Comprendre CSS et JavaScript en SEO
En tant que spécialiste du référencement, vous n’avez pas vraiment besoin d’exploiter toutes les subtilités du développement de sites Web. Mais vous devez connaître les bases, car la façon dont un site Web est codé a un grand impact sur ses performances et donc sur son potentiel de référencement. Dans le post sur les balises HTML, nous avons passé en revue les bases HTML que vous devez comprendre pour faire efficacement le référencement de sites Web. Cette fois, je vous propose de creuser dans d’autres langages de codage que les développeurs utilisent pour rendre un site Web attrayant et le rendre interactif.
Les langages sont CSS et JavaScript, et dans cet article, je vais vous présenter chacun des deux. Ensuite, nous passerons en revue les principales erreurs CSS et JS auxquelles vous pouvez être confronté lors de l’audit de votre site Web. Je vais expliquer pourquoi chacune des erreurs est importante et comment elles peuvent être corrigées. La partie réparation est quelque chose que vous attribuerez probablement aux développeurs de votre site Web. C’est juste que cette fois, vous parlerez le même langage car après avoir lu ce guide, vous saurez ce qu’est le CSS externe et pourquoi les fichiers JS renvoyant un code de réponse 302 sont un problème.
Qu’est-ce qui est CSS ?
CSS signifie Cascading Style Sheets et, comme son nom l’indique, il permet de créer des sites Web avec style. CSS est toujours utilisé avec HTML. C’est le papier d’emballage qui donne à un coffret cadeau un aspect joyeux. Une page Web HTML simple ressemblerait à ceci moins la largeur définie et l’alignement à gauche.

Le fait est qu’aujourd’hui, CSS est utilisé sur tous les sites Web, même s’il s’agit d’une page plutôt terne d’une série de notes techniques RFC sur le fonctionnement d’Internet.
Le balisage HTML définit la structure d’une page Web et définit ses éléments d’une manière que Google peut comprendre. CSS, à son tour, stylise l’en-tête, le pied de page et la navigation du site Web, les rendant visuellement attrayants et conviviaux. Avec CSS, vous pouvez faire un tas de choses sympas :
• Définir la couleur, les caractères et la taille du texte,
• Définir l’espacement entre les éléments,
• Contrôler la disposition des éléments sur la page,
• Ajoutez des images d’arrière-plan ou des couleurs d’arrière-plan.
CSS peut être implémenté de 3 manières :
• En ligne. C’est à ce moment que les attributs de style sont ajoutés individuellement à chaque élément HTML que vous souhaitez styliser. Cette méthode est rarement utilisée car elle prend trop de temps.
• En interne. Pour définir des styles pour l’ensemble de la page Web, l’élément <style> est ajouté à la section <head> de la page. Cette méthode est utilisée lorsque vous devez donner à certaines pages de destination un aspect unique.
• Extérieurement. La manière la plus courante d’implémenter CSS consiste à utiliser une feuille de style externe au format .css. Le fichier est lié à la section <head> de la page. Cette méthode est la plus répandue car elle permet de définir le style de tout un site Web à l’aide d’un seul document. La pratique courante, cependant, consiste à utiliser des fichiers CSS séparés pour différents types de pages (par exemple, les pages de catégories, les blogs, à propos de nous, etc.) car cela améliore la vitesse de chargement des pages.
Comment Google gère CSS
Dans le passé, Google ne se souciait pas trop du CSS et n’interprétait que le balisage HTML de la page. Tout a changé avec la mise à jour adaptée aux mobiles en 2015. En réponse à la popularité croissante de la recherche mobile, Google a décidé de récompenser les sites Web qui offraient une expérience utilisateur transparente sur les appareils mobiles. Et pour s’assurer que la page est adaptée aux mobiles, Google a dû la restituer à la manière des navigateurs, ce qui impliquait de charger et d’interpréter les fichiers CSS et JavaScript.
L’algorithme de mise en page repose également sur CSS. Il vise à déterminer si les utilisateurs peuvent facilement trouver le contenu sur la page et CSS aide Google à comprendre comment la page est présentée à la fois sur ordinateur et sur mobile, et où exactement dans la page se trouve chaque élément de contenu : au premier plan, au centre, dans la barre latérale ou au bas de la page bien en dessous du pli.
Qu’est-ce que c’est JavaScript ?
Alors que CSS ajoute du style à un site Web, JavaScript ajoute de la dynamique. Il donne vie au contenu en mettant à jour les éléments de la page Web en temps réel en réponse à l’action d’un utilisateur. Les formulaires contextuels, les cartes interactives, les graphiques animés, les sites Web avec un contenu continuellement mis à jour (par exemple, les prévisions météorologiques, les taux de change) sont tous des exemples d’implémentation de JavaScript.
Chez SE Ranking, nous utilisons également JavaScript. La plupart des effets sympas que vous voyez sur la plate-forme SE Ranking sont également alimentés par JS. Peut-être vous vous souvenez de notre page de destination des vœux de Noël 2019 avec des flocons de neige tombant qui ont créé l’ambiance des vacances. Nos développeurs ont utilisé JavaScript pour chorégraphier la danse des flocons de neige. En outre, nous avons récemment mis à jour notre page de destination Surveillance des modifications de page, qui comporte désormais une animation JavaScript conçue pour expliquer le fonctionnement de l’outil.
