Fichier robots.txt : comprendre et bien l’utiliser
-
Le fichier robots.txt sert de guide aux robots, leur indiquant quelles pages doivent ou ne doivent pas être explorées. Cependant, un robot peut décider de ne pas s’y conformer.
-
Le fichier robots.txt ne peut pas empêcher directement l’indexation, mais il peut influencer la décision d’un robot d’explorer ou d’ignorer certains documents ou fichiers.
-
Si le fichier robots.txt, les balises meta robots et X-Robots-Tag donnent des instructions aux robots des moteurs de recherche, leur application diffère : le fichier robots.txt contrôle l’exploration, les balises meta robots agissent au niveau de la page, et la balise X-Robots-Tag offre un contrôle plus fin sur l’indexation.
-
Masquer le contenu d’un site web à l’aide de la directive « disallow » permet d’économiser le budget d’exploration et d’empêcher l’apparition de contenu indésirable dans les résultats de recherche.
-
Le respect des règles de syntaxe garantit que les robots de recherche peuvent lire et comprendre correctement votre fichier robots.txt.
-
La création d’un fichier robots.txt est possible à l’aide d’éditeurs de texte prenant en charge l’encodage UTF-8, ou via les outils intégrés aux plateformes CMS populaires telles que WordPress, Magento et Shopify.
-
Vérifiez votre fichier robots.txt à l’aide d’outils tels que Google Search Console ou de plateformes de référencement comme SE Ranking. Cela vous aide à identifier les problèmes potentiels et garantit que le fichier fonctionne comme prévu.
-
Les problèmes courants incluent les incompatibilités de format, un emplacement incorrect du fichier, une mauvaise utilisation des directives et des instructions contradictoires.
-
Gardez à l’esprit que les valeurs de chemin d’accès dans le fichier robots.txt sont sensibles à la casse. Veillez également à ce que chaque directive soit placée sur une nouvelle ligne, utilisez des caractères génériques pour plus de flexibilité, créez des fichiers distincts pour les différents domaines et testez votre site web après avoir mis à jour le fichier robots.txt afin de vous assurer qu’aucune URL importante n’est bloquée par inadvertance.
Qu’est-ce qu’un fichier robots.txt ?
Un fichier robots.txt est un document texte situé dans le répertoire racine d’un site web. Les informations qu’il contient sont destinées spécifiquement aux robots d’indexation des moteurs de recherche. Il leur indique quelles URL, y compris les pages, les fichiers, les dossiers, etc., doivent être explorées et lesquelles ne le doivent pas. Bien que la présence de ce fichier ne soit pas obligatoire pour le fonctionnement d’un site web, il doit être correctement configuré pour un référencement naturel (SEO) efficace.
La décision d’utiliser le fichier robots.txt a été prise en 1994 dans le cadre de la norme Robots Exclusion Standard. Selon Google Search Central, l’objectif principal de ce fichier n’est pas de masquer des pages web des résultats de recherche, mais plutôt de limiter le nombre de requêtes effectuées par les robots sur les sites et de réduire la charge du serveur.
D’une manière générale, le contenu du fichier robots.txt doit être considéré comme une recommandation à l’intention des robots d’indexation, qui définit les règles de l’exploration du site web. Pour accéder au contenu du fichier robots.txt d’un site, il suffit de saisir « /robots.txt » après le nom de domaine dans le navigateur.
Comment fonctionne le fichier robots.txt ?
Tout d’abord, il est important de noter que les moteurs de recherche doivent explorer et indexer les résultats de recherche spécifiques affichés sur les SERP. Pour accomplir cette tâche, les robots d’indexation parcourent systématiquement le Web, collectant des données sur chaque page Web qu’ils rencontrent. Le terme « spidering » est parfois utilisé pour décrire cette activité d’exploration.
Lorsque les robots d’indexation atteignent un site web, ils vérifient le fichier robots.txt, qui contient des instructions sur la manière d’explorer et d’indexer les pages du site. S’il n’y a pas de fichier robots.txt, ou s’il ne contient aucune directive interdisant l’activité des agents utilisateurs, les robots de recherche continueront à explorer le site jusqu’à ce qu’ils atteignent le budget d’exploration ou d’autres restrictions.
Qu’est-ce que llms.txt, et en avez-vous besoin pour les robots IA ?
Llms.txt est une norme proposée qui vise à aider les robots d’indexation IA à mieux comprendre votre site. Contrairement au fichier robots.txt qui demande aux robots d’indexation d’ignorer des pages spécifiques, llms.txt fournit des liens vers des pages importantes et les décrit en langage humain pour les robots d’indexation IA, à la manière d’un plan du site amélioré.

Bien qu’il existe depuis un certain temps et que certains moteurs IA aient manifesté leur intérêt pour cette norme, rien n’indique qu’elle soit appliquée par qui que ce soit. Selon une étude de SE Ranking sur le sujet, llms.txt n’influence pas la visibilité IA ni le nombre de citations dans la recherche IA.
La plupart des fonctions que llms.txt tente de normaliser sont déjà couvertes par le plan du site et le balisage Schema, ou sont sans importance car l’IA est capable de comprendre le contexte par elle-même.
Pourquoi avez-vous besoin d’un fichier robots.txt ?
Il y a deux raisons principales pour lesquelles le fichier robots.txt est une pratique SEO importante : la gestion de l’exploration et l’optimisation du budget d’exploration.
Gérer l’exploration (y compris les robots IA !)
La fonction principale du fichier robots.txt est d’empêcher l’exploration des pages et des fichiers de ressources que vous souhaitez garder privés. Cela peut inclure les panneaux d’administration, le contenu dupliqué, les pages en cours de développement et les pages de paramètres de requête telles que les filtres ou les résultats de recherche interne.
Remarque : l’utilisation de la directive « robots.txt disallow » ne garantit pas qu’une page web particulière ne sera pas explorée ou qu’elle sera exclue des SERP. Google se réserve le droit de prendre en compte divers facteurs externes, tels que les liens entrants, pour déterminer la pertinence d’une page web et son inclusion dans les résultats de recherche. Pour empêcher explicitement l’indexation d’une page, il est recommandé d’utiliser la balise méta robots « noindex » ou l’en-tête HTTP X-Robots-Tag. La protection par mot de passe peut également être utilisée pour empêcher l’indexation.
Les directives robots.txt sont également respectées par les moteurs d’IA les plus populaires, tels que Gemini, Perplexity et ChatGPT. Si vous souhaitez empêcher des outils d’IA spécifiques d’accéder à votre site, ajoutez la directive correspondante pour leur agent utilisateur.
Il existe des centaines de noms d’agents utilisateurs IA, et la plupart des outils font la distinction entre les bots utilisés pour l’entraînement, l’indexation et les recherches lancées par les utilisateurs. Les bots d’entraînement recherchent du contenu sur lequel le modèle IA peut s’entraîner, les bots de recherche/indexation créent des index internes pour la recherche, et les bots lancés par les utilisateurs récupèrent du contenu récent à la demande de l’utilisateur s’il ne figure pas dans l’index.
Voici quelques exemples.
Bots de recherche/d’indexation (création d’index pour la recherche alimentée par l’IA) :
- OAI-Searchbot
- Claude-SearchBot
- PerplexityBot
Bots déclenchés par l’utilisateur (récupèrent du contenu lorsque les utilisateurs posent des questions) :
- ChatGPT-User
- Claude-Utilisateur
- Perplexity-User
- Applebot
Remarque : certains des bots lancés par l’utilisateur peuvent également être utilisés pour l’entraînement.
Bots d’entraînement (utilisés pour collecter des données afin d’entraîner des modèles d’IA) :
- Meta-ExternalAgent
- Google-Extended
- GPTBot
- ClaudeBot
- Applebot-Extended
- Meta-ExternalAgent
Toutes les plateformes d’IA recommandent d’autoriser les robots de recherche/d’indexation à accéder au site afin de garantir que la visibilité de l’IA ne soit pas affectée. Cependant, le comportement des autres robots d’indexation peut varier. Il existe également des différences entre les plateformes.
Par exemple, bloquer le robot d’indexation OAI-Searchbot d’OpenAI empêchera votre site web d’apparaître dans les résultats de recherche, mais il pourra toujours être référencé dans les liens de navigation. Le robot d’indexation de Perplexity évitera également de parcourir les sites web qui l’interdisent, mais indexera le domaine et fournira un bref résumé de celui-ci.
La plupart des robots d’apprentissage respecteront strictement les directives du fichier robots.txt, mais certains robots lancés par les utilisateurs, comme ChatGPT-User de ChatGPT, peuvent les ignorer.
Optimiser le budget d’exploration
Le budget d’exploration désigne le nombre de pages web d’un site qu’un robot de recherche consacre à l’exploration. Pour utiliser le budget d’exploration plus efficacement, les robots de recherche doivent être dirigés uniquement vers le contenu le plus important des sites web et empêchés d’accéder aux informations inutiles.
L’optimisation du budget d’exploration aide les moteurs de recherche à allouer efficacement leurs ressources limitées, ce qui se traduit par une indexation plus rapide des nouveaux contenus et une meilleure visibilité dans les résultats de recherche. Il est toutefois important de garder à l’esprit que si votre site comporte plus de pages que ne le permet votre budget d’exploration alloué, certaines pages risquent de ne pas être explorées et, par conséquent, de ne pas être indexées. Les pages non indexées ne peuvent apparaître nulle part dans les SERP.
Dans la plupart des cas, vous devriez envisager d’optimiser l’utilisation de votre budget d’exploration si vous gérez un site web de grande taille (des milliers de pages), un site web de taille moyenne dont le contenu évolue rapidement, ou si vous avez un pourcentage important de pages non indexées. L’optimisation garantira que les moteurs de recherche couvrent intégralement toutes vos pages importantes.
