401 vs. 403 Foutmeldingen: dit zijn de gevolgen voor je SEO
Bij het bezoeken van een website, kun je 401- of 403 HTTP-responscodes tegenkomen. Deze codes vertellen je dat je een website probeert te bezoeken zonder daartoe de autorisatie te hebben.
Maar wat is het verschil tussen deze twee HTTP-statuscodes? Op het eerste gezicht lijken ze erg op elkaar, maar dat is enkel schijn. Zodra je het verschil tussen 403 Forbidden en 401 Unauthorized begrijpt, kun je problemen rondom gebruikersauthenticatie en toegangscontroles beter diagnosticeren en oplossen.
Deze gids neemt de complexiteit van 401- en 403-foutcodes weg. Het illustreert hoe ze van elkaar verschillen en biedt gedetailleerde oplossingen voor verschillende scenario’s.
Wat is het verschil tussen foutcode 401 en 403?
De grootste uitdaging rond 401- vs. 403-foutcodes (Forbidden versus Unauthorized) ligt bij het begrijpen van de redenen voor een geweigerde toegang.
Een HTTP 401-responscode wordt door een server teruggegeven, wanneer een gebruiker toegang probeert te krijgen tot een resource zonder de benodigde authenticatiegegevens te verstrekken. Bij die authenticatiegegevens kun je denken aan de combinatie van een gebruikersnaam en wachtwoord. Het is alsof je een afgesloten deur probeert te openen zonder de juiste sleutels bij je te hebben.
Wat betekent 403 Forbidden? Een HTTP 403-statuscode nadat de gebruiker de juiste inloggegevens heeft verstrekt. Het belangrijkste verschil hier is dat de gebruiker bij een 403 foutmelding geen toegang heeft tot de gevraagde bron, als gevolg van beperkte machtigingen die aan het account gekoppeld zijn. Hoewel de gebruiker correct geauthenticeerd is, mist deze de benodigde autorisatie om daadwerkelijk verder te komen. Het is alsof je de sleutels van de deur hebt, maar te horen krijgt dat je niet naar binnen mag.
Wat is een 401-statuscode (Unauthorized) en waardoor wordt deze geactiveerd?
De HTTP 401-statuscode geeft aan dat de aanvraag van een client niet kan worden uitgevoerd, omdat deze niet over de benodigde authenticatiegegevens beschikt om toegang te krijgen tot de bron.
Wanneer de client (vaak een webbrowser) toegang probeert te krijgen tot een afgeschermde bron, vereist de website dat de client geldige authenticatiegegevens aanlevert. Afhankelijk van de website kan dit in de vorm van een gebruikersnaam en wachtwoord zijn, maar bijvoorbeeld ook in die van API-sleutels of vergelijkbare authenticatiemethoden.
Na het aanleveren ervan verwerkt de website de credentials om de legitimiteit ervan te valideren. Dit kan het kruisverwijzen van de credentials met een opgeslagen gebruikersdatabase omvatten, maar ook het contacteren van een externe authenticatieprovider of een soortgelijke validatiemethode. Bij succesvolle authenticatie retourneert de server een 200-statuscode; dit gebeurt achter de schermen.
In de gevallen waarin de authenticatie niet succesvol is, geeft de website de statuscode 401 uit.
Er zijn verschillende situaties waarin de statuscode 401 kan verschijnen:
- Verkeerde inlogmethode gebruikt: De gebruiker probeert toegang te krijgen tot de website met een onjuiste of niet-ondersteunde authenticatiemethode.
- Verlopen of verwijderde inloggegevens: Soms kunnen authenticatiegegevens en tokens na een bepaalde periode verlopen, of wordt het account van de gebruiker verwijderd. Het maakt dat een gebruiker de toegangsrechten opnieuw aan moet vragen.
- Inloggegevens ontbreken of zijn onjuist: De aanvraag is gedaan zonder authenticatiegegevens, of de opgegeven gegevens zijn onjuist.
- Er is geen autorisatie header gebruikt: Het verzoek mist de benodigde autorisatie header, die vaak van de inloggegevens van een gebruiker wordt voorzien.
- Problemen met cookies: De browser van de gebruiker accepteert geen cookies (of verwijdert ze regelmatig), waardoor de website problemen heeft met het onthouden van de inloggegevens van de gebruiker.
Wat is een 403-statuscode (Forbidden) en wat veroorzaakt deze?
De HTTP 403-responscode geeft aan dat de server het verzoek van de client heeft begrepen. De client is geauthenticeerd, maar mag de gevraagde resource niet openen. In tegenstelling tot een 401-fout, die vaak op authenticatieproblemen duidt, heeft een 403-fout betrekking op een breder probleem gerelateerd aan de autorisatie.
Neem de situatie waarbij een client toegang probeert te krijgen tot een koppeling die alleen bedoeld is voor beheerders. In dit geval reageert de server met een 403-fout. Het geeft aan dat de client niet bevoegd is om de opgegeven koppeling te openen.
Hieronder vind je enkele redenen die kunnen verklaren waarom statuscode 403 verschijnt:
- Gebruiker heeft geen toestemming: De geauthenticeerde gebruiker beschikt niet over de benodigde rechten om toegang te krijgen tot de specifieke bron.
- Fout bij aanmelden of verlopen sessie: Een tijdelijke authenticatiefout, een verlopen sessie of verdachte activiteiten die door de server worden opgemerkt, kunnen leiden tot beperkte toegang, zelfs voor geauthenticeerde gebruikers.
- Geo- of IP-gebaseerde beperkingen: Sommige servers leggen beperkingen op, op basis van IP-adressen of geografische locaties.
- Beperkingen op de toegang tot specifieke content: Er zijn websites of online diensten die de toegang tot specifieke content beperken op basis van leeftijd, locatie, afgesloten abonnement, enzovoorts.
- Beperking op toegang tot een directory: De server is zo geconfigureerd dat vermeldingen van mappen (directories) beperkt worden, bij pogingen om een directory te openen zonder een specifieke resource.
- Beperkingen door Access Control Lists (ACL’s): Sommige servers gebruiken ACL’s om specifieke machtigingen voor verschillende gebruikers in te stellen. Als een gebruiker niet in de ACL is opgenomen, beperkt de server de toegang voor hen.
Wat zijn de overeenkomsten tussen de statuscodes 403 en 401?
Het verschil tussen 401 en 403 foutcodes doorgronden kan best lastig zijn, omdat ze allebei te maken hebben met het weigeren van de toegang tot bronnen, de beveiliging ervan en de authenticatie van gebruikers. Zonder de precieze verschillen te kennen, kan het lastig zijn om erachter te komen hoe je met elk van deze foutcodes om moet gaan. Laten we eens kijken wat deze twee codes nog meer gemeen hebben.
- Zowel de 401, als 403 code valt onder de HTTP statuscodes.