Juste pour vous donner une meilleure idée de la façon dont JavaScript transforme les sites Web, permettez-moi de vous montrer la même section de la page de destination avec JavaScript désactivé.
Dans le même temps, malgré ses puissantes capacités, JavaScript n’est pas aussi omniprésent que HTML et CSS en matière de développement de sites Web. Et l’une des raisons en est les problèmes de référencement.
- S’il n’est pas implémenté correctement, JavaScript peut conduire à ce qu’une partie de votre contenu ne soit pas indexée. Google doit rendre les fichiers JS pour voir votre page comme le font les utilisateurs, et s’il ne le fait pas, il indexera votre page sans les éléments JS. Ceci, à son tour, peut entraver votre classement si le contenu non indexé est crucial pour répondre à l’intention de l’utilisateur ;
- Les sections de page injectées avec JavaScript peuvent contenir des liens internes. Encore une fois, si Google ne parvient pas à rendre JavaScript, il ne suivra pas les liens. Ainsi, des pages entières peuvent ne pas être indexées à moins qu’elles ne soient liées à d’autres pages ou au plan du site. Ensuite, avec JavaScript, il est possible que vous codez vos liens d’une manière que Google ne peut pas comprendre, et par conséquent, il ne suivra pas les liens.
- Les fichiers JavaScript sont assez lourds et les ajouter à une page peut ralentir considérablement sa vitesse de chargement. À son tour, cela peut entraîner des taux de rebond plus élevés et des classements inférieurs.
Certes, tous ces problèmes peuvent être évités tant que vous comprenez comment Google rend JavaScript et comment rendre votre code JS convivial pour la recherche.
Comment Google gère JavaScript ?
Au cours des six dernières années, Google a multiplié par cent sa capacité à explorer et à indexer JavaScript. Mais le processus est encore assez compliqué, et beaucoup de choses peuvent mal tourner.
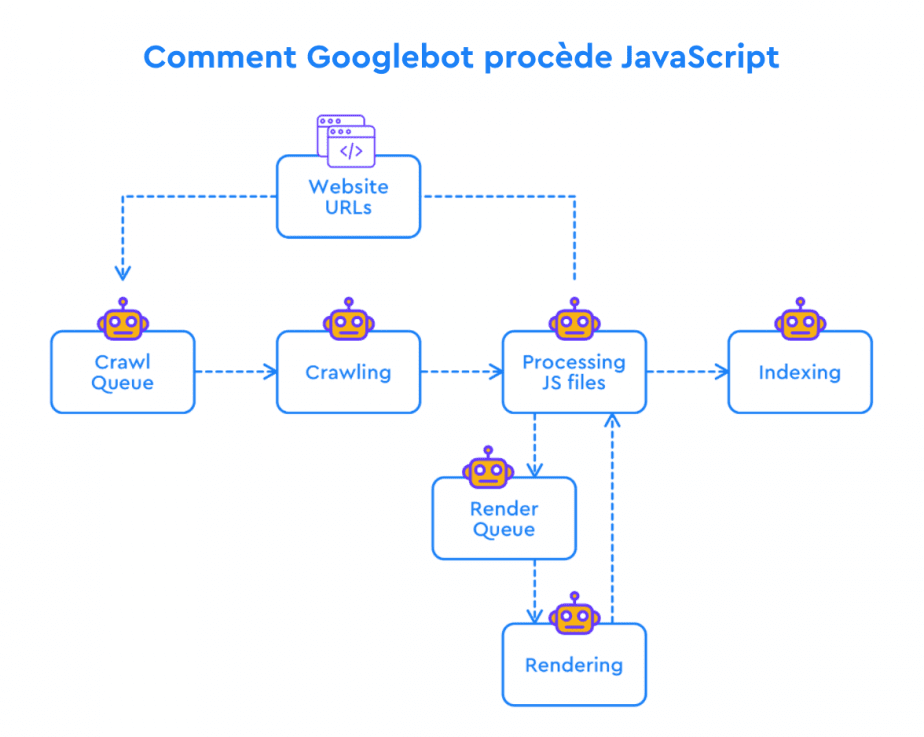
Avec des pages HTML normales, tout est clair et simple. Googlebot explore une page et analyse son contenu, y compris les liens internes. Ensuite, le contenu est indexé pendant que les URL découvertes sont ajoutées à la file d’attente d’exploration, et le processus recommence.
Lorsque JavaScript est ajouté à l’équation, le processus devient un peu plus lourd. Pour voir ce qui est caché dans le JavaScript qui ressemble normalement à un lien unique vers le fichier JS, Googlebot doit d’abord l’analyser, le compiler et l’exécuter. C’est ce qu’on appelle le rendu JS et ce n’est qu’une fois cette étape terminée que Google peut voir tout le contenu d’une page dans les balises HTML, le langage qu’il peut comprendre. À ce stade, Google peut procéder à l’indexation des éléments alimentés par JS et à l’ajout des URL cachées dans JS à la file d’attente d’exploration.
Maintenant, ces complications sont-elles quelque chose dont vous devriez vous soucier en termes de référencement ? Il y a tout juste un an, ils l’étaient.
