Quelle est la différence entre une erreur 401 vs erreur 403 ?
Lorsque vous essayez d’accéder à un site Web, il est possible de tomber sur une erreur 401 ou 403. Ces codes de réponse HTTP signalent un accès refusé en raison de droits insuffisants ou d’identifiants manquants.
Alors, quelle est la différence entre ces deux codes de statut HTTP ? Ils se ressemblent à première vue, mais leur fonction diffère nettement. Dès que la distinction entre les erreurs 403 Forbidden vs 401 Unauthorized est claire, il devient plus simple d’analyser et de corriger les problèmes liés à l’authentification et aux droits d’accès.
Ce guide vous aide à mieux comprendre les erreurs 401 et 403, en expliquant leurs différences et en proposant des solutions adaptées à chaque situation.
Quelle est la différence entre les codes d’erreur 401 et 403 ?
Tout d’abord, lorsqu’on compare les erreurs 401 vs 403, il est essentiel de comprendre la raison précise du refus d’accès.
Le code de réponse HTTP 401 s’affiche lorsqu’un utilisateur tente d’accéder à une ressource sans fournir les identifiants requis, comme un nom d’utilisateur et un mot de passe valide. C’est un peu comme essayer d’ouvrir une porte verrouillée sans avoir les bonnes clés.
Une erreur HTTP 403, à son tour, survient lorsque l’utilisateur est correctement authentifié, mais ne dispose pas des droits nécessaires pour accéder à la ressource demandée. Même avec des identifiants valides, l’accès reste bloqué. C’est un peu comme si l’on vous laissait ouvrir la porte, mais sans autorisation d’entrer.
Qu’est-ce qu’une erreur 401 Unauthorized et quand survient-elle ?
Le code HTTP 401 signifie que la requête envoyée par le client ne comporte pas les informations d’authentification nécessaires pour accéder à la ressource ciblée.

Lorsqu’un client (généralement un navigateur Web) tente d’accéder à une ressource protégée, le site exige une authentification valide. Selon les cas, cela peut prendre la forme d’un identifiant et d’un mot de passe, d’une clé API ou d’autres types d’identification.
Après l’identification, le site procède à la validation. Cette étape peut passer par une base de données interne, un fournisseur d’authentification externe ou tout autre système de contrôle. Si l’authentification réussit, le serveur renvoie automatiquement un code 200.
Mais si l’authentification échoue, le site renvoie un code d’erreur 401.
Ce code peut apparaître dans plusieurs situations, notamment lorsque :
- Méthode d’authentification non prise en charge : un utilisateur tente d’accéder au site en utilisant un mode de connexion inadapté ou non pris en charge par le serveur.
- Identifiants expirés ou compte désactivé : dans certains cas, les identifiants ou jetons d’accès expirent automatiquement, ou bien l’accès de l’utilisateur est révoqué manuellement. Un renouvellement des droits d’accès devient alors nécessaire.
- Identifiants manquants ou incorrects : la requête ne contient pas d’informations d’authentification, ou bien les identifiants fournis sont incorrects.
- Aucun en-tête d’autorisation utilisé : la requête ne contient pas l’en-tête d’authentification requis, qui transmet généralement les identifiants de l’utilisateur.
- Cookies désactivés ou supprimés : lorsque le navigateur ne permet pas de stocker les cookies, les sessions d’authentification ne sont pas mémorisées correctement, ce qui entraîne des erreurs d’accès.
Qu’est-ce qu’une erreur 403 Forbidden et quand survient-elle ?
Le code de réponse HTTP 403 signifie que le serveur a bien compris la requête du client. L’utilisateur est authentifié, mais n’a pas l’autorisation d’accéder à la ressource demandée. Contrairement à une erreur 401 http, qui signale un problème d’authentification, l’erreur 403 renvoie à une restriction liée aux droits d’accès.

Par exemple, si un utilisateur tente d’accéder à un lien réservé aux administrateurs, le serveur renverra une erreur 403 pour indiquer que l’accès à cette ressource est interdit pour lui.
Voici quelques raisons les plus fréquentes d’une erreur 403 http :
- Accès non autorisé : l’utilisateur est authentifié, mais ne dispose pas des autorisations nécessaires pour consulter la ressource demandée.
- Échec de connexion ou session expirée : une authentification temporairement invalide, une session expirée ou une activité suspecte peuvent entraîner un refus d’accès, même pour un utilisateur déjà authentifié.
- Restrictions géographiques ou par adresse IP : certains serveurs bloquent l’accès en fonction de la localisation géographique de l’utilisateur ou de son adresse IP.