Imaginons un scénario dans lequel votre site web comporte beaucoup de contenu insignifiant par rapport à celui de ses pages principales. Dans ce genre de cas, vous pouvez optimiser votre budget d’exploration en excluant les ressources indésirables de la liste des pages à explorer par le robot d’indexation.
Par exemple, vous pouvez utiliser la directive « Disallow » suivie d’une extension de fichier spécifique, telle que « Disallow:/*.pdf », pour empêcher les moteurs de recherche d’explorer les ressources PDF de votre site.
Un autre avantage courant de l’utilisation du fichier robots.txt est sa capacité à résoudre les problèmes d’exploration de contenu sur votre serveur, le cas échéant. Par exemple, si vous disposez de scripts de calendrier infinis susceptibles de poser des problèmes lorsqu’ils sont fréquemment consultés par les robots, vous pouvez interdire l’exploration de ces scripts via le fichier robots.txt.
Exemple de contenu du fichier robots.txt
Disposer d’un modèle contenant des directives à jour peut vous aider à créer un fichier robots.txt correctement formaté, en spécifiant les robots requis et en restreignant l’accès aux fichiers concernés.
User-agent: [nom du robot]
Disallow: /[chemin d’accès au fichier ou au dossier]/
Disallow: /[chemin d’accès au fichier ou au dossier]/
Disallow: /[chemin d’accès au fichier ou au dossier]/
Sitemap: [URL du plan du site]
Voyons maintenant quelques exemples de ce à quoi peut ressembler un fichier robots.txt.
1. Autoriser tous les robots d’indexation à accéder à l’ensemble du contenu.
Voici un exemple simple de code de fichier robots.txt qui autorise tous les robots d’indexation à accéder à tous les sites web :
User-agent : *
Allow: /
# Sitemaps
Sitemap: https://www.example.com/sitemap.xml
Dans cet exemple, la directive « User-agent » utilise un astérisque (*) pour appliquer les instructions à tous les robots d’indexation. Crawl-delay accorde aux robots un accès illimité, mais leur demande d’attendre 10 secondes entre chaque requête. La déclaration du plan du site ne restreint aucun accès, mais dirige les robots vers le plan du site. Les lignes commençant par un signe dièse sont des commentaires ignorés par les robots.
2. Bloquer un robot d’indexation spécifique sur une page Web spécifique.
L’exemple suivant spécifie les autorisations d’accès pour l’agent utilisateur « Bingbot », qui est le robot d’indexation utilisé par le moteur de recherche de Microsoft, Bing. Il comprend une liste de répertoires du site Web qui sont fermés à l’indexation, ainsi que quelques répertoires et pages auxquels l’accès est autorisé sur le site Web.

3. Bloquer tous les robots d’indexation pour l’ensemble du contenu.
User-agent: *
Disallow: /
Dans cet exemple, la directive « User-agent » s’applique toujours à tous les robots d’indexation. Cependant, la directive « Disallow » utilise une barre oblique (/) comme valeur, indiquant que l’accès à tout le contenu du site web doit être bloqué pour tous les robots d’indexation. Cela indique effectivement à tous les robots de ne pas explorer aucune page du site.
Veuillez noter que le blocage de l’accès de tous les robots d’indexation au contenu d’un site web à l’aide du fichier robots.txt est une mesure extrême et n’est pas recommandée dans la plupart des cas. Cela ne peut s’avérer utile que lorsque votre nouveau site est en cours de développement et n’est pas prêt à être ouvert aux moteurs de recherche. Dans d’autres situations, les sites web utilisent généralement le fichier robots.txt pour contrôler l’accès à des parties spécifiques de leur site, par exemple en bloquant certains répertoires ou fichiers, plutôt qu’en bloquant l’ensemble du contenu.
4. Donner des instructions aux robots IA.
Le fichier robots.txt peut également être utilisé pour donner des instructions aux robots d’indexation IA. Voici un exemple d’ensemble de directives permettant l’indexation de l’ensemble du site web tout en bloquant des sous-répertoires spécifiques.
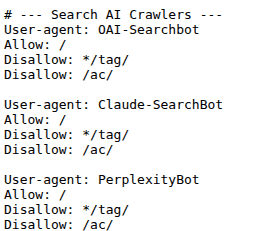
Il n’est pas recommandé de bloquer l’ensemble du site web, car cela peut nuire à votre visibilité IA. Perplexity recommande d’autoriser son robot d’exploration, PerplexityBot, et le robot d’exploration lancé par l’utilisateur, Perplexity-User, afin de garantir la visibilité IA, car aucun des deux n’est utilisé pour l’entraînement de l’IA. OpenAI recommande d’autoriser OAI-SearchBot pour la visibilité IA, seul GPTBot étant utilisé pour l’entraînement du modèle.
Gardez à l’esprit qu’il n’existe pas de nom d’agent utilisateur unique pour tous les robots d’indexation IA. Si vous souhaitez leur donner des directives, vous devrez référencer chaque nom d’agent utilisateur séparément.
Comment trouver le fichier robots.txt
Pour localiser le fichier robots.txt sur un site web, vous pouvez utiliser plusieurs méthodes :
Pour trouver le fichier robots.txt, ajoutez « /robots.txt » au nom de domaine du site web que vous souhaitez examiner. Par exemple, si le domaine du site web est « example.com », vous devrez saisir « example.com/robots.txt » dans la barre d’adresse de votre navigateur web. Cela vous mènera directement au fichier robots.txt s’il existe sur le site web.
Une autre méthode, moins courante mais tout de même fréquente chez les utilisateurs de CMS, consiste à rechercher et à modifier les fichiers robots.txt directement au sein du système. Passons en revue quelques-uns des plus courants.
Un fichier robots.txt dans WordPress
Pour trouver et modifier un fichier robots.txt dans WordPress, vous pouvez en créer un manuellement ou utiliser un plugin.
Pour en créer un manuellement :
- Créez un fichier texte nommé « robots.txt »
- Téléchargez-le dans votre répertoire racine via un client FTP
À l’aide du plugin Yoast SEO :
- Allez dans Yoast SEO > Outils
- Cliquez sur Éditeur de fichiers (assurez-vous que l’édition de fichiers est activée)
- Cliquez sur le bouton « Créer un fichier robots.txt »
- Affichez ou modifiez le fichier robots.txt à cet endroit
Utilisation du plugin All in One SEO :
- Accédez à All in One SEO > Outils
- Cliquez sur Éditeur de robots.txt
- Cliquez sur le bouton pour activer « Custom Robots.txt ».
- Affichez ou modifiez le fichier robots.txt à cet endroit
Un fichier robots.txt dans Magento
Magento génère automatiquement un fichier robots.txt par défaut.
Pour le modifier :
- Connectez-vous au panneau d’administration de Magento
- Allez dans Contenu > Design > Configuration
- Cliquez sur Modifier pour le site Web principal
- Développez la section Robots des moteurs de recherche
- Modifiez le contenu du champ Modifier les instructions personnalisées du fichier robots.txt
- Enregistrez la configuration
Un fichier robots.txt dans Shopify
Shopify génère automatiquement un fichier robots.txt par défaut.
Pour le modifier :
- Connectez-vous à votre panneau d’administration Shopify
- Cliquez sur Paramètres > Applications et canaux de vente
- Accédez à Boutique en ligne > Thèmes
- Cliquez sur le bouton « … » à côté de votre thème actuel et sélectionnez « Modifier le code »
- Cliquez sur Ajouter un nouveau modèle > robots
- Cliquez sur Créer un modèle
- Modifiez le contenu selon vos besoins
- Enregistrez vos modifications
1. Analysez votre site web à l’aide d’outils automatisés tels que l’audit de site de SE Ranking.
Une autre façon de vérifier la présence d’un fichier robots.txt consiste à utiliser un outil d’audit de site web. Cet outil, par exemple, analyse votre site et vous indique si vous disposez d’un fichier robots.txt et quelles pages il bloque. Passez en revue les pages bloquées pour déterminer si elles doivent l’être ou si l’accès a été restreint par inadvertance.
Pour lancer l’audit, il suffit de démarrer le processus et d’attendre qu’il se termine (vous recevrez une notification dans votre boîte de réception). Ensuite, accédez au rapport d’incidents, sélectionnez le blocage d’exploration et vérifiez si le problème « Fichier robots.txt introuvable » est présent.

2. Générez un fichier robots.txt pour votre CMS
Si votre site web ne dispose pas d’un fichier robots.txt, vous pouvez en créer un à partir de zéro ou en générer un à l’aide du générateur de fichiers robots.txt gratuit de SE Ranking. Vous pouvez ajouter des directives et des chemins d’accès manuellement ou générer le fichier automatiquement. Indiquez votre CMS, et l’outil ajoutera tous les sous-répertoires qui doivent généralement être bloqués lors de l’exploration.
Voici un exemple pour WordPress.

S’il y a d’autres répertoires que vous souhaitez empêcher d’être explorés, ajoutez-les par la suite.
Comment les moteurs de recherche trouvent votre fichier robots.txt
Les moteurs de recherche disposent de mécanismes spécifiques pour découvrir et accéder au fichier robots.txt de votre site web. Voici comment ils le trouvent généralement :
1. Exploration d’un site web : les robots d’exploration des moteurs de recherche parcourent en permanence le web, visitant des sites web et suivant des liens pour découvrir des pages web.
2. Demande du fichier robots.txt : lorsqu’un robot d’indexation accède à un site web, il recherche la présence d’un fichier robots.txt en ajoutant « /robots.txt » au domaine du site.
Remarque : une fois votre fichier robots.txt téléchargé et testé avec succès, les robots d’indexation de Google le détectent automatiquement et commencent à suivre ses instructions. Aucune autre action n’est nécessaire. Toutefois, si vous avez apporté des modifications à votre fichier robots.txt et que vous souhaitez en informer Google rapidement, vous devrez apprendre à soumettre un fichier robots.txt mis à jour.
3. Récupération du fichier robots.txt : si un fichier robots.txt existe à l’emplacement demandé, le robot d’indexation le télécharge et l’analyse pour déterminer les directives d’indexation.