Le rendu JavaScript est très gourmand en ressources et coûteux, et jusqu’à récemment, Google ne rendait pas immédiatement JavaScript. Il indexerait d’abord les parties HTML simples facilement disponibles de la page, puis au cours de la deuxième vague d’indexation, Google traiterait le JavaScript. En 2018, John Mueller a affirmé qu’il avait fallu quelques jours à quelques semaines pour que la page soit rendue. Par conséquent, les sites Web qui s’appuyaient fortement sur JavaScript ne pouvaient pas s’attendre à ce que leurs pages soient indexées rapidement. En outre, ils pourraient avoir des problèmes avec les nouvelles pages entrant dans la file d’attente d’exploration, car Google ne pouvait pas suivre les liens internes immédiatement.
Lors de l’une des dernières heures de bureau de JavaScript SEO, Martin Splitt a rassuré les webmasters que la file d’attente de rendu se déplace désormais beaucoup plus rapidement et qu’une page est normalement rendue en quelques minutes, voire quelques secondes. Néanmoins, le codage de JavaScript d’une manière conviviale pour la recherche est encore assez délicat, et les sessions hebdomadaires de JavaScript SEO pendant les heures de bureau le prouvent évidemment. Les cas partagés par les utilisateurs démontrent que les choses peuvent très mal tourner si JavaScript n’est pas codé correctement. Permettez-moi d’illustrer mon propos par quelques problèmes courants.
CONTENU RÉVÉLÉ EN CLIC/DÉFILEMENT
JavaScript est souvent utilisé pour implémenter un défilement infini ou pour masquer du contenu à des fins UX et permettre aux utilisateurs de révéler des informations supplémentaires en cliquant sur le bouton.
Le problème ici est que Googlebot ne clique pas ou ne fait pas défiler comme les utilisateurs le font dans leurs navigateurs.
Il a sûrement ses propres solutions de contournement, mais elles peuvent fonctionner ou non selon la technologie que vous utilisez. Et si vous implémentez les choses d’une manière que Google ne peut pas comprendre, vous vous retrouverez avec une partie de votre contenu JS non indexé.
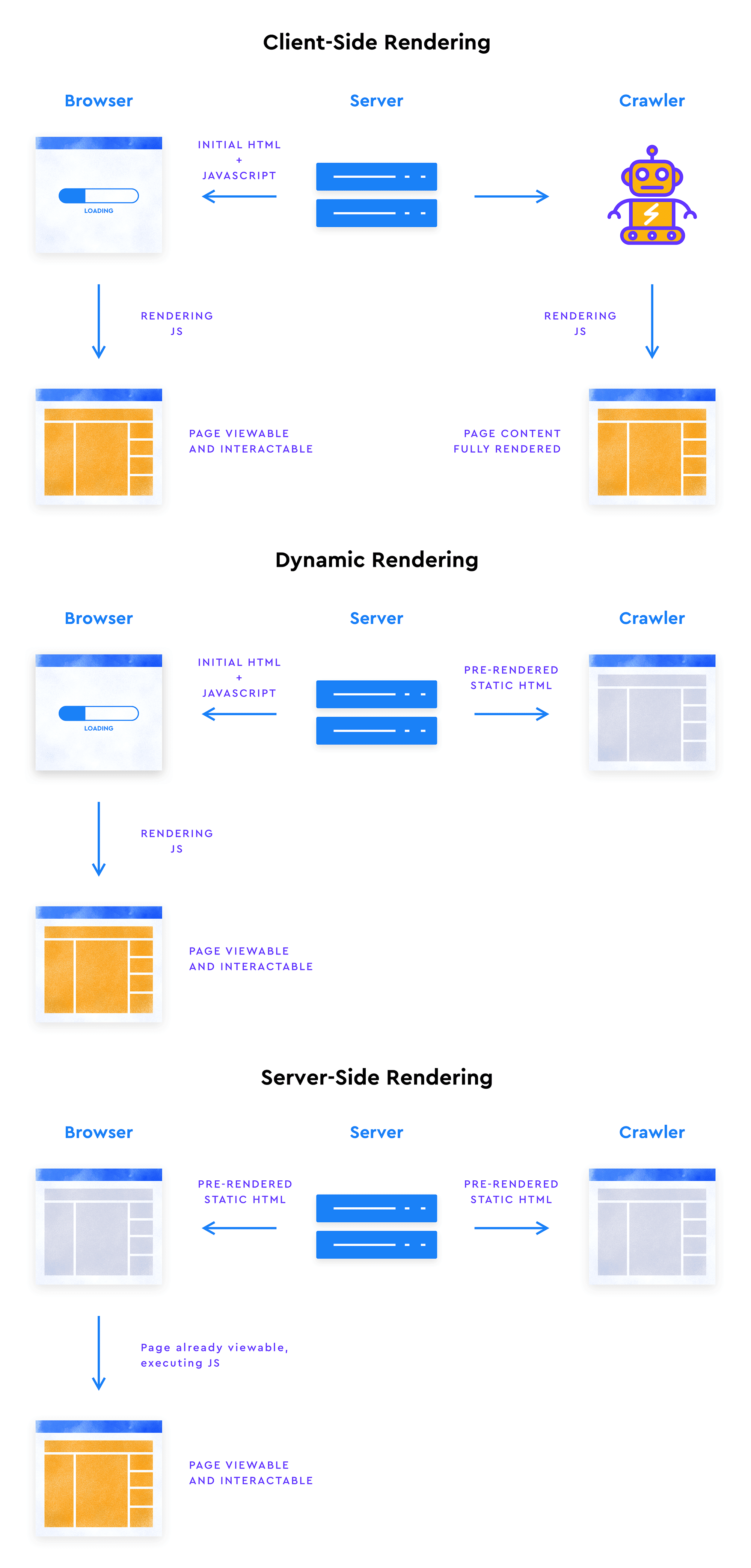
Google peut voir et indexer le contenu caché tant qu’il apparaît dans le DOM – c’est là que le code HTML source est envoyé avant d’être rendu par le navigateur. A ce stade, JavaScript peut être utilisé pour modifier le contenu.