- Restrictions d’accès au contenu : certains sites limitent l’accès à certaines pages en fonction de critères comme l’âge, la localisation ou le statut de membre.
- Restriction d’accès au répertoire : le serveur bloque l’accès lorsqu’un utilisateur tente d’ouvrir un répertoire sans fichier précis, notamment si l’affichage du contenu du répertoire n’est pas autorisé.
- Restrictions basées sur les ACL : certains serveurs utilisent des listes de contrôle d’accès (ACL) pour définir des autorisations spécifiques. Si un utilisateur n’est pas inclus dans la liste autorisée, le serveur renvoie une erreur 403.
Quels sont les points communs entre les codes d’erreur 401 et 403 ?
Les erreurs 401 et 403 peuvent prêter à confusion, car les deux renvoient à un refus d’accès et à des problématiques liées à la sécurité et à l’authentification. Cette confusion complique aussi la manière de les traiter. Voyons ce que ces deux codes ont en commun.
- Les erreurs 401 et 403 sont toutes deux des codes de statut HTTP.
- Les erreurs 401 et 403 entraînent toutes deux un refus d’accès. L’erreur 401 indique que les identifiants sont manquants ou invalides, tandis que l’erreur 403 reflète un refus d’autorisation. Mais dans les deux cas, l’utilisateur ne peut pas accéder à la page demandée.
- Les codes 401 et 403 renvoient tous deux à des problématiques de sécurité et de contrôle d’accès. Lorsqu’un utilisateur n’est pas authentifié ou ne dispose pas des autorisations adéquates, l’accès aux données protégées est bloqué.
- Ces deux erreurs sont renvoyées par le serveur et s’affichent dans le navigateur pour l’utilisateur.
- Les deux codes d’erreur traitent l’authentification, mais à des étapes différentes. Le code 401 signale l’absence d’identifiants valides, tandis que l’erreur 403 survient après authentification, lorsque l’utilisateur ne dispose pas des autorisations nécessaires pour accéder à la ressource.
Quel est l’impact des erreurs 401 et 403 sur le SEO ?
Les erreurs HTTP 401 et 403 sont des problèmes SEO qui peuvent entraîner une indexation incomplète ou erronée des pages. Elles dégradent également l’expérience utilisateur, et peuvent augmenter le taux de rebond. Examinons plus en détail leur impact sur la performance SEO.
Les moteurs de recherche ne peuvent pas indexer les pages
Puisque les erreurs HTTP 401 et 403 signalent un refus d’accès, les moteurs de recherche ne peuvent ni explorer ni indexer les pages concernées. Si ces pages ne sont pas destinées à être publiques, cela n’aura pas d’impact. Cependant, si vous comptiez les faire apparaître dans les résultats de recherche, elles seront absentes, ce qui réduit la visibilité globale de votre site.
Consommation inefficace du budget de crawl
Les erreurs 401 et 403 détournent une partie du budget de crawl vers des pages inaccessibles. Comme ces pages ne peuvent pas être indexées, ce processus réduit l’efficacité globale de l’exploration et limite la fréquence de crawl des pages importantes ou des nouveaux contenus.
Une mauvaise expérience utilisateur pousse les visiteurs à partir
Lorsqu’un utilisateur tombe sur une erreur 401 ou 403, cela peut le décourager et l’amener à quitter le site. Le site enregistre alors un taux de rebond plus élevé, une baisse de l’engagement et un temps de visite réduit.
Les positions peuvent baisser avec le temps
L’impact combiné d’une mauvaise indexation, d’un gaspillage du budget de crawl et d’une UX négative peut provoquer une baisse des positions avec le temps.
Comment suivre les erreurs HTTP 401 et 403 sur votre site Web
Le suivi proactif des erreurs 401 et 403 est essentiel pour préserver le SEO de votre site. C’est d’ailleurs assez simple à mettre en place grâce à des outils comme Google Search Console ou l’audit d’un site Web de SE Ranking. L’analyse des fichiers journaux peut également fournir des informations utiles. Plus de détails ci-dessous.
Identifier les erreurs 401 et 403 avec Google Search Console
Google Search Console permet d’identifier les erreurs liées aux codes HTTP 401 et 403 grâce à ses rapports détaillés sur les erreurs de crawl. Ces rapports signalent les pages que Googlebot n’a pas pu explorer en raison de restrictions d’accès.