- Beide fouten leiden tot een geweigerde toegang. Hoewel een 401-fout aangeeft dat er geen geldige authenticatiegegevens zijn gevonden en een 403-fout aangeeft dat de toegang verboden is, voorkomt elk van deze fouten dat de client op de gevraagde webpagina terechtkomt.
- Beide statuscodes communiceren problemen met betrekking tot de toegangscontrole en beveiliging. Ongeautoriseerde gebruikers (of geautoriseerde gebruikers met onjuiste machtigingen) krijgen geen toegang tot afgeschermde data.
- Beide fouten zijn doorgaans zichtbaar voor gebruikers en worden weergegeven in de browser.
- Zowel foutcode 401, als 403 heeft betrekking op gebruikersauthenticatie, maar in verschillende stadia. 401 verwijst naar het ontbreken van geldige authenticatiegegevens, terwijl foutcode 403 optreedt na authenticatie en aangeeft dat de benodigde machtigingen voor toegang tot een bron ontbreken.
Hoe 401- en 403-statuscodes SEO kunnen beïnvloeden
401 en 403 HTTP-fouten vormen een probleem voor SEO, mogelijk leidend tot een onvolledige of onjuiste indexering. Ook kunnen deze fouten de gebruikerservaring en betrokkenheid van gebruikers verslechteren, wat de bouncepercentages verhoogt. Laten we eens nader kijken naar de impact van deze statuscodes op je SEO-resultaten.
Zoekmachines kunnen pagina’s niet indexeren
Omdat beide HTTP-fouten wijzen op geweigerde toegang, kunnen zoekmachines de pagina’s die deze codes retourneren niet crawlen of indexeren. Dat is vanzelfsprekend oké, wanneer het niet de bedoeling is dat deze pagina’s openbaar toegankelijk worden. Als je echter van plan was om de pagina’s in zoekresultaten te laten verschijnen, zal dat als gevolg van de HTTP-fouten niet gebeuren. Dit betekent dat de algehele zichtbaarheid van je website minder goed zal zijn.
Crawl Budget wordt verspild aan afgeschermde pagina’s
Wanneer pagina’s 401 of 403 HTTP-statuscodes retourneren, besteden de bots van zoekmachines onnodig veel crawl budget in een poging om toegang te krijgen tot content die ze uiteindelijk niet in de zoekresultaten kunnen opnemen. Dit heeft invloed op de algehele efficiëntie van het crawl proces, omdat het mogelijk voorkomt dat andere belangrijke pagina’s of nieuwe content op je website grondig worden gecrawld.
Gebruikers raken gefrustreerd en verlaten pagina’s al snel weer
Net als bij de onjuiste www-versie leidt het tegenkomen van deze HTTP-fouten voor de gebruiker tot frustratie en een negatieve algehele ervaring. De website heeft hogere bouncepercentages, lagere engagement-statistieken en gebruikers zullen minder tijd op een website doorbrengen.
Rankings kunnen in de loop van de tijd verslechteren
De combinatie van een geblokkeerde indexering, verspild crawl budget en negatieve gebruikerservaringen kan leiden tot een daling in de rankings binnen de SERP’s.
Hoe je 401- en 403-HTTP-fouten op je website kunt controleren
Om 401 vs. 403 fouten onder controle te houden, is het allereerst zaak om ze actief te monitoren. Dit is vrij eenvoudig, vooral met tools als Google Search Console en SE Ranking’s Website SEO Audit tool. Je kunt ook de logbestanden analyseren of een speciale tool voor het checken van redirects gebruiken. Meer hierover hieronder.
Foutcodes 401 en 403 identificeren met Google Search Console
Google Search Console helpt je problemen te identificeren die gerelateerd zijn aan 401 en 403 HTTP-responscodes door een gedetailleerd rapport te verstrekken over gevonden crawlfouten. Deze fouten duiden op gevallen, waarbij Googlebot moeite had met het openen van bepaalde pagina’s op je website.
Om problemen met 401- en 403-statuscodes binnen Google Search Console te vinden, ga je naar het rapport Indexering en open je het tabblad Pagina’s. Scrol omlaag naar het gedeelte Waarom pagina’s niet worden geïndexeerd om de lijst met redenen te bekijken. Als je website geblokkeerde pagina’s bevat, zie je Geblokkeerd vanwege ongeautoriseerde aanvraag (401) of Geblokkeerd vanwege verboden toegang (403).
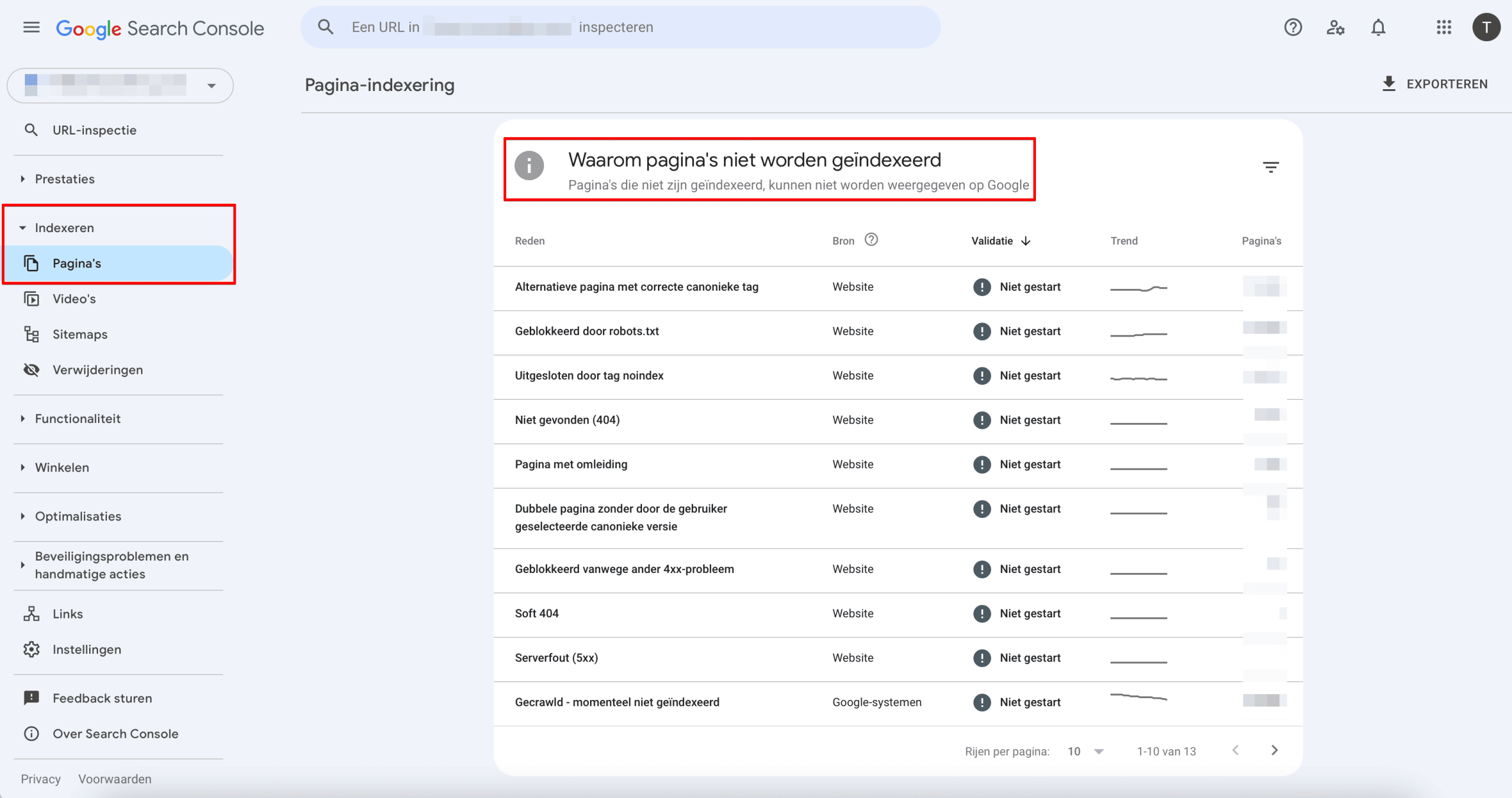
Als je op een reden klikt, krijg je een gedetailleerd rapport te zien over de geblokkeerde URL’s.