Maintenant, disons que votre code HTML initial contient le contenu de la page dans son intégralité, puis vous utilisez les propriétés CSS pour masquer certaines parties du contenu et JS pour permettre aux utilisateurs de révéler ces parties cachées. Dans ce cas, tout va bien car le contenu est toujours là dans le code HTML et uniquement masqué pour les utilisateurs. Google peut toujours voir ce qui est caché dans le code CSS.
Si, d’un autre côté, votre code HTML initial ne contient pas certains éléments de contenu et qu’ils sont chargés dans le DOM par JavaScript déclenché par clic, Google ne verra pas ce type de contenu car Googlebot ne peut pas cliquer. Ce problème peut être résolu, cependant, en implémentant le rendu côté serveur, c’est-à-dire lorsque JS est exécuté côté serveur et que Google obtient le code HTML final prêt à l’emploi. Le rendu dynamique peut aussi être une solution.
Pour un défilement infini, les événements d’overscrolls doivent être évités car ils nécessitent que Googlebot fasse réellement défiler la page pour appeler le code JavaScript, ce que Google ne peut pas gérer. Au lieu de cela, vous pouvez implémenter un défilement infini et un chargement paresseux à l’aide de l’API Intersection Observer ou activer le chargement paginé avec le défilement infini.
LA FAÇON DONT VOUS CODEZ VOS LIENS JS IMPORTE
LA FAÇON DONT VOUS CODEZ VOS LIENS JS IMPORTE
Les liens permettent à Google de comprendre la structure du site et de découvrir le contenu du site Web. Ce dont vous devez vous souvenir lors de l’implémentation de JavaScript, c’est que Google ne suivra les liens injectés JS que s’ils sont correctement codés. Une balise HTML <a> avec une URL et un attribut href pointant vers la bonne URL est la règle d’or que vous devez suivre. Tant que la balise est là, tout va bien même si vous ajoutez du JS au code du lien.
<a href=”/page” onclick=”goTo(‘page’)”>your anchor text</a>
Pendant ce temps, toutes les autres variantes telles que les liens avec une balise <a> manquante ou un attribut href ou sans URL appropriée fonctionneront pour les utilisateurs, mais Google ne pourra pas les suivre.
<a onclick=”goTo(‘page’)”>your anchor text</a> <span onclick=”goTo(‘page’)”>your anchor text</span> <a href=”javascript:goTo(‘page’)”>your anchor text</a> <a href=”#”>no link</a>
Certes, si vous utilisez un plan du site, Google devrait toujours découvrir les pages de votre site Web même s’il ne peut pas suivre les liens internes menant à ces pages. Cependant, le moteur de recherche préfère toujours les liens vers un plan du site, car ils l’aident à comprendre la structure de votre site Web et la manière dont les pages sont liées les unes aux autres. En outre, les liens internes vous permettent de diffuser du jus de liens sur votre site Web.
TEST DU CODE JAVASCRIPT
Comme vous pouvez le voir, la façon dont JavaScript est codé peut faire ou défaire votre site Web. Je n’entrerai pas dans l’enquête sur divers cas d’utilisation de JavaScript pouvant entraver l’exploration et l’indexation de votre site Web par Google.
Permettez-moi simplement de partager un petit conseil avec vous : testez toujours votre code à l’aide des outils de Google tels que le test d’optimisation mobile ou l’outil d’inspection d’URL dans votre console de recherche Google pour voir comment Google affiche vos pages.
De préférence, les tests doivent être effectués au début du développement, lorsque les choses peuvent être corrigées plus facilement. Alors que l’outil d’inspection d’URL ne peut être utilisé qu’une fois la fonctionnalité en ligne sur un site Web, le test d’adaptation aux mobiles peut vous aider à détecter tous les bogues dès le début. Demandez simplement à vos développeurs de créer une URL vers leur serveur localhost à l’aide d’outils spéciaux (par exemple, ngrok ).
Une autre option serait d’utiliser les outils Chrome Dev optimisés par Lighthouse pour le débogage. Il est désormais intégré au navigateur Chrome : appuyez sur Commande+Option+J (Mac) ou Ctrl+Maj+J (Windows, Linux, Chrome OS) pour exécuter l’outil.