4. Suivi des instructions : après avoir obtenu le fichier robots.txt, le robot d’indexation du moteur de recherche suit les instructions qui y sont décrites.
Robots.txt, balise meta robots et X-Robots-Tag
Bien que le fichier robots.txt, la balise meta robots et la balise X-Robots-Tag aient des objectifs similaires en termes d’instructions données aux robots d’indexation des moteurs de recherche, ils diffèrent par leur application et leur domaine de contrôle.
Lorsqu’il s’agit de masquer le contenu d’un site dans les résultats de recherche, se fier uniquement au fichier robots.txt peut s’avérer insuffisant. Comme mentionné plus haut, le fichier robots.txt constitue avant tout une recommandation à l’intention des robots d’indexation. Il leur indique les sections d’un site web auxquelles ils sont autorisés à accéder. Cependant, il ne garantit pas que le contenu ne sera pas indexé par les moteurs de recherche, car des liens vers celui-ci peuvent être découverts sur d’autres sites web. Pour empêcher l’indexation, les webmasters doivent recourir à des méthodes supplémentaires.
Balise méta robots
Une technique efficace consiste à utiliser la balise meta robots, qui est placée dans la section <head> du code HTML d’une page. En incluant une balise meta avec la directive « noindex », les webmasters signalent explicitement aux robots des moteurs de recherche que le contenu de la page ne doit pas être indexé. Cette méthode offre un contrôle plus précis sur les pages individuelles et leur statut d’indexation par rapport aux directives générales du fichier robots.txt.
Voici un exemple de snippet de code permettant d’empêcher l’indexation par les moteurs de recherche au niveau de la page :
<meta name=“robots” content=“noindex”>
Tout comme le fichier robots.txt, cette balise meta permet de restreindre l’accès à des robots spécifiques. Par exemple, pour restreindre l’accès à un robot spécifique (par exemple, Googlebot), utilisez :
<meta name="googlebot" content="noindex">
X-Robots-Tag
Vous pouvez également utiliser la balise X-Robots-Tag dans le fichier de configuration du site pour limiter davantage l’indexation des pages. Cette méthode offre un niveau supplémentaire de contrôle et de flexibilité pour gérer l’indexation de manière très précise.
Pour en savoir plus sur ce sujet, consultez notre guide complet sur la balise meta robots et la balise X-Robots-Tag.
Pages et fichiers généralement bloqués via le fichier robots.txt
1. Tableau de bord d’administration et fichiers système.
Fichiers internes et de service auxquels seuls les administrateurs ou webmasters du site web doivent avoir accès.
2. Pages auxiliaires qui n’apparaissent qu’après des actions spécifiques de l’utilisateur.
Pages vers lesquelles les clients sont redirigés après avoir passé une commande, les formulaires client, les pages d’autorisation ou de récupération de mot de passe.
3. Pages de recherche.
Les pages affichées après qu’un visiteur a saisi une requête dans le champ de recherche du site sont généralement inaccessibles aux robots des moteurs de recherche.
4. Pages de filtrage.
Les résultats affichés avec un filtre appliqué (taille, couleur, fabricant, etc.) constituent des pages distinctes et peuvent être considérés comme du contenu dupliqué. Les experts en référencement les empêchent généralement d’être explorées, sauf si elles génèrent du trafic pour des mots-clés de marque ou d’autres requêtes ciblées. Les sites agrégateurs, certains sites de commerce électronique et les pages de filtrage correctement configurées susceptibles de générer du trafic peuvent constituer une exception.
5. Fichiers d’un certain format.
Fichiers tels que photos, vidéos, documents PDF, fichiers JS. À l’aide du fichier robots.txt, vous pouvez restreindre l’exploration de fichiers individuels ou de fichiers d’une extension spécifique.
Syntaxe du fichier robots.txt
Les webmasters doivent comprendre la syntaxe et la structure du fichier robots.txt pour contrôler la visibilité de leurs pages web sur les moteurs de recherche. Le fichier robots.txt contient généralement un ensemble de règles qui déterminent quels fichiers d’un domaine ou d’un sous-domaine sont accessibles aux robots d’indexation. Ces règles peuvent soit bloquer, soit autoriser l’accès à des chemins d’accès spécifiques. Par défaut, si cela n’est pas explicitement indiqué dans le fichier robots.txt, tous les fichiers sont considérés comme autorisés à l’indexation.
Le fichier robots.txt est composé de groupes, chacun contenant plusieurs règles ou directives. Ces règles sont répertoriées une par ligne. Chaque groupe commence par une ligne User-agent qui spécifie le public cible des règles.
Un groupe fournit les informations suivantes :
- L’agent utilisateur auquel les règles s’appliquent.
- Les répertoires ou fichiers auxquels l’agent utilisateur est autorisé à accéder.
- Les répertoires ou fichiers auxquels l’agent utilisateur n’est pas autorisé à accéder.
Lors du traitement du fichier robots.txt, les robots d’exploration suivent le chemin le plus spécifique. Par exemple, si le fichier autorise l’exploration de tout le contenu du site web, interdit l’accès à un répertoire et autorise l’accès à un seul sous-répertoire de celui-ci, l’agent utilisateur accédera à tout le contenu et au sous-répertoire spécifié, en ignorant le reste du sous-répertoire interdit.
Un agent utilisateur ne peut correspondre qu’à un seul ensemble de règles. S’il existe plusieurs groupes ciblant le même agent utilisateur, ces groupes sont fusionnés en un seul groupe avant d’être traités. En cas de directives contradictoires, Google choisira la moins restrictive.
Voici un exemple de fichier robots.txt basique contenant deux règles :
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml
Comme les robots d’indexation recherchent l’ensemble de règles le plus spécifique, ce fichier empêchera Googlebot d’accéder au dossier /nogooglebot/ et permettra à tous les autres robots d’accéder à l’intégralité du site.
Lorsque vous indiquez des chemins d’accès dans les directives, le chemin est interprété comme englobant tous les chemins qui commencent par celui-ci. Dans cet exemple, cela inclurait des chemins tels que.
- https://www.example.com/nogooglebot/
- https://www.example.com/nogooglebot/folder/
- https://www.example.com/nogooglebot/folder/content.html
- https://www.example.com/nogooglebot/folder/content.html?parameter=0
En revanche, cela n’inclura pas ce chemin : https://www.example.com/folder/nogooglebot/.
Examinons maintenant plus en détail les différents éléments de la syntaxe du fichier robots.txt.
Caractères génériques
Si vous souhaitez contrôler plus précisément le comportement des robots d’indexation, vous pouvez utiliser des caractères génériques. Il en existe deux dans le fichier robots.txt : * et $.
Le caractère générique astérisque représente n’importe quelle séquence de symboles. Voici quelques exemples d’utilisation.
- User-agent: * — Inclut tous les agents utilisateurs.
- User-agent: googlebot* — Inclut les agents utilisateurs commençant par « googlebot », comme « googlebot-news » ou « googlebot/1.2 ».
- Disallow: */folder/ — Interdit toutes les occurrences de ce nom de dossier, qu’il se trouve dans le dossier racine ou dans un autre dossier.
- Disallow: /*.png — Interdit tous les chemins contenant « .png » n’importe où dans le chemin d’URL. Cela inclut les chemins comportant des symboles après l’extension, comme « /image.png?scr=site.com ».
Le caractère générique « $ » représente la fin de la ligne. Cela spécifie que seuls les chemins se terminant par la chaîne donnée sont inclus dans la directive. Voici quelques exemples d’utilisation.
- Disallow: /folder/$ — Interdit le chemin exact /folder/, tout en autorisant l’exploration des chemins qui le contiennent.
- Allow: /*.pdf$ — Autorise l’exploration des chemins se terminant par .pdf. Dans ce cas, les chemins d’exploration tels que « /file.pdf?parameters » sont exclus de la directive.
La directive User-Agent
La directive user-agent est obligatoire et définit le robot de recherche auquel s’appliquent les règles. Chaque groupe de règles commence par cette directive s’il existe plusieurs robots.
Google dispose de plusieurs robots chargés de différents types de contenu.
- Googlebot : explore les sites web pour les ordinateurs de bureau et les appareils mobiles
- Googlebot Image : explore les images des sites pour les afficher dans la section « Images » et les produits liés aux images
- Googlebot Video : analyse et affiche les vidéos
- Googlebot News : sélectionne des articles utiles et de haute qualité pour la section « Actualités »
- Google-InspectionTool : un outil de test d’URL qui imite Googlebot en explorant toutes les pages auxquelles il a accès
- Google StoreBot : analyse différents types de pages web, telles que les pages de détails des produits, le panier et les pages de paiement
- GoogleOther : récupère le contenu accessible au public sur les sites, y compris des explorations ponctuelles à des fins de recherche et développement internes
- Google-CloudVertexBot : explore les sites à la demande des propriétaires de sites lors de la création d’agents Vertex AI
- Google-Extended : un jeton de produit autonome utilisé pour déterminer si les sites contribuent à améliorer les applications Gemini, les API génératives Vertex AI et les futurs modèles
Il existe également un groupe distinct de robots, ou robots d’exploration à usage spécifique, qui comprend AdSense, Google-Safety et d’autres. Ces robots peuvent avoir des comportements et des autorisations différents de ceux des robots d’exploration courants.
La liste complète des robots Google (agents utilisateurs) est disponible dans la documentation d’aide officielle.
D’autres moteurs de recherche ont également des racines similaires, comme Bingbot pour Bing, Slurp pour Yahoo!, Baiduspider pour Baidu, et bien d’autres encore. Il existe plus de 500 robots de moteurs de recherche différents.
Exemple
- User-agent: * s’applique à tous les robots existants.
- User-agent: Googlebot s’applique au robot de Google.
- User-agent: Bingbot s’applique au robot de Bing.
- User-agent: Slurp s’applique au robot de Yahoo!