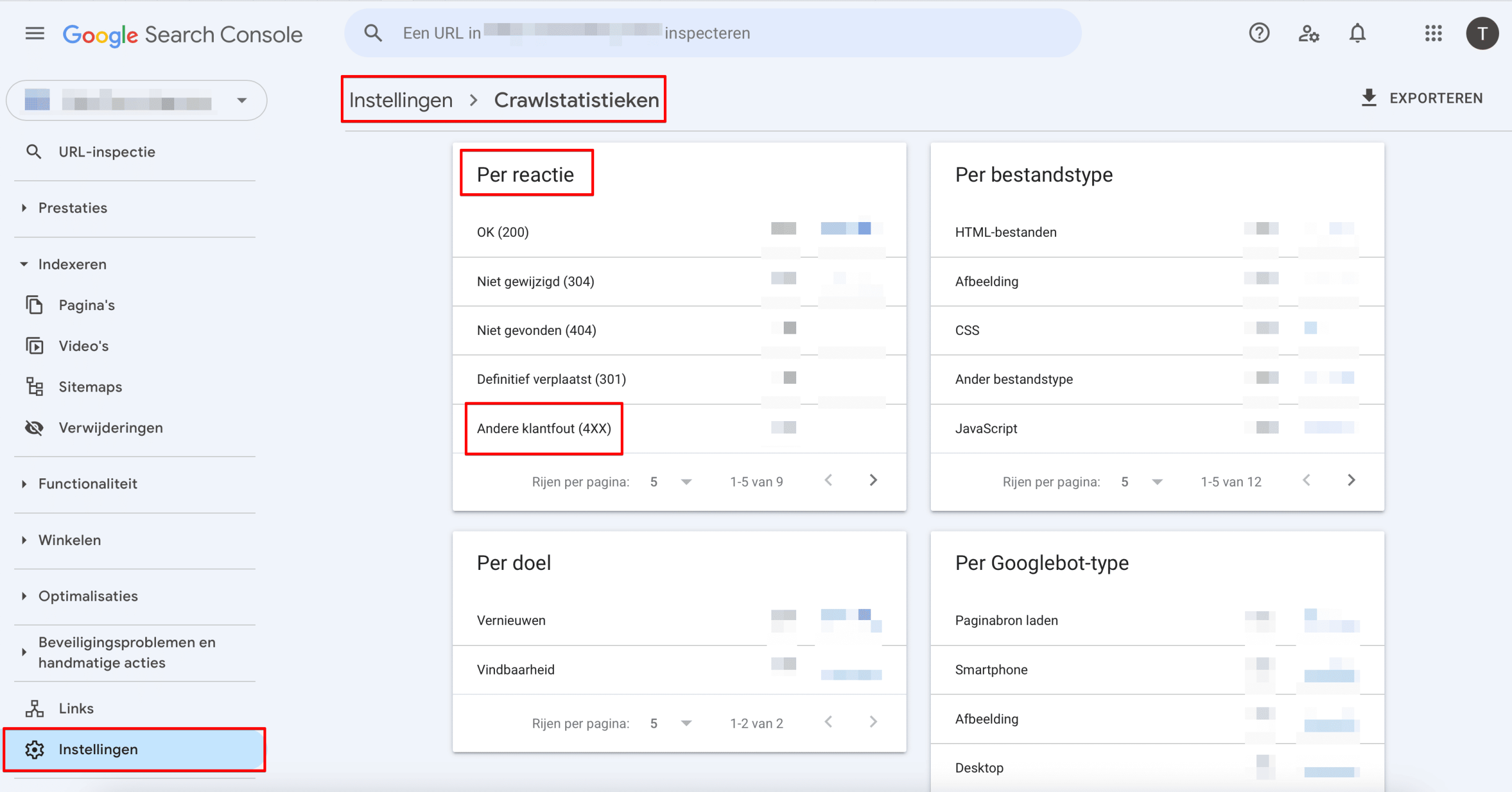
Een andere optie is om naar Instellingen te gaan en het rapport Crawlstatistieken te openen.