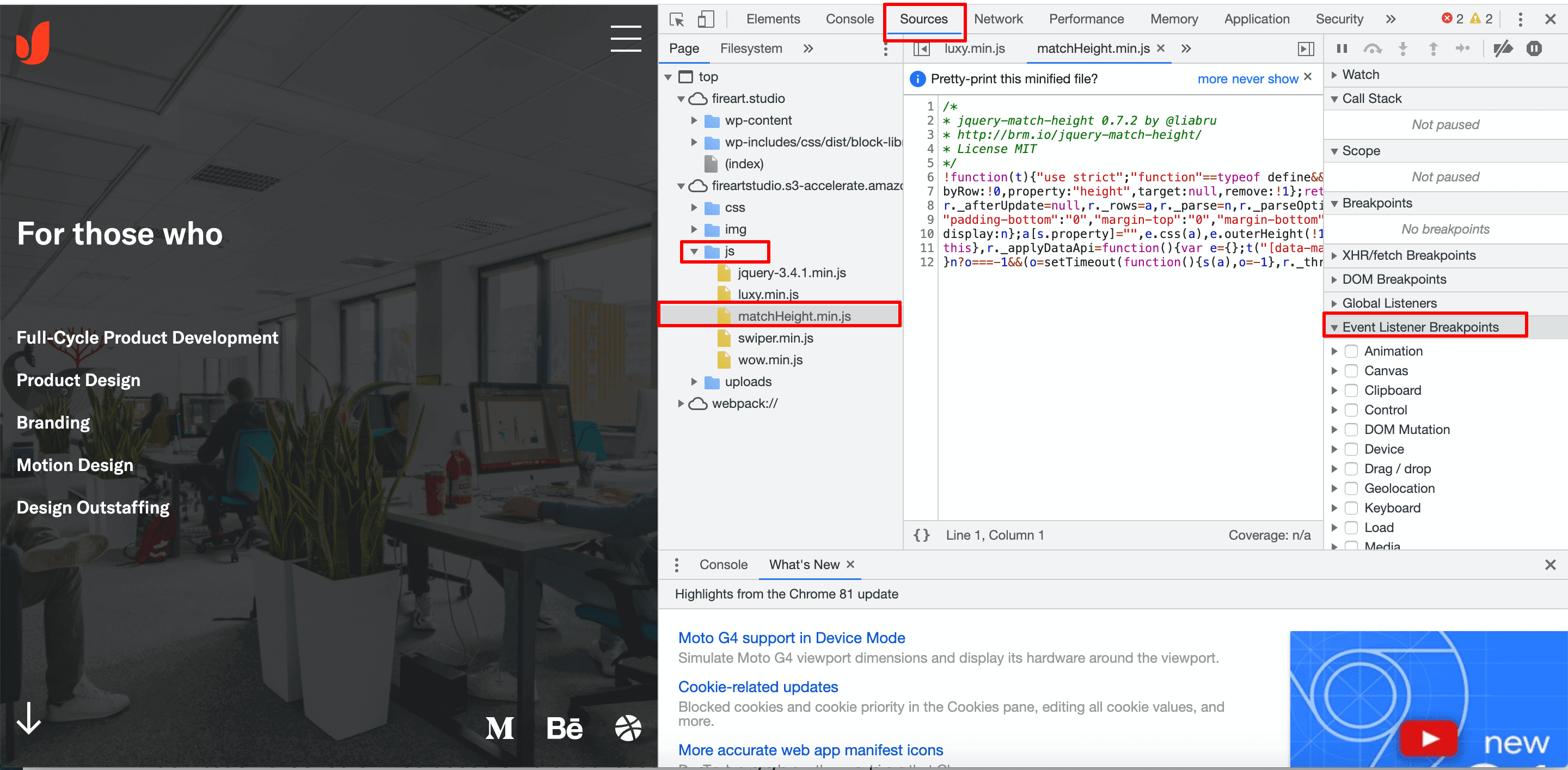
Ici, dans l’onglet Sources, vous pouvez trouver vos fichiers JS et inspecter le code qu’ils injectent. Ensuite, vous pouvez suspendre l’exécution de JS à un moment où vous pensez que quelque chose s’est mal passé à l’aide de l’un des points d’arrêt de l’écouteur d’événements et inspecter davantage le morceau de code. Une fois que vous pensez avoir détecté un bogue, vous pouvez ensuite modifier le code en direct pour voir en temps réel si la solution que vous avez trouvée résout le problème.
L’avantage des outils de développement Chrome est que toutes les modifications sont appliquées dans les navigateurs des utilisateurs et n’affectent pas les autres utilisateurs. Ils disparaîtront une fois que vous aurez appuyé sur le bouton Actualiser. L’outil peut être utilisé pour déboguer toute erreur de code, pas seulement celles liées à JavaScript. Donc, si vous rencontrez des problèmes avec le CSS de votre site Web, l’outil vous sera également utile.
Erreurs CSS et JavaScript courantes
Maintenant que vous savez ce que sont CSS et JavaScript et comment Google les interprète, vous vous demandez peut-être ce que les deux ont en commun. Et la réponse est qu’il s’agit de deux ressources stockées séparément sous forme de fichiers et liées à la page à partir de la section <head>.

Les navigateurs et Google doivent récupérer ces ressources pour restituer pleinement le contenu de la page. Parfois, Google et les navigateurs, ou simplement Google, ne parviennent pas à charger les fichiers, et les raisons de cela sont courantes à la fois pour CSS et JavaScript.
Dans des cas moins drastiques, Google et les navigateurs peuvent récupérer les fichiers, mais ils se chargent trop lentement, ce qui affecte négativement l’expérience utilisateur et peut également ralentir l’indexation du site Web.
Examinons maintenant chaque type d’erreur pouvant entraîner les problèmes décrits ci-dessus.