La directive Disallow
Disallow est une commande clé qui indique aux robots des moteurs de recherche de ne pas analyser une page, un fichier ou un dossier. Les noms des fichiers et des dossiers auxquels vous souhaitez restreindre l’accès sont indiqués après le symbole « / ».
Exemple 1. Spécification de différents paramètres après Disallow.
Disallow: /lien vers la page interdit l’accès à une URL spécifique.
Disallow: /nom du dossier/ interdit l’accès au dossier.
Disallow: /*.png$ interdit l’accès aux images au format PNG.
Disallow: /. L’absence de toute instruction après le symbole « / » indique que le site est entièrement fermé à l’exploration, ce qui peut être utile pendant le développement du site web.
Exemple 2. Désactiver l’exploration de tous les fichiers .PDF sur le site.
User-agent: Googlebot
Disallow: /*.pdf$
La directive Allow
Dans le fichier robots.txt, la directive Allow fonctionne à l’opposé de Disallow en accordant l’accès au contenu du site web. Ces commandes sont souvent utilisées conjointement, en particulier lorsque vous devez ouvrir l’accès à des informations spécifiques, comme une photo dans un répertoire de fichiers multimédias caché.
Exemple. Utilisation de Allow pour explorer une image dans un album fermé.
Spécifiez la directive Allow avec l’URL de l’image et, sur une autre ligne, la directive Disallow avec le nom du dossier où se trouve le fichier. L’ordre des lignes est important, car les robots d’indexation traitent les groupes de haut en bas.
Disallow: /album/
Allow: /album/picture1.jpg
La directive « robots.txt Allow All » est généralement utilisée lorsqu’il n’y a pas de restrictions ou d’interdictions spécifiques pour les moteurs de recherche. Cependant, il est important de noter que la directive « Allow: / » n’est pas un élément obligatoire du fichier robots.txt. En fait, certains webmasters choisissent de ne pas l’inclure du tout, se fiant uniquement au comportement par défaut des robots d’indexation des moteurs de recherche.
La directive Allow ne fait pas partie de la spécification robots.txt d’origine. Cela signifie qu’elle n’est pas nécessairement prise en charge par tous les robots. Si de nombreux robots d’indexation populaires, comme Googlebot, reconnaissent et respectent la directive Allow, d’autres peuvent ne pas le faire.
Selon la « Norme d’exclusion des robots », « les en-têtes non reconnus sont ignorés ». Cela signifie que pour les robots qui ne reconnaissent pas la directive « Allow », le résultat peut être différent de ce à quoi s’attendait le webmaster. Gardez cela à l’esprit lorsque vous créez vos fichiers robots.txt.
La directive Sitemap
La directive sitemap dans le fichier robots.txt indique le chemin d’accès au plan du site. Cette directive peut être omise si le plan du site porte un nom standard, se trouve dans le répertoire racine et est accessible via le lien « nom du site »/sitemap.xml, à l’instar du fichier robots.txt.
Exemple
Sitemap: https://website.com/sitemap.xml
Alors que le fichier robots.txt sert principalement à contrôler l’exploration de votre site web, le plan du site aide les moteurs de recherche à comprendre l’organisation et la structure hiérarchique de votre contenu. En incluant un lien vers votre plan du site dans le fichier robots.txt, vous offrez aux robots d’indexation des moteurs de recherche un moyen simple de localiser et d’analyser le plan du site, ce qui permet une exploration et une indexation plus efficaces de votre site web. Il n’est donc pas obligatoire, mais fortement recommandé, d’inclure une référence à votre plan du site dans le fichier robots.txt.
Commentaires
Vous pouvez ajouter des commentaires au fichier robots.txt pour expliquer des directives spécifiques, documenter les modifications ou les mises à jour apportées au fichier, organiser les différentes sections ou fournir un contexte aux autres membres de l’équipe. Les commentaires sont des lignes commençant par le symbole « # ». Les robots ignorent ces lignes lors du traitement du fichier. Ils vous aident, vous et les autres membres de l’équipe, à comprendre le fichier, mais n’affectent pas la façon dont les robots le lisent. Voici un exemple tiré du fichier robots.txt de Wizzair.
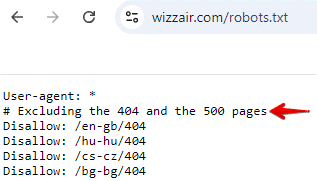
Si votre fichier robots.txt est assez volumineux et contient des directives non standard, il est préférable d’ajouter des commentaires expliquant l’objectif de ces directives.
Extensions non standard
Outre celles-ci, il existe quelques directives non standard pouvant être utilisées dans le fichier robots.txt.
Sitemap indique le chemin d’accès au fichier sitemap.
Exemple
Sitemap: https://website.com/sitemap.xml
Cette directive peut être omise si le plan du site porte un nom standard, se trouve dans le répertoire racine et est accessible via le lien « nom du site »/sitemap.xml, comme pour le fichier robots.txt.
Il s’agit d’une directive facultative, car Google et les autres moteurs de recherche recherchent automatiquement un plan du site, mais il est préférable de l’utiliser quand même, par mesure de bonne pratique, afin de s’assurer qu’ils le trouvent plus rapidement. Surtout si votre site comporte plusieurs plans du site, comme dans l’exemple ci-dessous.
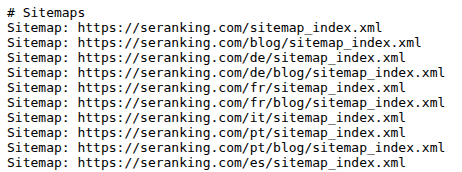
Crawl-delay spécifie le délai entre les requêtes de pages. À l’origine, cette directive visait à alléger la charge du serveur, mais elle est rarement utilisée aujourd’hui. Les robots d’indexation de Google ne tiennent pas compte de cette directive, contrairement à ceux de Bing, Yahoo et Yandex.
Utilisez Google Search Console pour signaler un excès d’exploration si vous estimez que cela pose problème.
Content-signal est une directive proposée par Cloudflare pour définir le comportement de l’IA sur votre site web. Elle vous permet d’autoriser ou d’interdire les entrées IA, l’entraînement IA et la recherche IA.
User-Agent: *
Content-Signal: ai-train=no, search=yes, ai-input=no
Allow: /
Dans cet exemple, la recherche sur le site est autorisée, mais l’utilisation de son contenu pour l’entraînement et les entrées IA est interdite.
Il s’agit d’une directive relativement récente, et de nombreux robots d’indexation ne la prendront pas en compte. Google n’a pas encore pris de position officielle à ce sujet. Pour l’instant, il est préférable de ne pas l’utiliser tant que Google ne l’aura pas officiellement adoptée.
Comment créer un fichier robots.txt
Un fichier robots.txt bien conçu constitue la base du référencement technique.
Comme le fichier a une extension .txt, n’importe quel éditeur de texte prenant en charge l’encodage UTF-8 fera l’affaire. Les options les plus simples sont le Bloc-notes (Windows) ou TextEdit (Mac).
Comme nous l’avons déjà mentionné, la plupart des plateformes CMS proposent également des solutions pour créer un fichier robots.txt. Par exemple, WordPress crée par défaut un fichier robots.txt virtuel, accessible en ligne en ajoutant « /robots.txt » au nom de domaine du site web. Cependant, pour modifier ce fichier, vous devez créer votre propre version. Cela peut se faire soit via un plugin (par exemple Yoast ou All in One SEO Pack), soit manuellement.
Magento et Wix, en tant que plateformes CMS, génèrent également automatiquement le fichier robots.txt, mais celui-ci ne contient que des instructions de base pour les robots d’indexation. C’est pourquoi il est recommandé de créer des instructions robots.txt personnalisées au sein de ces systèmes afin d’optimiser avec précision le budget d’indexation.
Vous pouvez également utiliser des outils tels que le générateur de fichier robots.txt de SE Ranking pour créer un fichier robots.txt personnalisé en fonction des informations fournies. Vous avez la possibilité de créer un fichier robots.txt à partir de zéro ou de choisir l’une des options proposées.
Si vous créez un fichier robots.txt à partir de zéro, vous pouvez le personnaliser de la manière suivante :
- En configurant des directives pour les autorisations d’exploration.
- En spécifiant des pages et des fichiers spécifiques via le paramètre de chemin d’accès.
- En déterminant quels robots doivent respecter ces directives.
Vous pouvez également sélectionner des modèles de fichiers robots.txt préexistants, comprenant des directives générales et CMS largement utilisées. Il est également possible d’inclure un plan du site dans le fichier. Cet outil vous fait gagner du temps en vous proposant un fichier robots.txt prêt à l’emploi à télécharger.
Titre et taille du document
Le fichier robots.txt doit être nommé exactement comme indiqué, sans utiliser de majuscules. Selon les consignes de Google, la taille du fichier ne doit pas dépasser 500 Ko. Le contenu apparaissant au-delà de cette limite sera ignoré par les moteurs de recherche.
Où placer le fichier
Le fichier robots.txt doit se trouver dans le répertoire racine de l’hébergeur du site web et être accessible via FTP. Avant d’effectuer toute modification, il est recommandé de télécharger le fichier robots.txt d’origine dans son format initial.
Comment vérifier votre fichier robots.txt
Des erreurs dans le fichier robots.txt peuvent empêcher des pages importantes d’apparaître dans l’index de recherche ou rendre l’ensemble du site invisible pour les moteurs de recherche. À l’inverse, des pages indésirables qui devraient rester privées pourraient également être indexées.
Vous pouvez facilement vérifier votre fichier robots.txt grâce au testeur de robots.txt gratuit de SE Ranking. Il vous suffit de saisir jusqu’à 100 URL à tester et de vérifier si elles sont autorisées à être explorées.
Vous pouvez également accéder à un rapport robots.txt dans Google Search Console. Pour ce faire, rendez-vous dans Paramètres > Exploration > robots.txt.
