den SERPs. Suchmaschinen folgen zwar in der Regel den robots.txt-Anweisungen, können deine Seite aber trotzdem finden, wenn andere Websites darauf verlinken. Google crawlt die blockierte Seite zwar nicht direkt, nutzt aber Informationen von verlinkenden Seiten, um ihren Inhalt einzuschätzen und sie in die SERPs aufzunehmen.
Lösung: Um zu verhindern, dass diese Seite in den SERPs erscheint, füge stattdessen ein „noindex”-Tag hinzu. Wenn du möchtest, dass Google die Seite indexiert, passe deine robots.txt-Datei entsprechend an.
Seite ohne Inhalt indexiert
Dieser Fehler bedeutet, dass die URL in Googles Suchindex steht, Google dort aber keinen Inhalt gefunden hat. Mögliche Ursachen sind Cloaking, zu wenig Inhalt oder render-blockierende Elemente, die nicht korrekt laden.
Lösung: Sieh dir die Seite manuell an und prüfe sie mit dem URL-Inspektionstool in der GSC. Behebe fehlenden oder render-blockierenden Inhalt und fordere danach eine Neuindexierung der URL an.
So bittest du Google, behobene Indexierungsprobleme zu validieren
Wenn du ein Problem behoben hast und Google informieren möchtest, dass deine Seite bereit für die Neuindexierung ist, gehst du so vor:
- Öffne den Bericht zur Seitenindexierung und wähle die Detailseite des jeweiligen Problems aus.

- Klicke auf Fehlerbehebung überprüfen, um Google mitzuteilen, dass du die aufgeführten Probleme behoben hast.

Die Überprüfung dauert in der Regel rund zwei Wochen, manchmal auch länger. Google benachrichtigt dich, sobald der Prozess abgeschlossen ist. War die Validierung erfolgreich, können deine Seiten jetzt indexiert werden und in den SERPs erscheinen.
Schlägt die Validierung fehl, siehst du über den Button Details anzeigen, welche URLs betroffen sind. Behebe die Indexierungsprobleme erneut, stelle sicher, dass alle Änderungen auf jede der aufgeführten URLs angewendet wurden, und starte die Validierung dann neu.
Fazit
Indexierungsfehler zu sehen, besonders für URLs, die zentral für deine SEO-Strategie sind, ist frustrierend. Die gute Nachricht ist, dass die meisten Indexierungsprobleme, die die GSC meldet, sich mit überschaubarem Aufwand lösen lassen.
Der erste Schritt ist immer derselbe: Verstehe, welche Seiten indexiert werden sollen und welche nicht. Erst dann setzt du robots.txt und „noindex”-Tags gezielt ein, um Suchmaschinen zu deinen bevorzugten Seiten zu führen. Stößt du auf Indexierungsprobleme, schau dir die jeweilige Fehlerbeschreibung genau an und folge den Lösungstipps in diesem Leitfaden – die meisten Fälle lassen sich damit zügig klären.