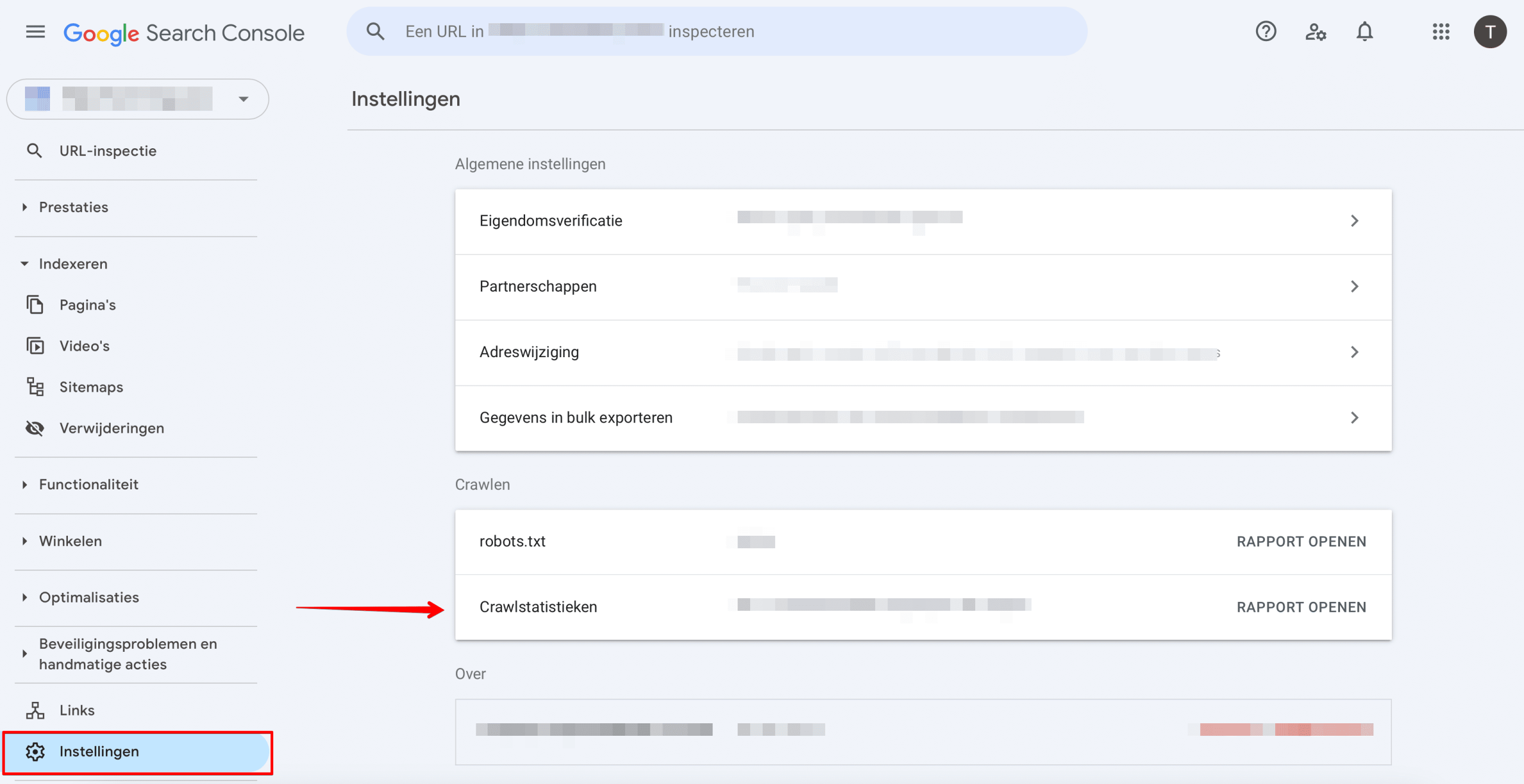
Scroll naar beneden, naar het gedeelte Per reactie en controleer op Ongeautoriseerd (401/407) en Andere klantfout (4XX).
Foutcodes 401 en 403 identificeren met de Website Audit Tool
Met de Website Audit-tool van SE Ranking is het identificeren van Forbidden en Unauthorized statuscodes een fluitje van een cent. Het helpt je bij technische audits, die de algehele gezondheid van je website in kaart brengen. Het detecteert onder meer HTTP-fouten, indexeringsproblemen, problemen met redirects en nog veel meer.
Om 401 en 403 HTTP fouten te vinden, start je een website check met SE Ranking. De tool is beschikbaar als project en als stand-alone oplossing. Zodra de analyse is voltooid, ga je naar het Issue rapport binnen de Website Audit tool.
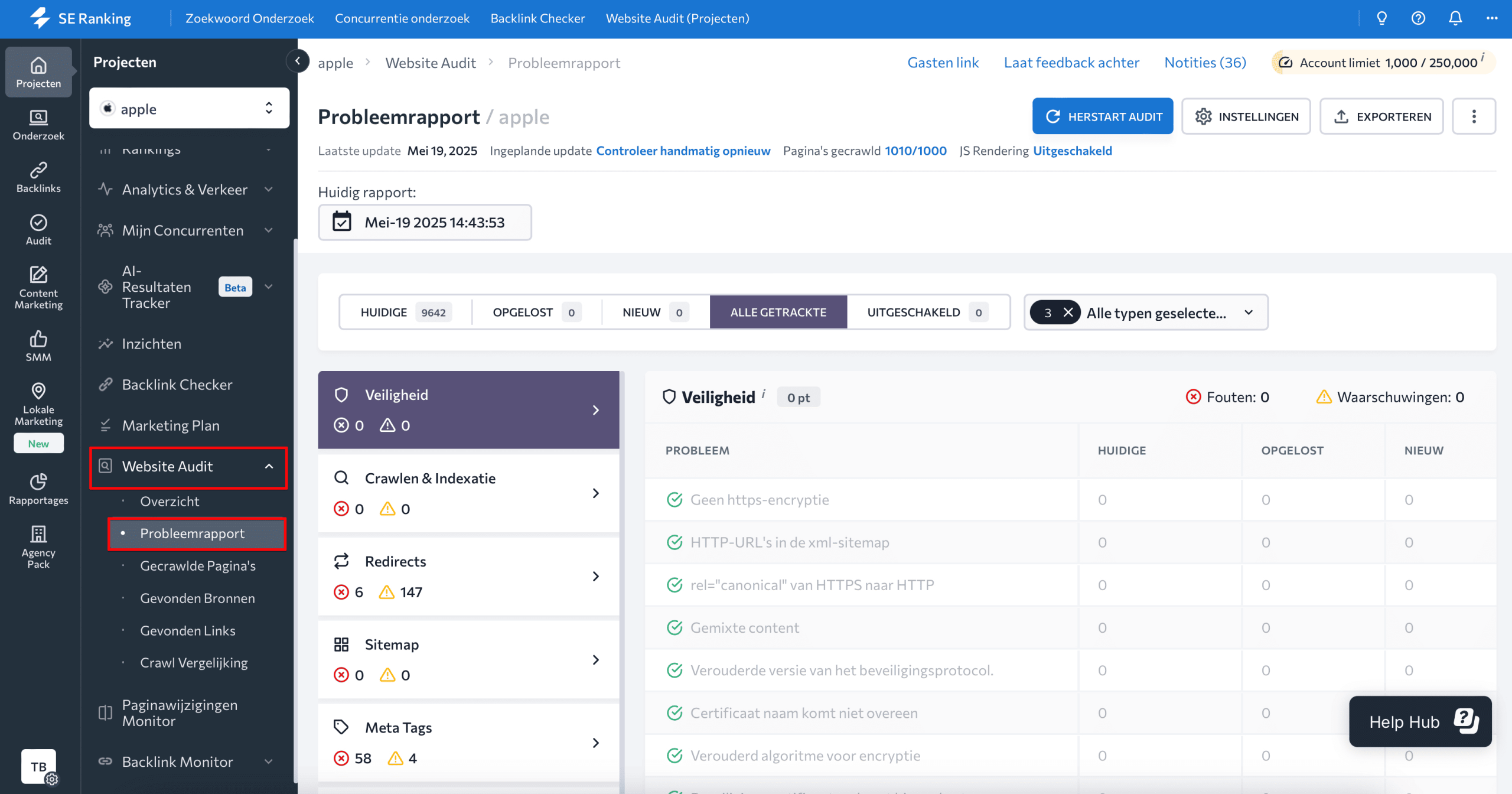
Ga naar het gedeelte HTTP-statuscode en controleer alle 4xx-gerelateerde problemen, waaronder:
- 4XX pagina’s in XML sitemap
- 4XX HTTP Status Codes
- Canonieke URL’s met een 4XX-statuscode
- Externe links naar 4XX, etc.