Google ne peut pas explorer les fichiers CSS et JS
Pour récupérer vos fichiers CSS et JavaScript, Googlebot doit être autorisé à le faire. Dans le passé, il était courant d’empêcher Google d’accéder à ces fichiers avec le fichier robots.txt, car Google ne les utiliserait pas de toute façon. Maintenant que le géant de la recherche s’appuie sur CSS et JavaScript pour comprendre le contenu du site Web, il encourage les webmasters à « autoriser l’exploration de tous les actifs du site qui affecteraient considérablement le rendu des pages : par exemple, les fichiers CSS et JavaScript qui affectent la compréhension des pages ». Si vous ne débloquez pas les fichiers, Google ne pourra pas les afficher et indexer le contenu JavaScript.
Le blocage des fichiers CSS et JavaScript n’est pas un facteur de classement négatif en soi, mais avec l’indexation mobile d’abord et l’amélioration du classement que les sites Web obtiennent pour être adaptés aux mobiles, il est préférable de laisser Google accéder à votre CSS. En parlant de JavaScript, s’il n’est utilisé que pour l’embellissement ou si, pour une raison quelconque, vous ne souhaitez pas que le contenu injecté JS soit indexé, vous pouvez bloquer les fichiers JavaScript. Dans tous les autres cas, laissez Google rendre vos fichiers.
Une autre chose qui peut empêcher Google d’explorer vos fichiers JavaScript est l’attribut noindex dans la balise meta robots. Si Google rencontre l’attribut avant d’exécuter JavaScript, il n’affichera pas la page. Pour cette raison, l’utilisation de JS pour modifier ou supprimer la balise meta robots ne fonctionne généralement pas car Google n’exécutera pas JavaScript en premier lieu.
Google et les navigateurs ne peuvent pas charger les fichiers CSS et JS
Après avoir lu le fichier robots.txt pour vérifier si vous autorisez l’exploration, Googlebot effectue une requête HTTP pour accéder à vos URL CSS et JavaScript. Pour qu’il procède au rendu des fichiers, il doit obtenir le code de réponse 200 OK. Parfois, cependant, d’autres codes d’état comme 4XX ou 5XX sont renvoyés.
CSS ET JAVASCRIPT AVEC STATUT 4XX
Les codes de réponse 4XX signifient que la ressource demandée n’existe pas. En parlant de fichiers CSS et JavaScript, cela signifie que Googlebot a suivi les URL indiquées dans la section <head> de la page, mais n’a pas trouvé vos fichiers aux emplacements désignés. Lorsqu’une page renvoie un 4XX, cela signifie généralement que la page a été supprimée. Avec CSS et JavaScript, l’erreur se produit souvent car le chemin d’accès au fichier n’est pas indiqué correctement. Il peut aussi s’agir d’un problème d’autorisation.
La mauvaise chose à propos des codes de réponse 4XX est que Google n’est pas le seul à rencontrer des problèmes pour rendre vos fichiers CSS et JavaScript. Les navigateurs ne seront pas non plus en mesure d’exécuter de tels fichiers, ce qui signifie que votre site Web ne sera pas aussi beau et perdra son interactivité.
Vous vous souvenez à quoi ressemble une page sans CSS appliqué à partir de l’image dans la première section de cet article. Si JS est utilisé pour charger du contenu sur le site Web (par exemple, les taux de change sur un site Web respectif), tout le contenu rendu dynamiquement sera manquant si le code ne s’exécute pas correctement.
Pour corriger l’erreur, vos développeurs devront d’abord déterminer ce qui les cause, et les raisons varieront en fonction des technologies utilisées.
CSS ET JAVASCRIPT AVEC STATUT 5XX
Les codes de réponse 5XX indiquent qu’il y a un problème du côté de votre serveur Web. Cela signifie qu’un navigateur ou Googlebot envoie une requête HTTP, localise votre fichier CSS/JavaScript mais que votre serveur ne parvient pas à renvoyer le fichier.
Dans le pire des cas, l’erreur se produit parce que l’ensemble de votre site Web est en panne. Cela se produit lorsque votre serveur ne peut pas faire face à la quantité de trafic. L’augmentation brutale du trafic peut être naturelle, mais dans la plupart des cas, elle est causée par un logiciel d’analyse syntaxique agressif ou un bot malveillant inondant votre serveur dans le but spécifique de le mettre hors service (DDoS).
Le serveur peut également ne pas fournir de fichier CSS/JavaScript si le navigateur ne parvient pas à les récupérer pendant la période définie, provoquant une erreur de délai d’attente 504. Cela peut se produire si le groupe de fichiers était trop volumineux ou si un utilisateur avait une connexion Internet lente.
Pour éviter cela, vous pouvez configurer votre serveur de site Web de manière à le rendre moins impatient. Mais faire attendre le serveur trop longtemps n’est pas non plus recommandé.
Le fait est que le chargement d’un énorme bundle JS prend beaucoup de ressources serveur et si toutes les ressources de votre serveur sont utilisées pour charger le fichier, il ne pourra pas répondre à d’autres demandes. En conséquence, l’ensemble de votre site Web est mis en attente jusqu’à ce que le fichier se charge.