Pour identifier les erreurs 401 et 403 dans Google Search Console, accédez au rapport sur l’indexation, puis ouvrez l’onglet Pages. Faites défiler jusqu’à la section intitulée Pourquoi les pages ne sont pas indexées pour consulter les différentes causes de blocage. Si certaines pages sont concernées, vous verrez des messages du type Bloquée en raison d’une requête non autorisée (401) ou Bloquée en raison d’un accès interdit (403).

Cliquez sur la raison du blocage pour accéder à un rapport complet indiquant les URL concernées.
Une autre option consiste à accéder aux Paramètres, puis à ouvrir le rapport Statistiques sur l’exploration.

Faites défiler jusqu’à la section Par code de réponse, et recherchez les mentions Non autorisée (401/407) et Autres erreurs côté client (4XX).

Identifier les erreurs 401 et 403 avec l’outil d’audit de site Web
L’outil d’audit technique de SE Ranking simplifie l’identification des erreurs 401 (non autorisé) et 403 (accès interdit). Il permet d’évaluer la santé technique globale de votre site, et détecter les erreurs HTTP, les problèmes d’indexation, de redirections, etc.
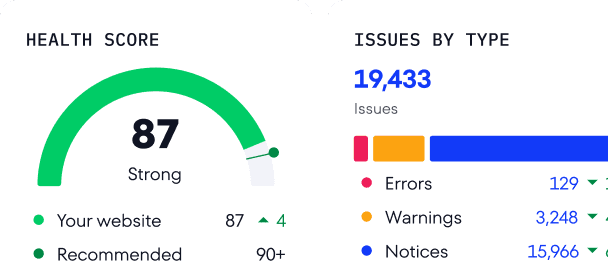
Pour détecter les erreurs HTTP 401 et 403, lancez une analyse de site avec SE Ranking. L’outil est disponible à la fois dans un projet ou en tant que solution indépendante. Une fois l’audit terminé, accédez au Rapport d’erreurs dans la section Audit de site.
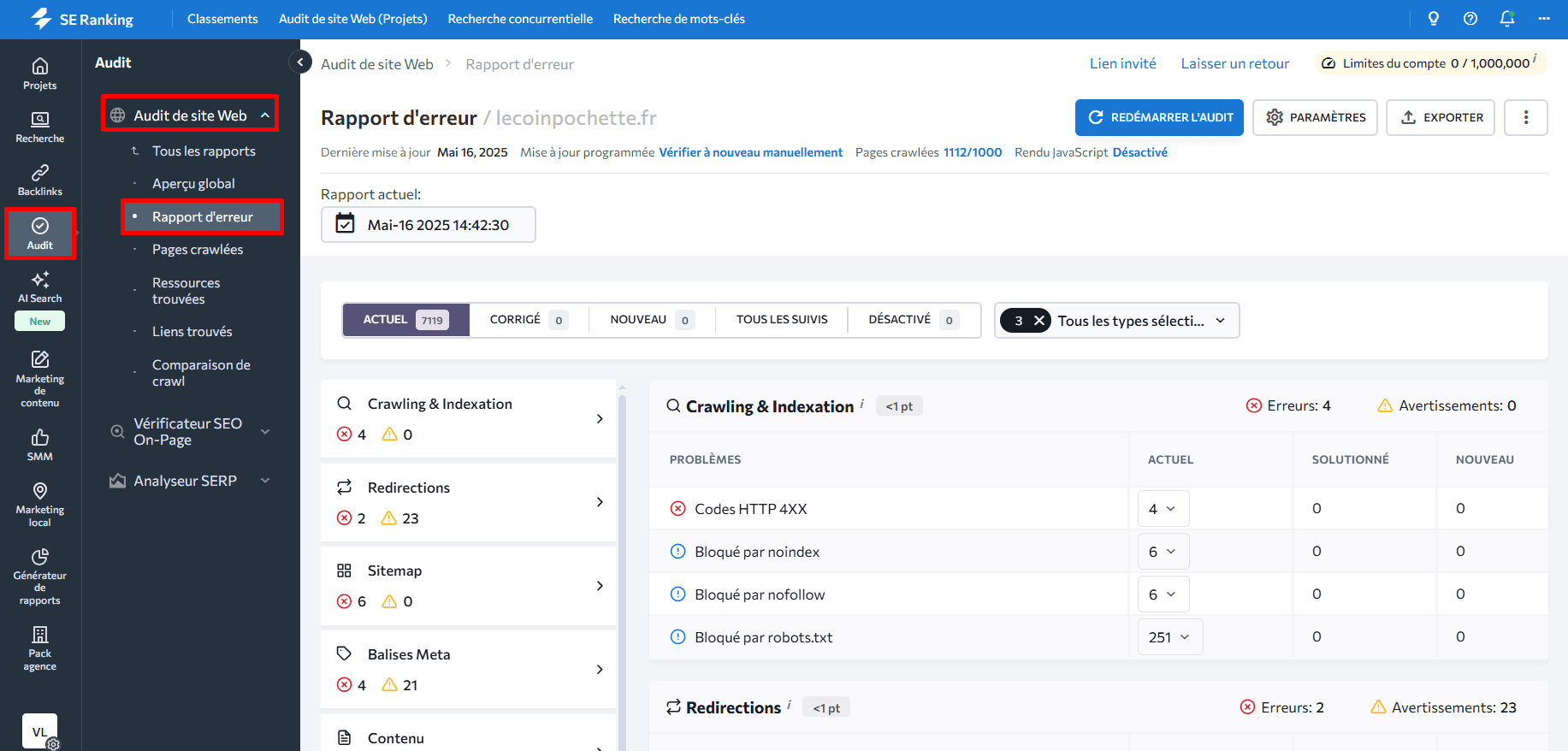
Accédez également à la section Codes de statut HTTP et examinez toutes les erreurs liées aux codes 4xx, y compris :
- Pages 4XX dans le sitemap XML
- Codes de réponse HTTP 4XX
- URLs canoniques renvoyant un code 4XX
- Liens externes vers des pages en 4XX
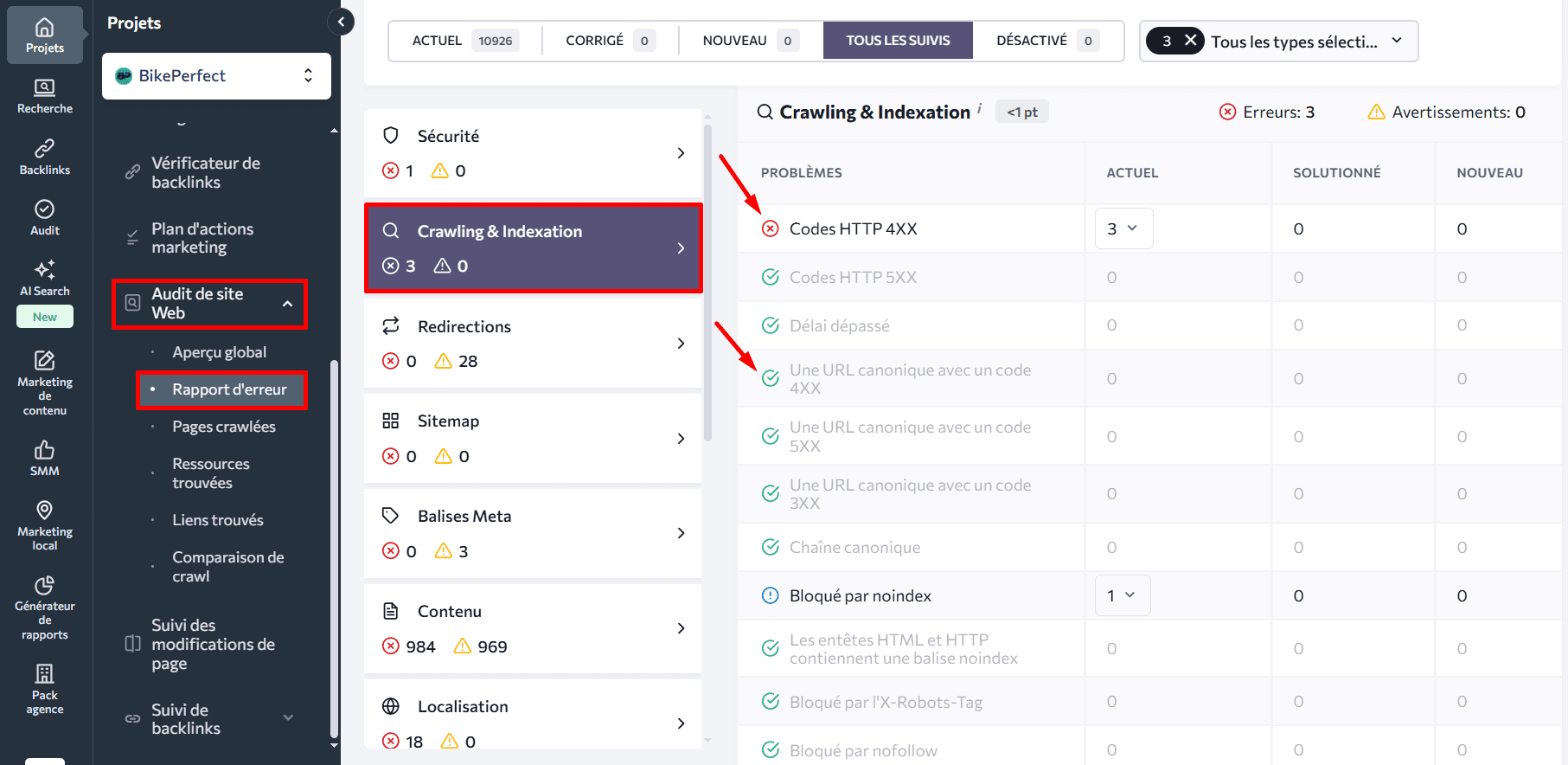
Cliquez sur le problème pour afficher sa description ainsi que des conseils pour le corriger.