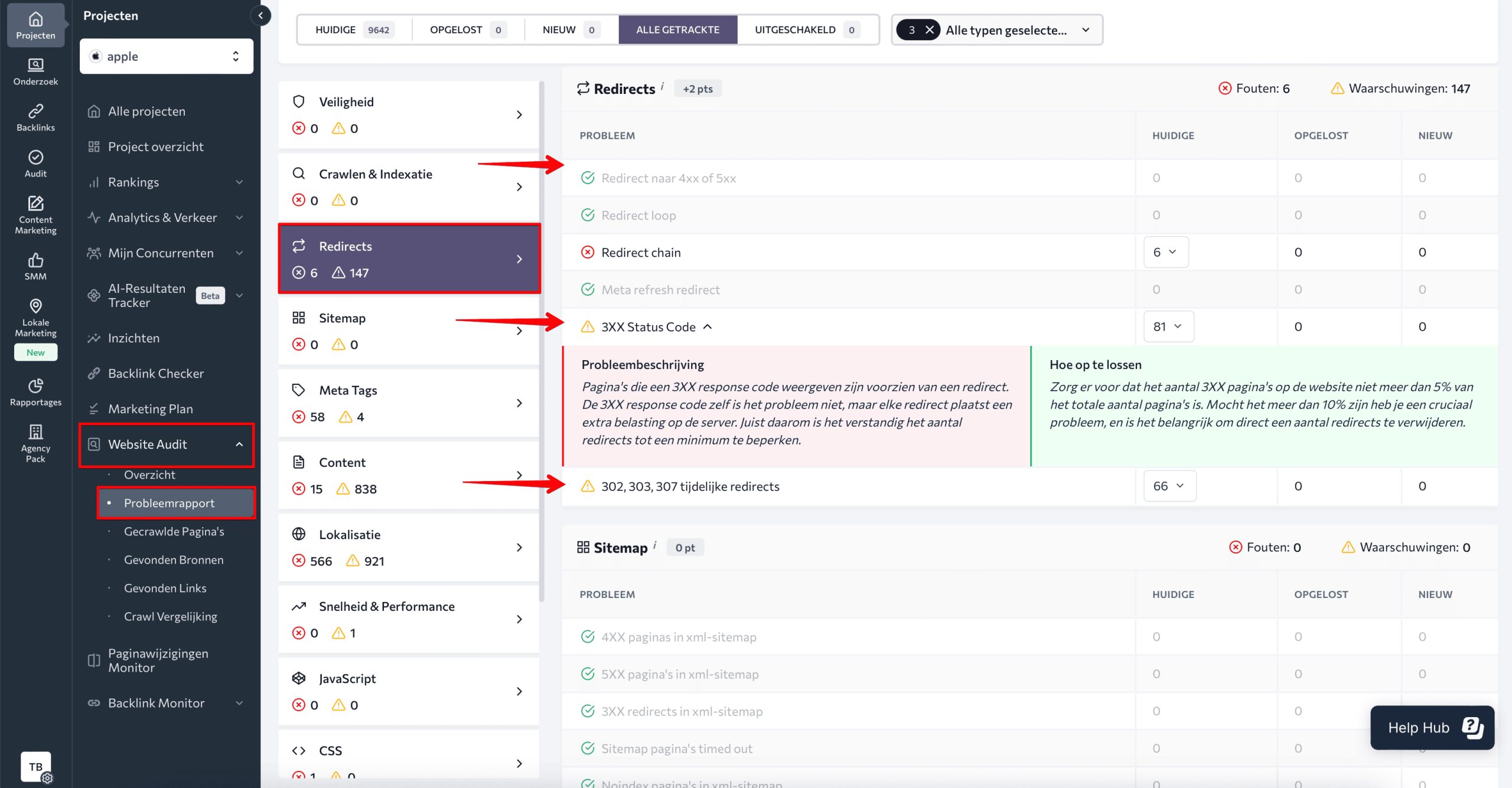
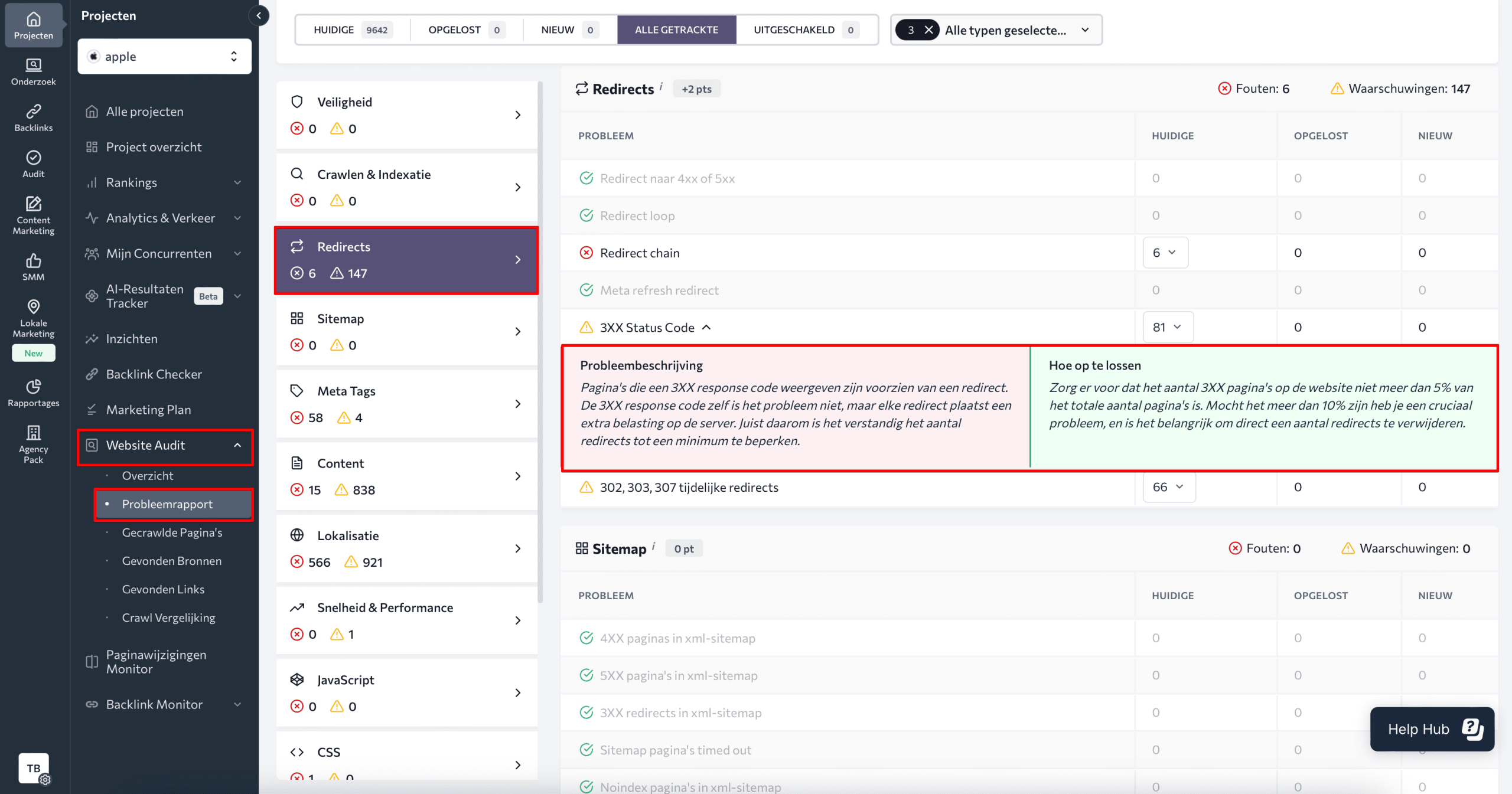
Klik op het probleem om een beschrijving ervan te zien, met tips om het op te lossen.