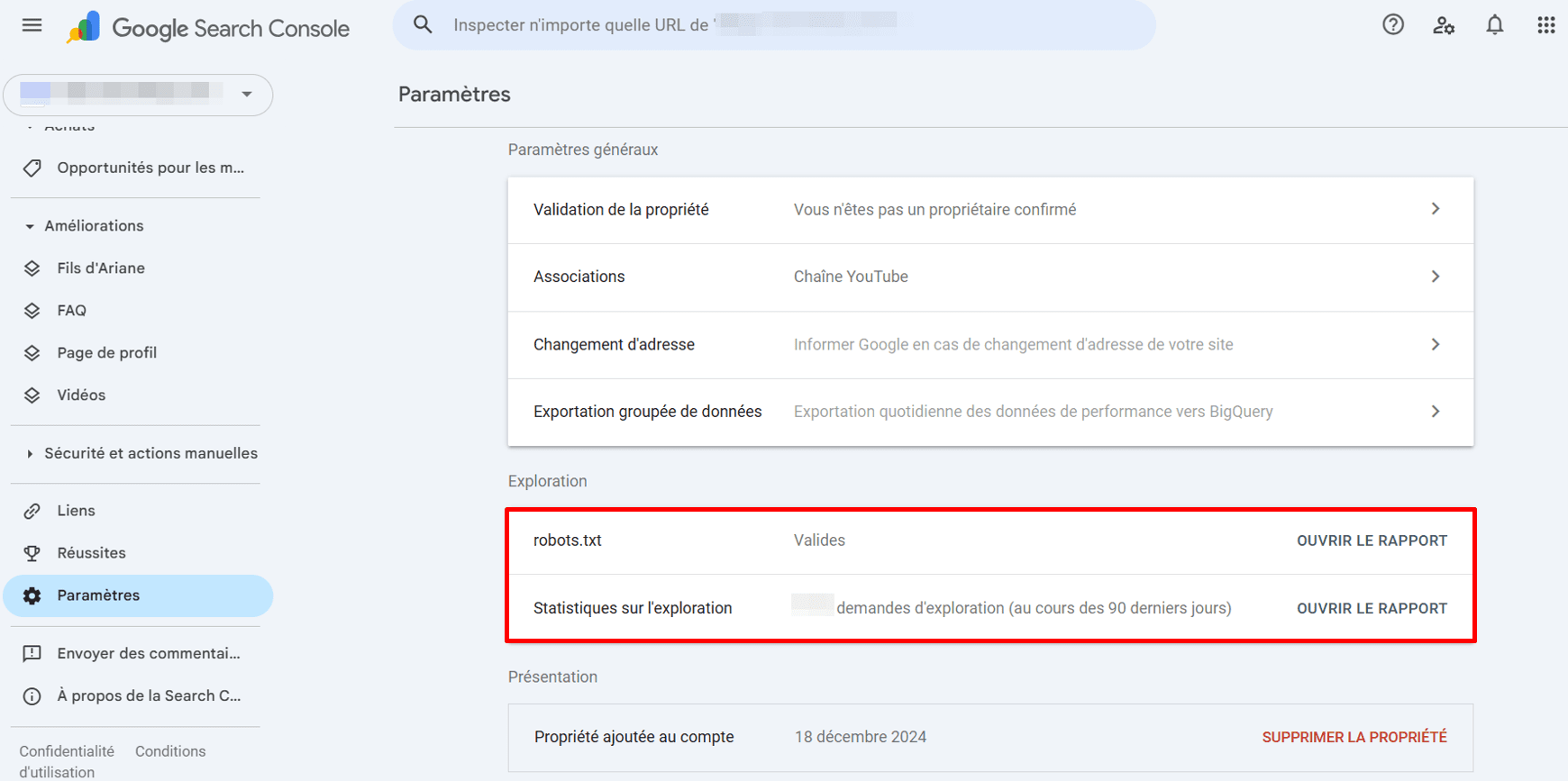
L’ouverture d’un rapport robots.txt révèle les fichiers robots.txt que Google a trouvés pour les 20 principaux hôtes de votre site, la date de leur dernière vérification, le statut de récupération et les problèmes détectés. Vous pouvez également utiliser ce rapport pour demander à Google de réindexer rapidement un fichier robots.txt si cela s’avère urgent.
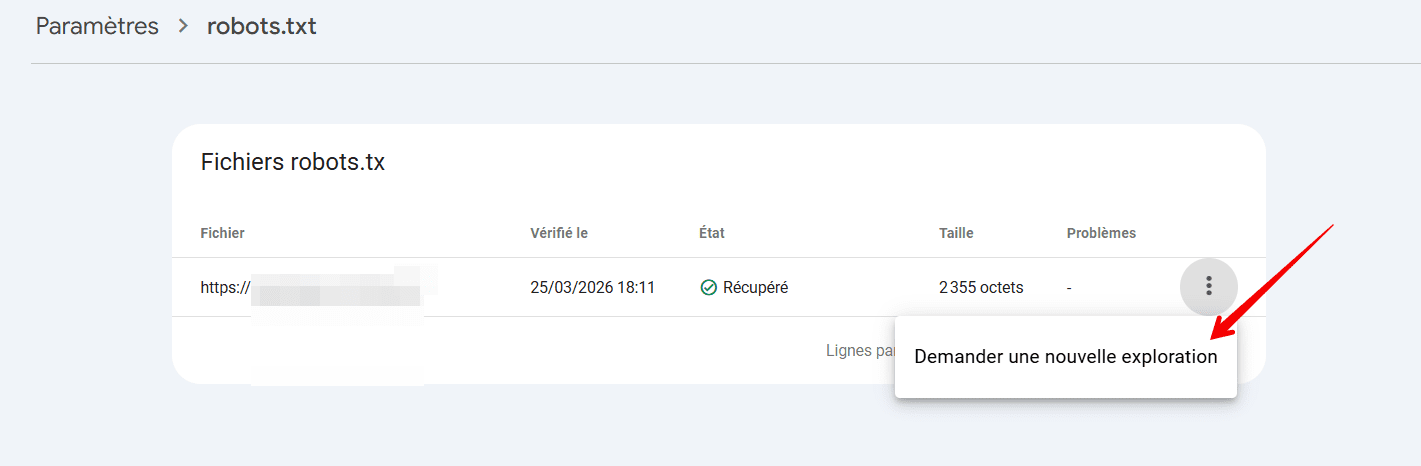
Problèmes courants liés au fichier robots.txt
Lorsque vous gérez le fichier robots.txt de votre site Web, plusieurs problèmes peuvent affecter la manière dont les robots d’exploration des moteurs de recherche interagissent avec votre site. Voici quelques problèmes courants :
- Incompatibilité de format : les robots d’indexation ne peuvent pas détecter ni analyser le fichier s’il n’est pas au format .txt.
- Emplacement incorrect : votre fichier robots.txt doit se trouver dans le répertoire racine. S’il se trouve, par exemple, dans un sous-dossier, les robots de recherche risquent de ne pas le trouver et d’y accéder.
- Mauvaise utilisation du caractère « / » dans la directive Disallow : une directive Disallow sans contenu implique que les robots ont l’autorisation de visiter toutes les pages de votre site web. Une directive Disallow avec le caractère « / » ferme votre site web aux robots. Il est toujours préférable de vérifier soigneusement votre fichier robots.txt pour vous assurer que les directives Disallow reflètent bien vos intentions.
- Lignes vides dans le fichier robots.txt : assurez-vous qu’il n’y a pas de lignes vides entre les directives. Sinon, les robots d’indexation pourraient avoir des difficultés à analyser le fichier. Le seul cas où des lignes vides sont autorisées est avant l’indication d’un nouvel User-agent.
- Bloquer une page dans le fichier robots.txt et ajouter une directive « noindex » : cela crée des signaux contradictoires. Les moteurs de recherche risquent de ne pas comprendre l’intention ou d’ignorer complètement l’instruction « noindex ». Il est préférable d’utiliser soit le fichier robots.txt pour bloquer l’exploration, soit la directive « noindex » pour empêcher l’indexation, mais pas les deux simultanément.
Outils/rapports supplémentaires pour vérifier les problèmes
Il existe de nombreuses façons de vérifier si votre site web présente d’éventuels problèmes liés au fichier robots.txt. Passons en revue les plus couramment utilisées.
1. Rapport Pages de la Google Search Console.
La section Pages de la Google Search Console contient des informations précieuses sur votre fichier robots.txt.
