Comprobador de robots.txt
¿Cómo leer un archivo robots.txt?
¿Cómo utilizar nuestro Comprobador de Robots.txt?
¿Por qué es necesario un archivo robots.txt?
Los archivos robots.txt proporcionan a los motores de búsqueda información importante sobre cómo rastrear archivos y páginas web. Su función principal es regular el tráfico de los rastreadores hacia tu sitio web para evitar sobrecargar tu sitio con solicitudes.
Puedes resolver dos problemas con su ayuda:
- Primero, reducir la probabilidad de que ciertas páginas sean rastreadas, indexadas y aparezcan en los resultados de búsqueda.
- Segundo, ahorrar el presupuesto de rastreo al evitar que se indexen páginas que no deberían ser indexadas.
Sin embargo, si quieres evitar que una página u otro activo digital aparezca en la Búsqueda de Google, una opción más segura sería agregar el atributo no-index a la etiqueta meta robots.
¿Cómo asegurarse de que robots.txt funciona correctamente?
Una forma rápida y sencilla de asegurarte de que tu archivo robots.txt está funcionando correctamente es utilizar herramientas especiales
Por ejemplo, puedes validar tu archivo robots.txt utilizando nuestra herramienta: ingresa hasta 100 URLs y verás si el archivo impide que los rastreadores accedan a URLs específicas de tu sitio web.
Para detectar rápidamente errores en el archivo robots.txt, también puedes utilizar Google Search Console.
Problemas comunes de robots.txt
- El archivo no está en formato .txt. En este caso, los bots no podrán encontrar ni rastrear tu archivo robots.txt debido a la incompatibilidad de formatos.
- Robots.txt no se encuentra en el directorio raíz. El archivo debe colocarse en el directorio superior del sitio web. Si se coloca en una subcarpeta, es probable que tu archivo robots.txt no sea visible para los bots de búsqueda. Para solucionar este problema, mueve tu archivo robots.txt al directorio raíz.
En la directiva Disallow, debes especificar archivos o páginas específicas que no deberían aparecer en las SERP. Se puede utilizar con la directiva User-agent para bloquear el acceso al sitio web desde un rastreador específico.
- Disallow sin valor. Una directiva Disallow: vacía le dice a los bots que pueden visitar cualquier página del sitio web.
- Disallow sin valor. Una directiva Disallow vacía indica a los bots que pueden visitar todas las páginas del sitio web.
- Líneas en blanco en el archivo robots.txt. No dejes líneas en blanco entre directivas. De lo contrario, los bots no podrán rastrear el archivo correctamente. Se debe colocar una línea vacía en el archivo robots.txt solo antes de indicar un nuevo User-agent.
Mejores prácticas de robots.txt
- Utiliza el formato adecuado en robots.txt. Los bots consideran los nombres de carpetas y secciones como sensibles a mayúsculas y minúsculas. Por lo tanto, si el nombre de una carpeta comienza con una letra mayúscula, nombrarla con una letra minúscula desorientará al rastreador y viceversa.
- Cada directiva debe comenzar en una nueva línea. Solo puede haber un parámetro por línea.
- Está estrictamente prohibido el uso de espacios al principio de una línea, comillas o punto y coma para directivas.
- No es necesario enumerar todos los archivos que deseas bloquear de los rastreadores. Solo necesitas especificar una carpeta o directorio en la directiva Disallow, y todos los archivos de estas carpetas o directorios también quedarán bloqueados para el rastreo.
- Puedes usar expresiones regulares para crear robots.txt con instrucciones más flexibles.
- El asterisco (*) indica cualquier variación de valor.
- El signo de dólar ($) es una restricción de tipo asterisco que se aplica a las direcciones URL de un sitio web. Se utiliza para especificar el final de la ruta URL.
- Utiliza la autenticación del lado del servidor para bloquear el acceso al contenido privado. De esta manera, puedes asegurarte de que los datos importantes no sean robados.
- Utiliza un archivo robots.txt por dominio. Si necesitas establecer directrices de rastreo para diferentes sitios web, crea un archivo robots.txt separado para cada uno.
Otras formas de probar tu archivo robots.txt
Puedes analizar tu archivo robots.txt utilizando la herramienta de Google Search Console.
Este probador de robots.txt te muestra si tu archivo robots.txt está bloqueando el acceso de los rastreadores de Google a URLs específicas de tu sitio web. La herramienta no está disponible en la nueva versión de GSC, pero puedes acceder a ella haciendo clic en este enlace.