Les fichiers CSS et JavaScript ne se chargent pas assez rapidement
Dans cette section, approfondissons les problèmes qui font que vos fichiers CSS et JavaScript se chargent pendant des siècles ou juste un peu plus longtemps que souhaité. Même si les navigateurs et Googlebot parviennent à charger et à afficher vos fichiers CSS et JS, mais que cela leur prend un certain temps, vous devriez vous sentir concerné.
Plus un navigateur peut charger rapidement les ressources de la page, meilleure est l’expérience des utilisateurs, et si les fichiers se chargent lentement, les utilisateurs doivent attendre un certain temps pour que la page soit rendue dans leur navigateur
CSS ET JAVASCRIPT AVEC STATUT 3XX
À l’instar du code de réponse 4xx, le code d’état 3ХХ signifie que vous n’utilisez pas une URL appropriée pour indiquer à Googlebot et au navigateur où réside votre fichier. C’est juste dans ce cas que vous n’utilisez pas la mauvaise adresse, mais plutôt l’ancienne – le code d’état 3XX indique que vous avez déplacé votre fichier CSS/JS vers une adresse différente mais que vous n’avez pas réussi à mettre à jour l’URL dans le code du site Web.
Googlebot et les navigateurs récupéreront toujours les fichiers puisque votre serveur les redirigera vers la bonne adresse. Ils devront simplement faire une requête HTTP supplémentaire pour atteindre l’URL de destination, et ce n’est pas bon pour le temps de chargement. L’impact sur les performances ne devrait pas être drastique si nous parlons d’une seule URL ou de quelques fichiers, mais à plus grande échelle, cela peut considérablement ralentir le temps de chargement de la page.
La solution ici est évidente : il vous suffit de remplacer toutes les anciennes URL CSS et JavaScript du code du site Web par des URL de destination à jour.
LA MISE EN CACHE N’EST PAS ACTIVE
Un excellent moyen de minimiser le nombre de requêtes HTTP vers votre serveur est d’autoriser la mise en cache dans un en-tête de réponse. Vous avez sûrement entendu parler de la mise en cache – vous receviez souvent une suggestion pour vider le cache de votre navigateur lorsque les informations sur un site Web ne s’affichent pas correctement.
En réalité, le cache enregistre une copie des ressources de votre site Web lorsqu’un utilisateur visite votre site. Ensuite, la prochaine fois que cet utilisateur viendra sur votre site Web, le navigateur n’aura plus à récupérer les ressources – il fournira aux utilisateurs la copie enregistrée à la place. La mise en cache est essentielle pour les performances du site Web car elle permet de réduire la latence et la charge du réseau.
L’en-tête HTTP de contrôle de cache est utilisé pour spécifier les règles de mise en cache que les navigateurs doivent suivre : il indique si une ressource particulière peut être mise en cache ou non, qui peut la mettre en cache et combien de temps la copie mise en cache peut durer. Il est fortement recommandé d’autoriser la mise en cache des fichiers CSS et JS, car les navigateurs téléchargent ces fichiers chaque fois que les utilisateurs visitent un site Web. Par conséquent, les stocker dans le cache peut augmenter considérablement le temps de chargement de la page.
Voici un exemple de mise en cache des fichiers CSS et JS sur un jour et accès public.
<filesMatch ".(css|js)$"> Header set Cache-Control "max-age=86400, public" </filesMatch>
Il convient cependant de noter que Googlebot ignore normalement l’en-tête HTTP de contrôle du cache, car le fait de suivre les directives définies sur le site Web mettrait trop de charge sur l’infrastructure d’exploration et de rendu.
Par conséquent, chaque fois que vous mettez à jour vos fichiers CSS et JS et que vous souhaitez que Google en prenne connaissance, il est recommandé de renommer votre fichier et de le télécharger en utilisant une URL différente. De cette façon, Google récupérera le fichier car il le traitera comme une ressource totalement nouvelle qu’il n’a jamais rencontrée auparavant.
LE NOMBRE DE FICHIERS COMPTE
L’utilisation de plusieurs fichiers CSS et JavaScript peut être pratique du point de vue du développeur, mais ce n’est pas très performant en termes de performances. Les navigateurs envoient une requête HTTP distincte pour charger chaque fichier, et le nombre de connexions réseau simultanées qu’un navigateur peut traiter est limité. Par conséquent, toutes les ressources CSS et JS d’une page se chargeront une par une en diminuant la vitesse de rendu.
Pour cette raison, il est recommandé de regrouper vos fichiers CSS et JavaScript pour réduire au minimum le nombre de fichiers qu’un navigateur devra charger.
Du point de vue de Google, trop de fichiers CSS et JavaScript ne sont pas un problème, ce qui signifie qu’il les rendra de toute façon. Mais plus vous avez de fichiers, plus vous dépensez votre budget d’exploration pour charger des fichiers JS et CSS. Pour les sites Web énormes avec des millions de pages, cela peut être critique car cela signifierait que Google n’indexera pas certaines pages en temps opportun, car cela gaspille le budget de crawl sur un milliard de fichiers JS et CSS.
LA TAILLE DU FICHIER COMPTE AUSSI
Le problème avec le regroupement de fichiers CSS et JavaScript est qu’à mesure que votre site Web se développe, de nouvelles lignes de code sont ajoutées aux fichiers et, éventuellement, elles peuvent devenir suffisamment volumineuses pour devenir un problème de performances.