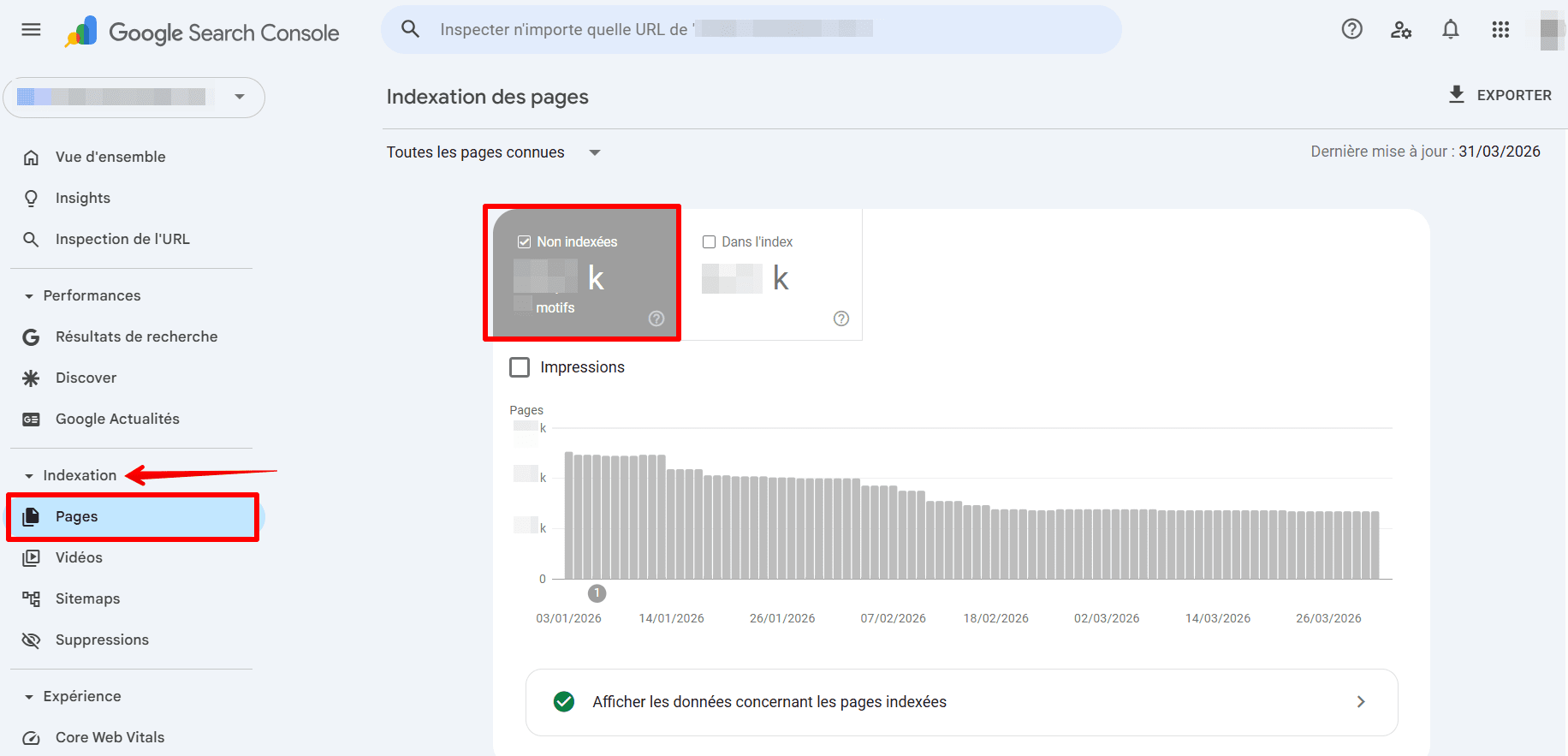
Pour vérifier si le fichier robots.txt de votre site Web empêche Googlebot d’explorer une page, procédez comme suit :
- Accédez à la section « Pages » et sélectionnez la catégorie « Non indexées ».
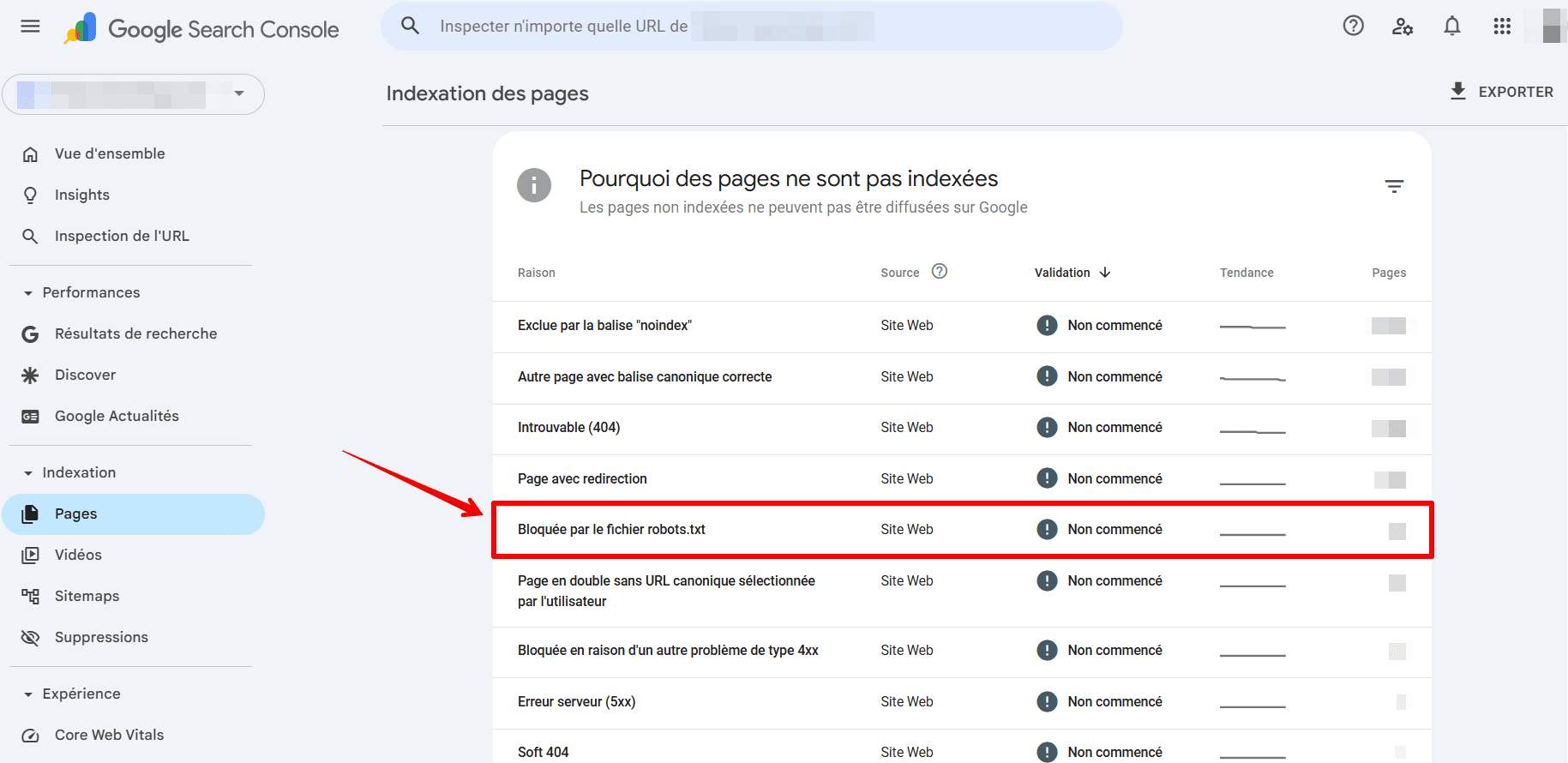
- Recherchez l’erreur intitulée « Bloqué par robots.txt » et sélectionnez-la.
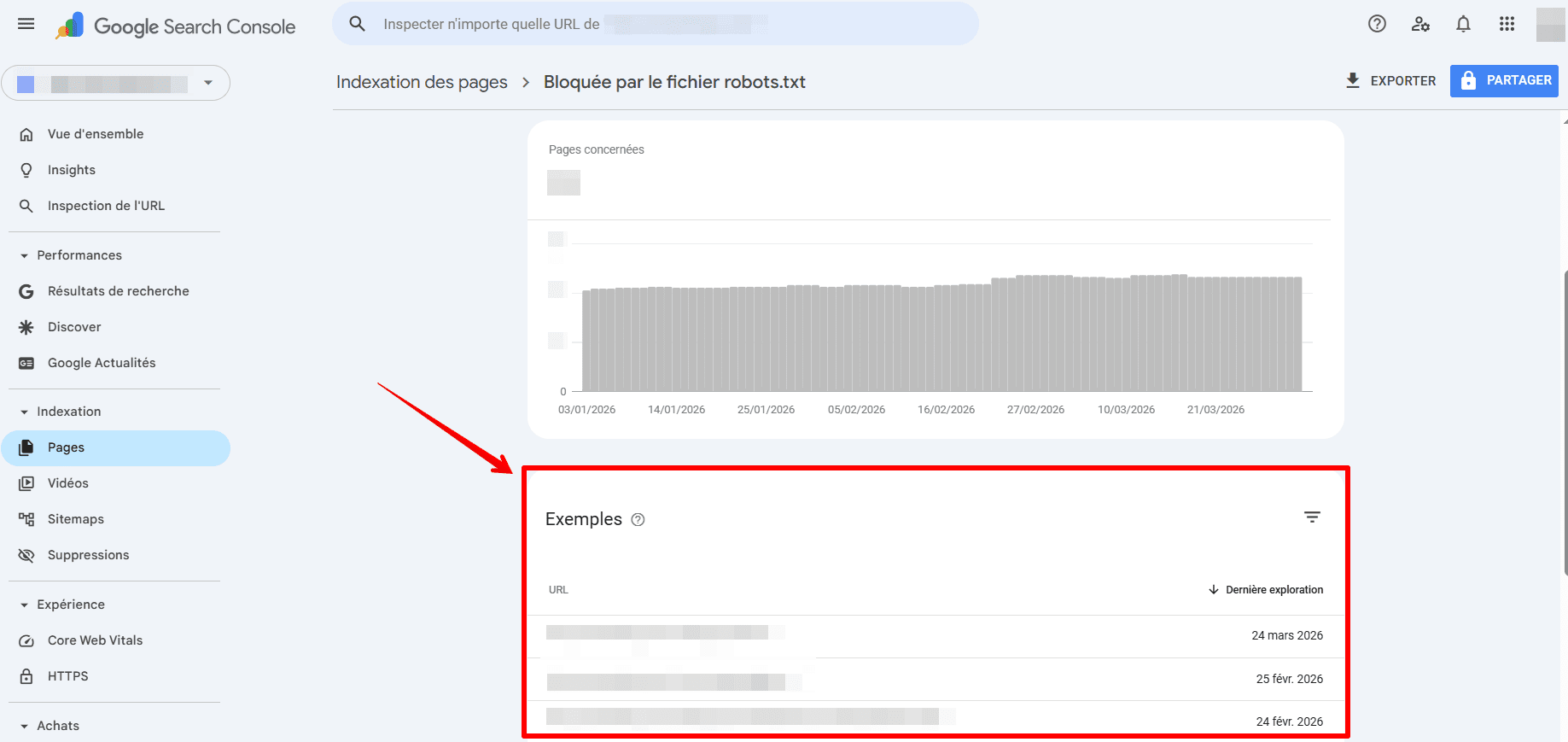
- En cliquant sur cette section, vous verrez s’afficher une liste des pages actuellement bloquées par le fichier robots.txt de votre site web. Assurez-vous qu’il s’agit bien des pages que vous souhaitez bloquer.