Je kunt ook het rapport Gecrawlde pagina’s gebruiken om alle pagina’s op je website te bekijken die door SE Ranking zijn gevonden, en filters gebruiken om de pagina’s te sorteren op een 4xx-statuscode. Klik op Filters, kies HTTP-statuscode in Issues, selecteer de gewenste fout en Pas filters toe.
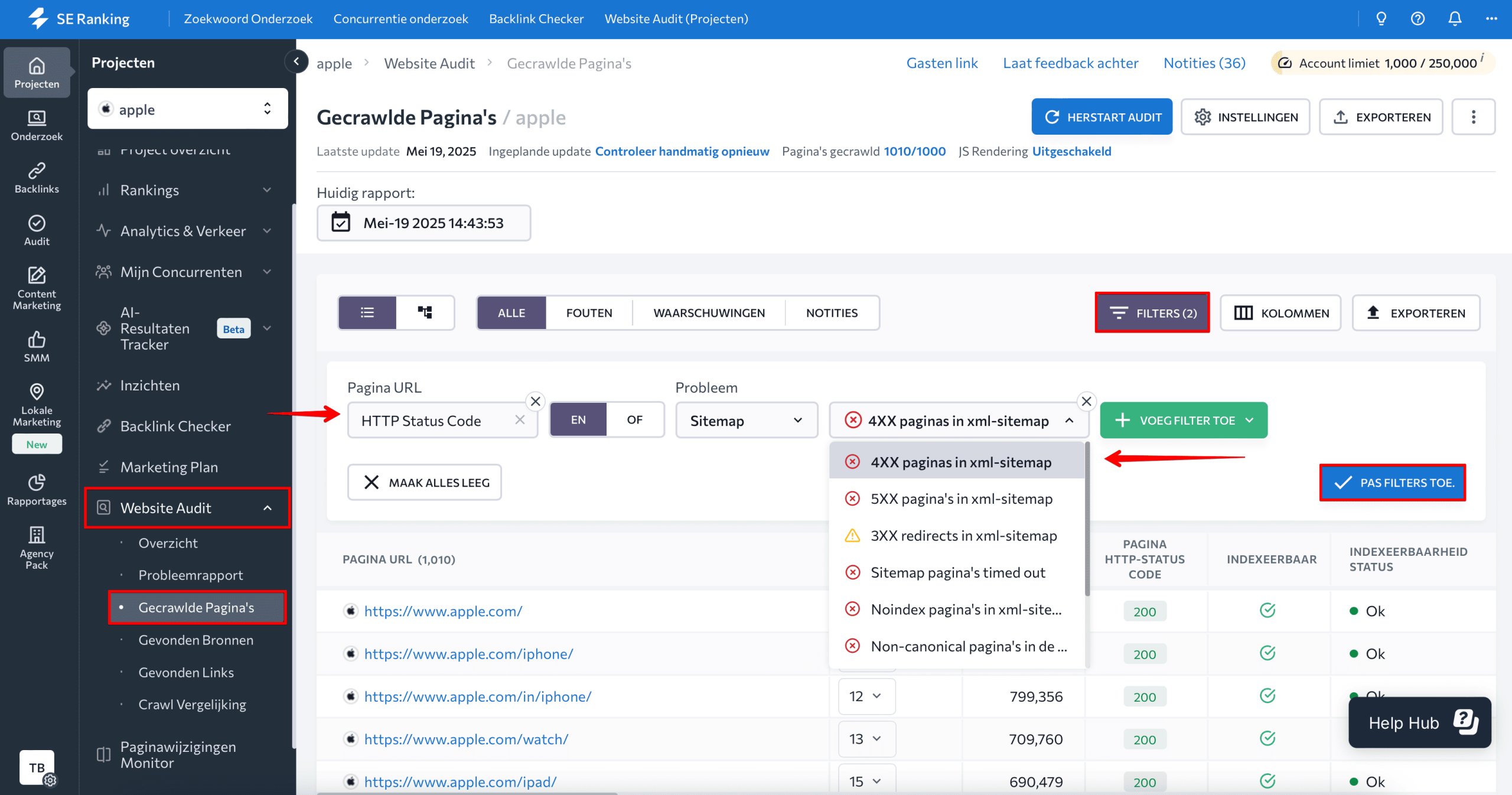
Als je meerdere controles van websites hebt uitgevoerd, kun je de Crawl Vergelijking gebruiken om te zien hoe het aantal en type 4xx HTTP-fouten in de loop van de tijd is veranderd.
Identificeren van foutcodes 401 en 403 met een analyse van het logbestand
Door webservers gegenereerde logbestanden bevatten waardevolle informatie over elk verzoek dat aan de server wordt gedaan, inclusief de details over de geretourneerde statuscodes.
Dit zijn de stappen voor het monitoren van HTTP-fouten met behulp van een analyse van het logbestand:
- Toegangslogboek ophalen: Haal het logboek over toegang (Access logs) op van je webserver. Deze logboeken bevatten gedetailleerde records van elk verzoek dat aan de server is gedaan en de geretourneerde responscodes.
- Filteren op statuscode: Gebruik een analysetool of script om de records in je logs te filteren op HTTP-statuscodes 401 en 403.
- Timestamp analyse: Bekijk de tijdstempels (timestamps) die aan meldingen gekoppeld zijn, om te bepalen wanneer de fouten zich voor het eerst voordeden en inzicht te krijgen in de mogelijke oorzaken ervan.