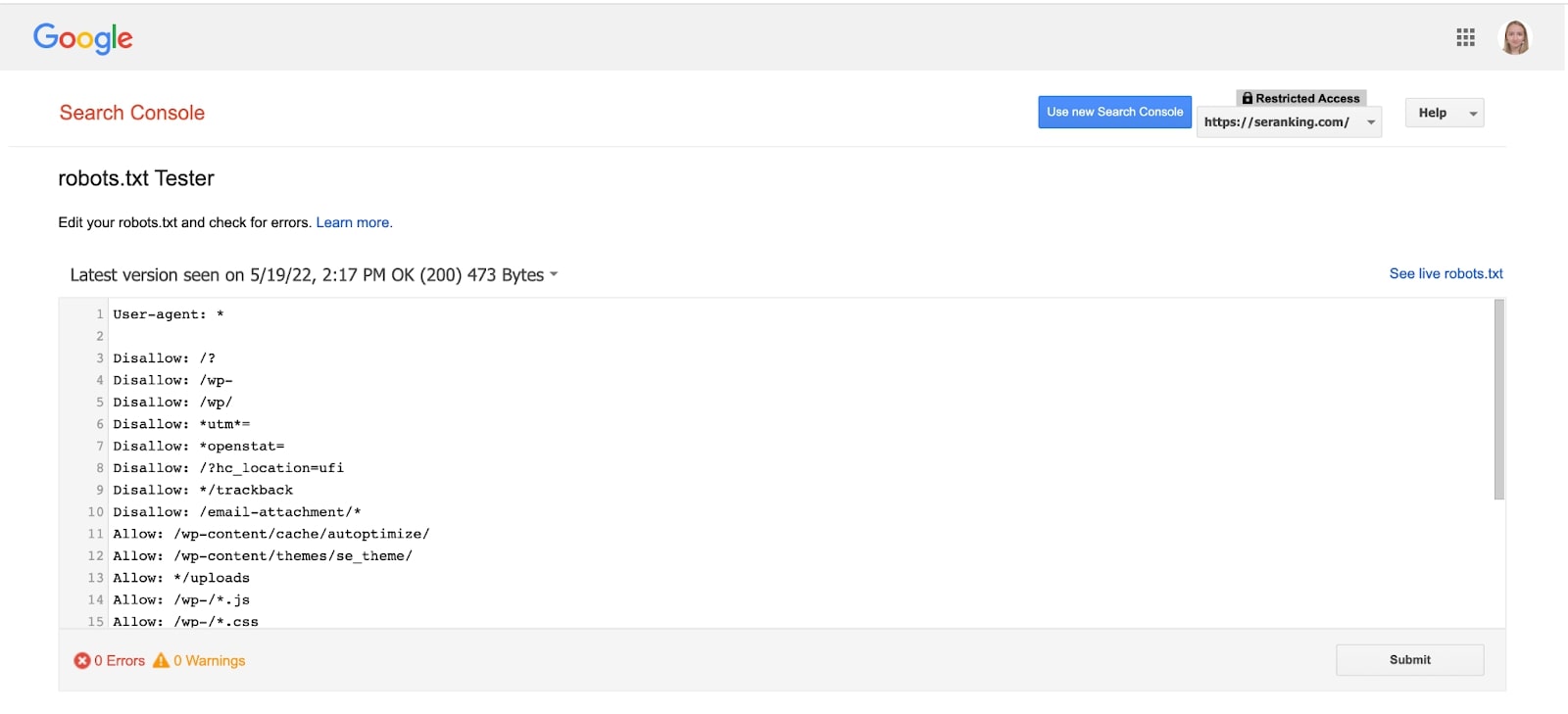
Selecciona tu dominio y la herramienta te mostrará el archivo robots.txt, sus errores y advertencias.
Ve al final de la página, donde puedes escribir la URL de una página en el cuadro de texto. Como resultado, el probador de robots.txt verificará que tu URL se haya bloqueado correctamente.

¿Qué debería haber en un archivo robots.txt?
Los archivos robots.txt contienen información que indica a los rastreadores cómo interactuar con un sitio web en particular. Comienza con una directiva User-agent que especifica el bot de búsqueda al que se aplican las reglas. Luego, debes especificar directivas que permitan y bloqueen ciertos archivos y páginas de los rastreadores. Al final de un archivo robots.txt, puedes agregar un enlace a tu mapa del sitio.
¿Pueden los bots ignorar el archivo robots.txt?
Los rastreadores siempre consultan un archivo robots.txt existente cuando visitan un sitio web. Aunque el archivo robots.txt proporciona reglas para los bots, no puede hacer cumplir las instrucciones. El archivo robots.txt en sí mismo es una lista de directivas para los rastreadores, no reglas estrictas. Por eso, en algunos casos, los bots pueden ignorar estas directivas.
¿Cómo arreglar un archivo robots.txt?
Un archivo robots.txt es un documento de texto. Puedes cambiar el archivo actual a través de un editor de texto y luego agregarlo nuevamente al directorio raíz del sitio web. Es más, muchos CMS, incluido WordPress, tienen varios complementos que permiten realizar cambios en el archivo robots.txt, y puedes hacerlo directamente desde el panel de administración.