Vérifiez également si vous rencontrez le problème suivant dans cette section : « Indexé, bien que bloqué par le fichier robots.txt ».
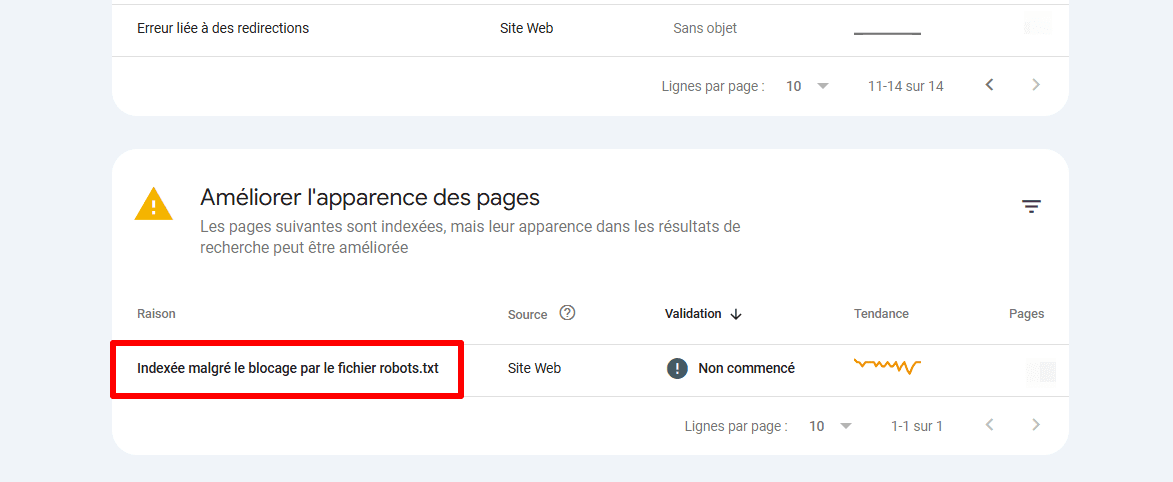
Vous pouvez également vérifier si des URL individuelles sont indexées en les collant dans le champ de recherche de l’outil d’inspection d’URL de Google Search Console. Cela peut vous aider à détecter d’éventuels problèmes d’indexation causés par des directives contradictoires ou des règles robots.txt mal configurées.
Voici un guide complet de Google Search Console sur la détection et la résolution des problèmes liés à l’indexation.
2. Audit de site web de SE Ranking
L’outil d’audit de site web de SE Ranking (et d’autres outils similaires) fournit un aperçu complet de votre fichier robots.txt, y compris des informations sur les pages bloquées par ce fichier. Il peut également vous aider à vérifier les problèmes liés à l’indexation et au plan de site XML.
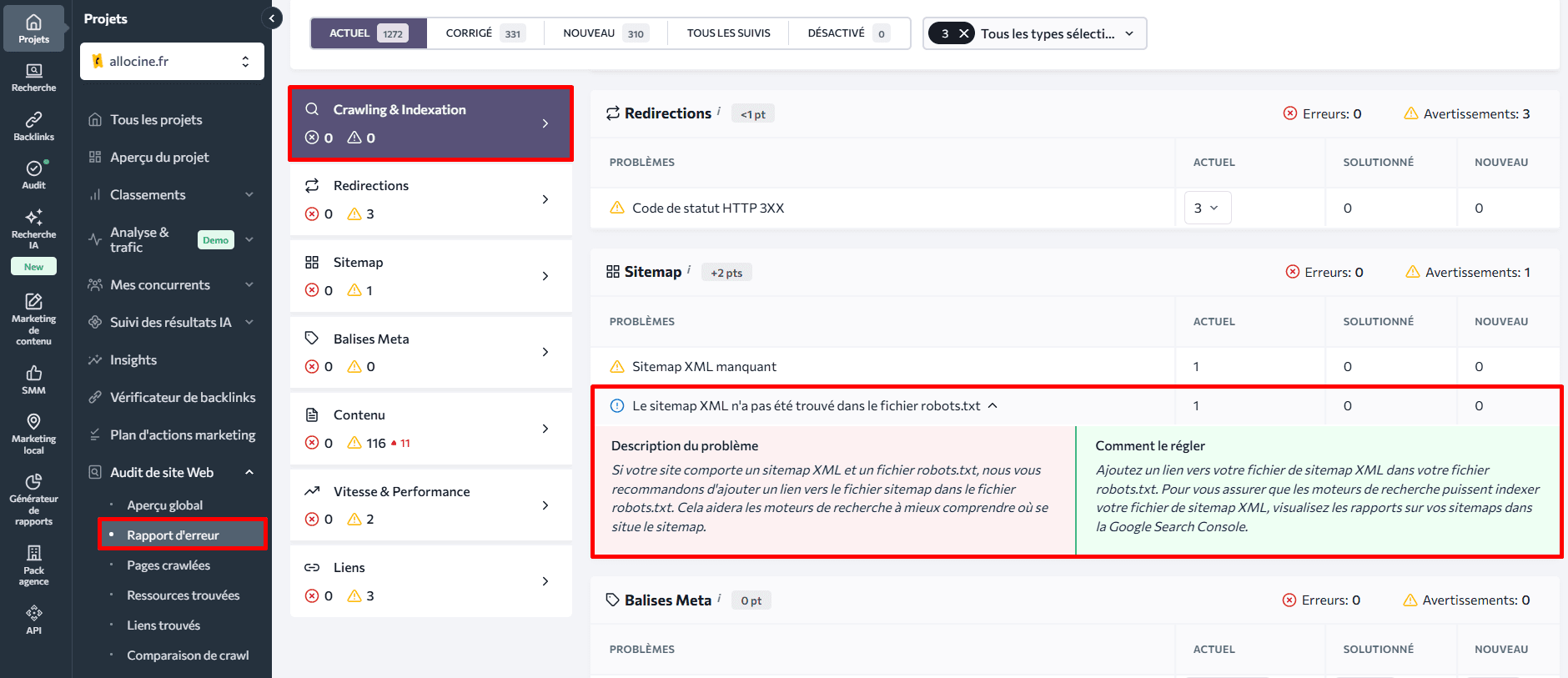
Pour obtenir des informations précieuses sur votre fichier robots.txt, commencez par explorer le rapport de problèmes généré par l’outil. Parmi les plus de 120 indicateurs analysés, vous trouverez le paramètre « Bloqué par robots.txt » dans la section « Exploration ». En cliquant dessus, vous verrez s’afficher une liste des pages web dont l’exploration est bloquée, accompagnée de descriptions des problèmes et de conseils de correction rapide.
Cet outil permet également de vérifier facilement si vous avez ajouté un lien vers le fichier de plan du site dans le fichier robots.txt. Il suffit de vérifier l’état « Plan du site XML introuvable dans le fichier robots.txt » dans la même section.
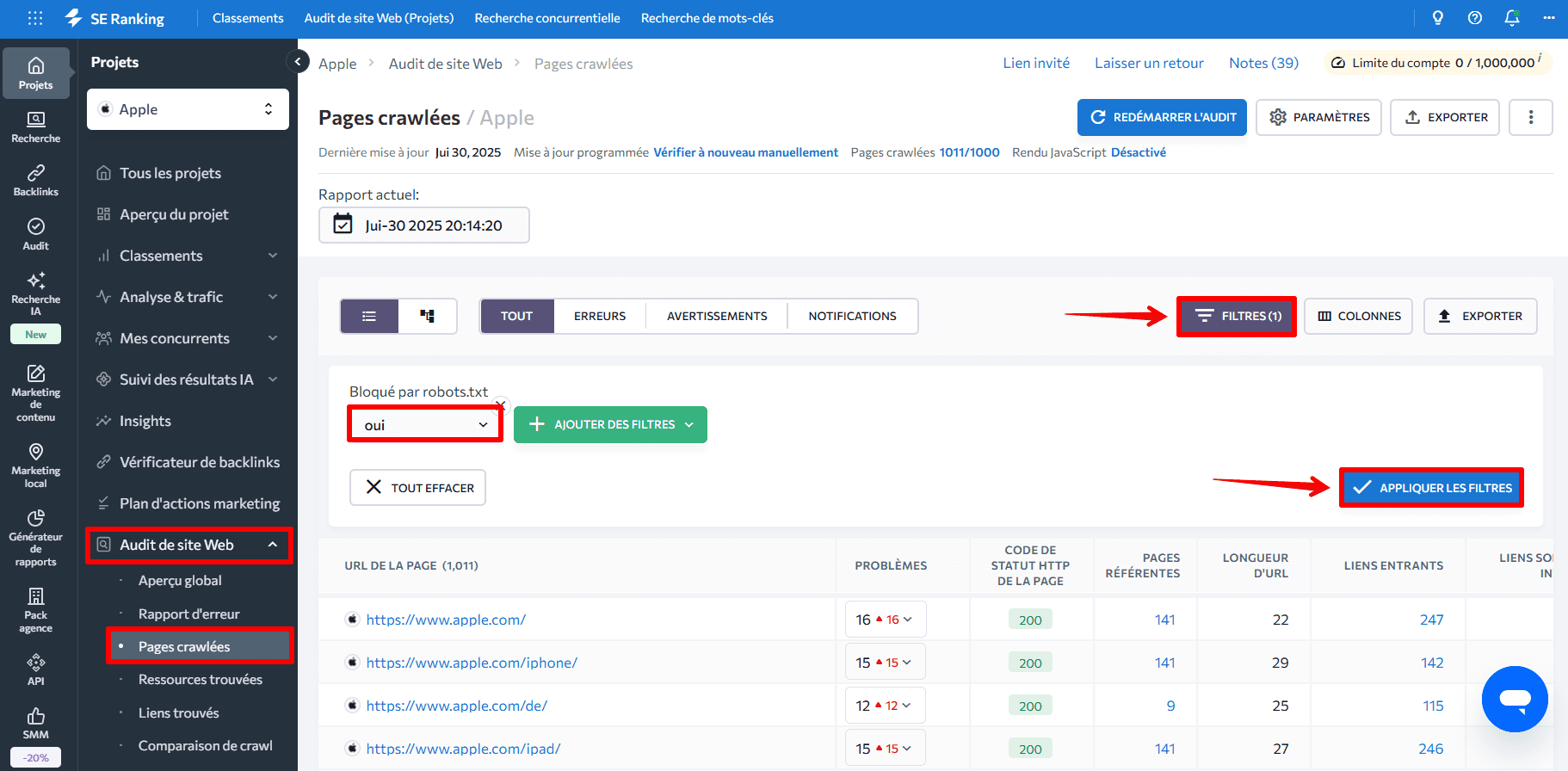
En accédant à l’onglet « Pages explorées » dans le menu de gauche, vous pouvez analyser les paramètres techniques de chaque page individuellement. Appliquez des filtres pour vous concentrer sur la résolution des problèmes critiques sur les pages les plus importantes. Par exemple, l’application du filtre « Bloqué par robots.txt > Oui » affichera toutes les pages bloquées par le fichier.