- Onderzoek IP-adres en user agent: Onderzoek de IP-adressen en user agents die gekoppeld zijn aan de verzoeken die resulteerden in 401- of 403-fouten. Dit helpt bij het identificeren van de bron achter toegangspogingen. Gaat het om legitieme gebruikers, bots of potentiële bedreigingen?
- URL’s en referrers: Analyseer de URL’s en referrers in de logs om de pagina’s of bronnen te identificeren die de 401- of 403-fouten hebben geactiveerd. Dit geeft de locatie van toegangsproblemen aan.
- User Authentication Insights (401): Bekijk bij 401-foutmeldingen de logs voor verdere details over de mislukte gebruikersauthenticatie. Zoek naar patronen zoals mislukte inlogpogingen, onjuiste referenties of verlopen sessies.
- Forbidden Access Insights (403): Analyseer bij 403-foutmeldingen de logs om de redenen voor een geweigerde toegang te bepalen. Onderzoek directory-machtigingen, toegangscontroles of andere configuraties die de toegang tot bepaalde bronnen kunnen beperken.
“Geblokkeerd vanwege ongeautoriseerde aanvraag (401)” in GSC: Hoe 401-fouten te verhelpen
Voordat je de pagina met de melding ‘Geblokkeerd door ongeautoriseerde aanvraag (401)’ repareert, is het zaak om te beslissen of je wilt dat deze 401-pagina wordt geïndexeerd. Niet alle pagina’s op je website hoeven geïndexeerd te worden (d.w.z. pagina’s specifiek voor ingelogde gebruikers). Filter pagina’s op de pagina’s die in je sitemap staan om te zien welke wel en niet geïndexeerd kunnen worden. Ook kun je een on-page SEO check uitvoeren als je wilt zien of een specifieke URL geïndexeerd is.
Als je besluit om de 401-pagina’s te indexeren, pas dan de instellingen van de server aan zodat Googlebot toegang heeft tot deze URL’s en deze mogelijk anders behandeld dan de browsers van gebruikers doen. Pas echter op, het aanbieden van afwijkende content aan Google kan leiden tot cloaking penalty’s. Wees dus voorzichtig. Maak gebruik van gestructureerde data op pagina’s met een betaalmuur en volg de richtlijnen van Google voor het toevoegen van geschikte data op pagina’s voor gebruikers met een abonnement.
Als je besluit dat de 401-pagina’s niet geïndexeerd hoeven te worden, kun je deze pagina’s in het robots.txt-bestand opnemen en daar afschermen voor indexering. Dit optimaliseert je crawl budget.
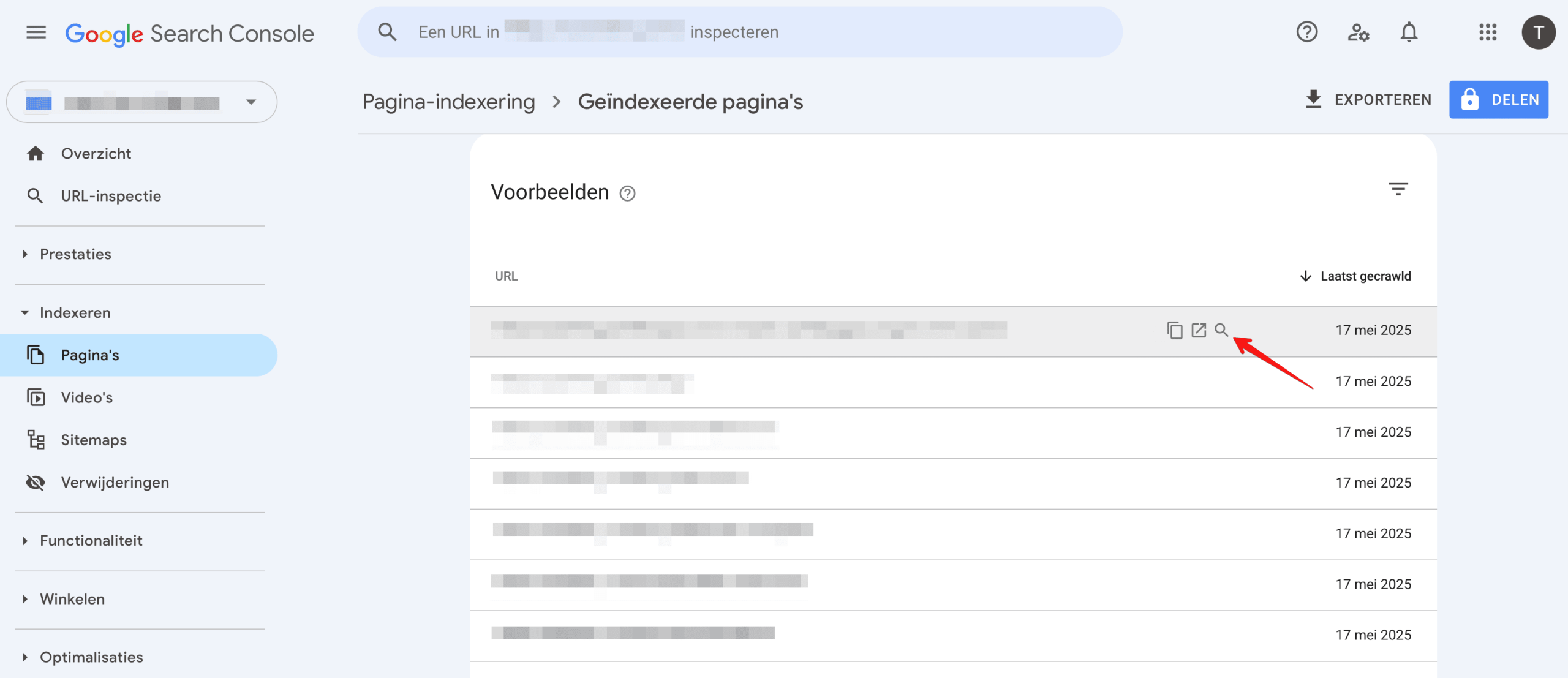
Het is daarbij aan te raden om onnodige verwijzingen naar een 401-pagina te bewerken of te verwijderen van de verwijzende pagina’s. Hierdoor blijven de interne links van je website veilig en gezond. Gebruik de URL-Inspectie Tool in GSC om de links te identificeren die de crawler naar een specifieke 401-pagina leiden.