Selon la façon dont votre site Web est structuré, il peut être raisonnable de ne pas regrouper tous vos fichiers CSS et JavaScript, mais plutôt de les regrouper dans plusieurs fichiers plus petits, comme un fichier séparé pour votre blog JavaScript, un autre pour le forum JavaScript, etc.
Une autre raison pour diviser un énorme bundle JS/CSS est la mise en cache. Si vous avez tout dans un seul fichier, chaque fois que vous modifiez quelque chose dans votre code JS/CSS, les navigateurs et Google devront remettre l’ensemble en cache. Ce n’est pas génial à la fois pour l’indexation et pour l’expérience utilisateur.
En termes d’indexation, cela peut se faire de deux manières selon les technologies de mise en cache utilisées : soit vous forcez Googlebot à constamment remettre en cache votre bundle JS/CSS, soit Google peut ne pas remarquer à temps que le cache n’est plus valide et vous finirez par avec Google voyant du contenu obsolète.
En parlant d’expérience utilisateur, chaque fois que vous mettez à jour du code JS dans le bundle, les navigateurs ne peuvent plus servir de copies en cache à aucun de vos utilisateurs. Ainsi, même si vous ne modifiez que le code JS de votre blog, tous vos utilisateurs, y compris ceux qui n’ont jamais visité votre blog, devront attendre que les navigateurs chargent l’ensemble du bundle JS pour accéder à n’importe quelle page de votre site Web.
COMPRIMER ET MINIFIER CSS ET JAVASCRIPT
Pour garder vos fichiers JavaScript et CSS légers, vous devrez les compresser et les réduire. Les deux pratiques visent à réduire la taille des ressources de votre site Web en modifiant le code source, mais elles sont nettement différentes.
La compression est le processus de remplacement des chaînes répétitives dans le code source par des pointeurs vers la première instance de cette chaîne. Étant donné que tout code comporte de nombreuses parties répétitives (pensez au nombre de balises <script> que contient votre JS) et que les pointeurs utilisent moins d’espace que le code initial, la compression de fichier permet de réduire la taille du fichier jusqu’à 70%. Les navigateurs ne peuvent pas lire le code compressé, mais tant que le navigateur prend en charge la méthode de compression, il pourra décompresser le fichier avant le rendu.
L’avantage de la compression est que les développeurs n’ont pas besoin de le faire manuellement. Tout le gros du travail est fait par le serveur à condition qu’il ait été configuré pour compresser les ressources. Par exemple, pour les serveurs Apache, quelques lignes de code sont ajoutées au fichier .htaccess pour permettre la compression.
La minification est le processus de suppression des espaces blancs, des points-virgules non requis, des lignes inutiles et des commentaires du code source. En conséquence, vous obtenez le code qui n’est pas tout à fait lisible par l’homme, mais toujours valide. Les navigateurs peuvent parfaitement restituer ces codes, et ils les analyseront et les chargeront même plus rapidement que le code brut. Les développeurs Web devront s’occuper eux-mêmes de la minification, mais avec de nombreux outils dédiés, cela ne devrait pas être un problème.
En parlant de réduire la taille du fichier, la minification ne vous donnera pas les 70 % stupéfiants. Si vous avez déjà activé la compression sur votre serveur, réduire davantage vos ressources peut vous aider à réduire leur taille de quelques à 16% supplémentaires selon la façon dont vos ressources sont codées. Pour cette raison, certains développeurs Web pensent que la minification est obsolète. Cependant, plus vos fichiers CSS et JS sont petits. le meilleur. Une bonne pratique consiste donc à combiner les deux méthodes.
Utilisation de fichiers CSS et JavaScript externes
De nombreux sites Web ont tendance à utiliser des fichiers CSS et JavaScript externes hébergés sur des domaines tiers. Réutiliser un code open source qui résout parfaitement votre problème peut sembler une excellente idée. Après tout, il ne sert à rien de réinventer la roue. Il n’y a vraiment rien de mal à utiliser une solution prête à l’emploi tant qu’elle est copiée et téléchargée sur le serveur du site Web. Dans le même temps, l’utilisation de fichiers CSS et JS tiers hébergés en externe est associée à de nombreux risques.
Tout d’abord, nous parlons de risques de sécurité. Si un site Web qui héberge les fichiers que vous utilisez est piraté, vous pouvez finir par exécuter un code malveillant injecté dans le fichier JS externe. Les pirates peuvent voler les données privées de vos utilisateurs, y compris leurs mots de passe et les détails de leur carte de crédit.
Du point de vue des performances, pensez à toutes les erreurs décrites ci-dessus. Si vous n’avez pas accès au serveur sur lequel les fichiers CSS et JS sont hébergés, vous ne pourrez pas configurer la mise en cache, la compression ou le débogage des erreurs 5XX.
Si le site Web qui héberge les fichiers supprime le fichier à un moment donné et que vous ne le remarquez pas à temps, votre site Web ne fonctionnera pas correctement et vous ne pourrez pas remplacer rapidement un fichier JS ou CSS 404 par un fichier valide.
Enfin, si le site Web hébergeant des fichiers JS ou CSS définit une redirection 3XX vers un fichier (légèrement) différent, votre page Web peut ne pas ressembler et fonctionner exactement comme prévu.
Si vous utilisez des fichiers CSS et JS tiers, mon conseil est de les surveiller de près. Pourtant, une bien meilleure solution consiste à ne pas utiliser du tout CSS et JS externes.