3. Générateur et testeur de fichiers robots.txt de SE Ranking
Le générateur de robots.txt de SE Ranking facilite la création du fichier sans risquer qu’une faute de frappe ne vienne contrecarrer vos intentions. Pour créer un fichier robots.txt manuellement, ajoutez les chemins d’accès que vous souhaitez autoriser ou interdire, spécifiez les robots auxquels cet ensemble de règles doit s’appliquer, puis ajoutez votre plan du site. Vous pouvez également ajouter tous les formats d’images et de fichiers à la règle.
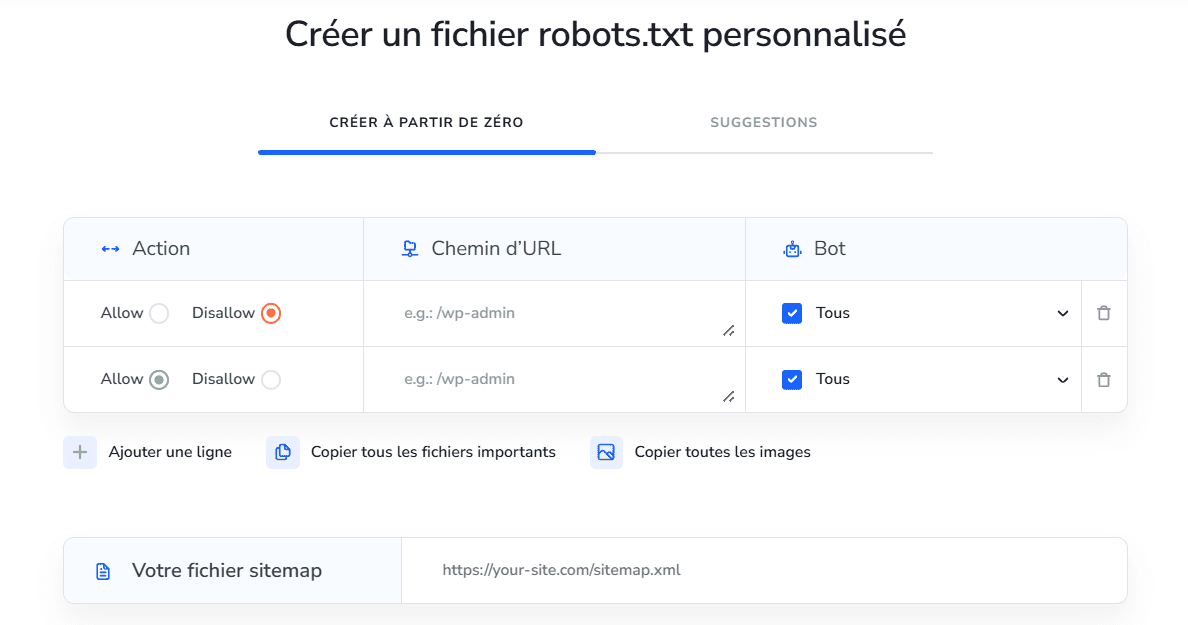
Vous pouvez accélérer encore davantage ce processus en utilisant l’un des préréglages robots.txt. Utilisez des fichiers robots.txt prêts à l’emploi pour les plateformes CMS les plus populaires ou ajoutez des ensembles de règles courants, comme l’interdiction totale d’accès aux robots les plus bloqués.
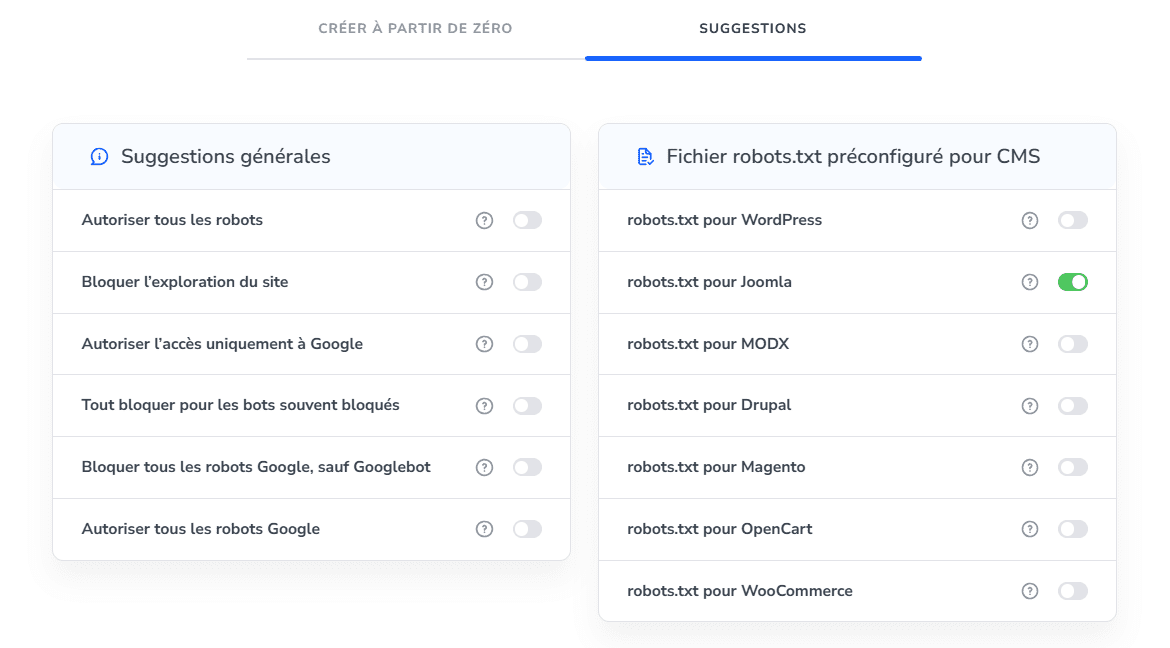
Vous pouvez ajouter des règles personnalisées à ces fichiers ultérieurement.
Si vous souhaitez tester votre fichier robots.txt, utilisez le testeur de robots.txt de SE Ranking. Saisissez l’URL de votre site web, et l’outil vous affichera le fichier et vérifiera s’il contient des incohérences. Vous pouvez également l’utiliser pour vérifier les directives d’une URL spécifique sur le site. L’outil indiquera si l’accès est autorisé ou non pour l’agent utilisateur choisi.
Meilleures pratiques SEO
Pour vous assurer que les robots d’indexation indexent correctement le contenu de votre site web et que celui-ci fonctionne bien, suivez ces bonnes pratiques SEO :
- Veillez à respecter la casse dans le fichier robots.txt : les robots d’indexation interprètent les noms de dossiers et de sections en tenant compte de la casse. Il est donc essentiel d’utiliser la casse appropriée pour éviter toute confusion et garantir une exploration et une indexation précises.
- Commencez chaque directive sur une nouvelle ligne, avec un seul paramètre par ligne.
- Évitez d’utiliser des espaces, des guillemets ou des points-virgules lorsque vous rédigez des directives.
- Utilisez la directive Disallow pour empêcher l’exploration de tous les fichiers d’un dossier ou répertoire spécifique. Cette technique est plus efficace que de lister chaque fichier séparément.
- Utilisez des caractères génériques pour des instructions plus flexibles lors de la création du fichier robots.txt. L’astérisque (*) représente n’importe quelle variation de valeur, tandis que le signe dollar ($) agit comme une restriction et marque la fin du chemin d’accès de l’URL.
- Créez un fichier robots.txt distinct pour chaque domaine. Cela permet d’établir des directives d’exploration individuelles pour chaque site.
- Testez toujours un fichier robots.txt pour vous assurer qu’il ne bloque pas d’URL importantes.
Conclusion
Nous avons abordé tous les aspects importants du fichier robots.txt, de sa syntaxe aux bonnes pratiques en passant par les problèmes courants. Vous savez désormais pourquoi un fichier robots.txt bien configuré est essentiel pour un référencement naturel (SEO) et une gestion de site web efficaces. Il optimise les budgets d’exploration, guide les moteurs de recherche vers les contenus importants et protège les zones sensibles.
N’oubliez pas de revoir et de mettre à jour régulièrement votre fichier robots.txt à mesure que votre site web évolue. Utilisez les outils et les techniques dont nous avons parlé pour vous assurer que votre fichier fonctionne comme prévu.