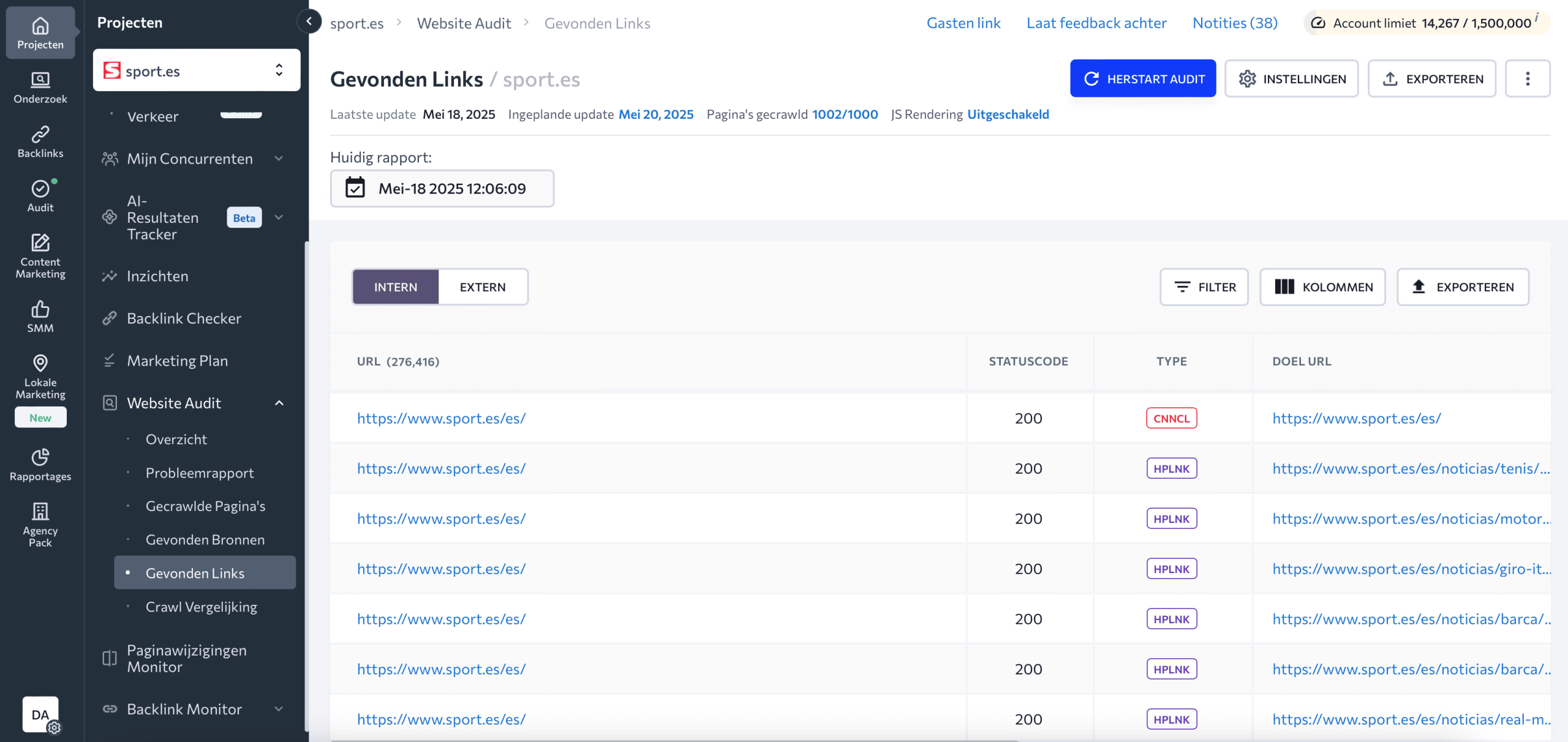
Je kunt ook de Website Audit-tool van SE Ranking gebruiken om de interne en externe links te bekijken die naar de pagina’s op je website verwijzen. Ga naar het rapport Gevonden links om de tabel met link-URL’s, hun statuscodes en pagina’s waar die links zijn gevonden te bekijken. Gebruik filters om het zoeken te vergemakkelijken.
“Geblokkeerd vanwege verboden toegang (403)” in GSC: Hoe error 403 oplossen?
Net als bij de 401-fout is het zaak om te beslissen of het de moeite waard is om het probleem “Geblokkeerd vanwege verboden toegang (403)” überhaupt op te lossen. Wil je 403-pagina’s aan Googlebot tonen?
Als je dat niet doet, is het verstandig om ze uit te sluiten voor crawling door bots. Dat doe je door een robots.txt-regel te gebruiken. Dit voorkomt dat de Googlebot zijn crawl budget verspilt aan pagina’s met beperkte toegang. Je kunt de volgende instructies gebruiken om toegang tot een specifieke map of URL op je website te weigeren:
- Disallow: /folder-name/
- Disallow: /page-url.html
Als je pagina’s hebt die je wilt laten indexeren door zoekmachines, maar die je wilt beperken voor niet-ingelogde gebruikers (zoals content achter een betaalmuur), kun je uitsluitend Googlebot toegang verlenen. Pas hier de serverinstellingen voor aan, zonder deze content te blokkeren met een inlogmuur. Houd er rekening mee dat het weergeven van andere content aan Googlebot dan aan gebruikers de toevoeging van gestructureerde data vereist. Dit informeert de crawler over content achter een betaalmuur.
Het kan voorkomen dat bepaalde pagina’s op je website openbaar toegankelijk horen te zijn, maar om verschillende redenen momenteel een 403-statuscode retourneren aan Googlebot.
Laten we eens kijken naar de redenen hiervoor en hoe we deze kunnen oplossen:
- Fouten in je .htaccess-bestand: Schakel het bestaande .htaccess-bestand uit en genereer een nieuw bestand. Vervolgens kun je jouw pagina’s crawlen met een Googlebot. Deze bekijkt je website vanuit zijn perspectief om te verifiëren of het probleem is opgelost.
- Bestandsrechten: Controleer of je de rechten voor de bestanden die je wilt laten crawlen door zoekmachines correct hebt ingesteld. Als dat niet het geval is, voorzie je ze alsnog van de benodigde rechten.
- Niet-compatibele plug-in: Als je een CMS zoals WordPress gebruikt, kun je tegen problemen met plug-ins aanlopen. Werk ze bij en controleer of ze compatibel zijn met je huidige versie van WordPress. Deactiveer ze als dat niet het geval is.
- Verkeerd IP-adres: Controleer je Address-record (A-record), dat wordt gebruikt om een domein of subdomein aan een specifiek IPv4-adres te koppelen.
- Malware infectie: Controleer je websites op malware infecties en verwijder deze indien aanwezig.
- Problemen met hosting: Als de bovenstaande suggesties niet helpen, kun je het beste contact opnemen met je hostingprovider. Er kan een probleem aan hun kant zijn.
Conclusies
Het begrijpen van de nuances rond 401- versus 403-fouten is cruciaal voor het onderhouden van een gezonde en goed geoptimaliseerde website. Deze HTTP-statuscodes kunnen aanzienlijke gevolgen hebben voor je SEO, en hebben daarmee invloed op de indexering, het gebruik van crawl budget, de gebruikerservaring en mogelijke dalingen in je rankings.