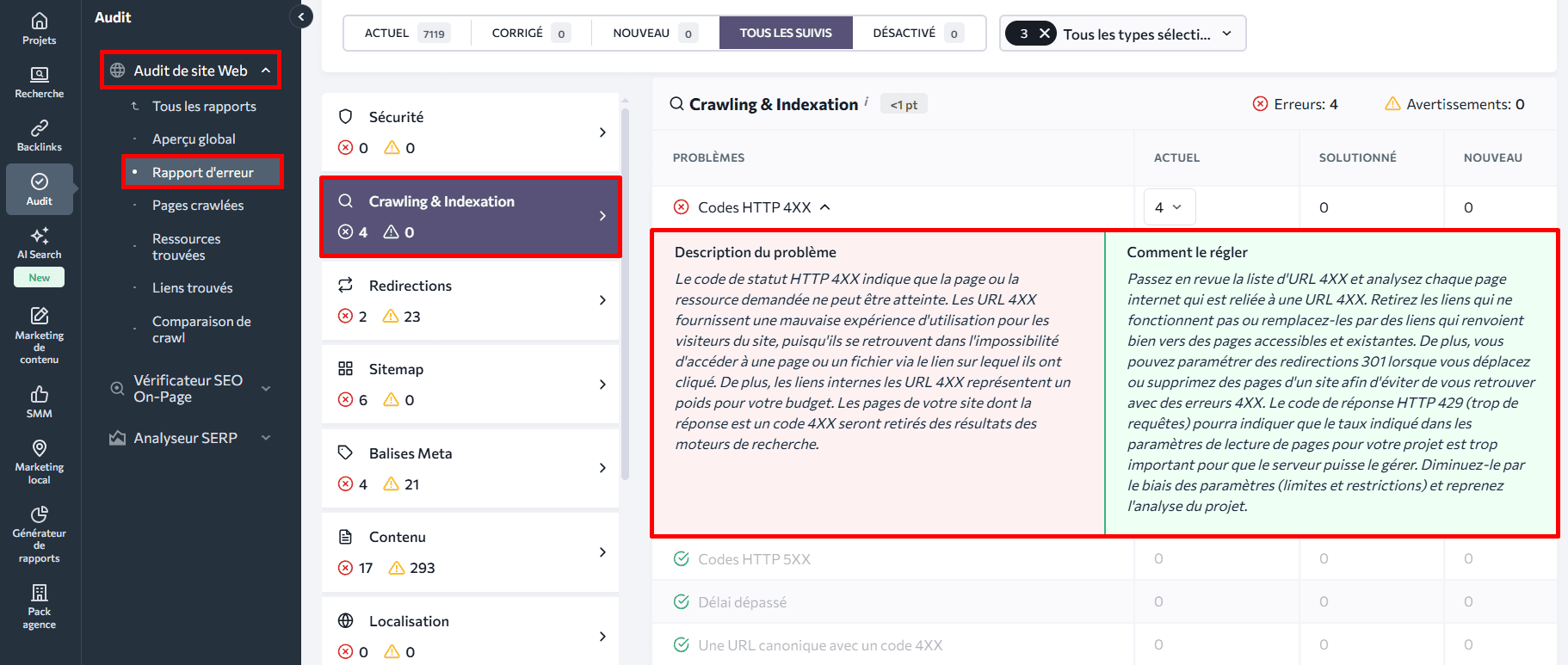
Vous pouvez également utiliser le rapport Pages crawlées pour consulter toutes les pages de votre site analysées par SE Ranking, et filtrer celles qui renvoient un code d’erreur 4xx. Cliquez sur Filtres, choisissez Code de statut HTTP dans Problèmes, sélectionnez le code souhaité, puis cliquez sur Appliquer les filtres.
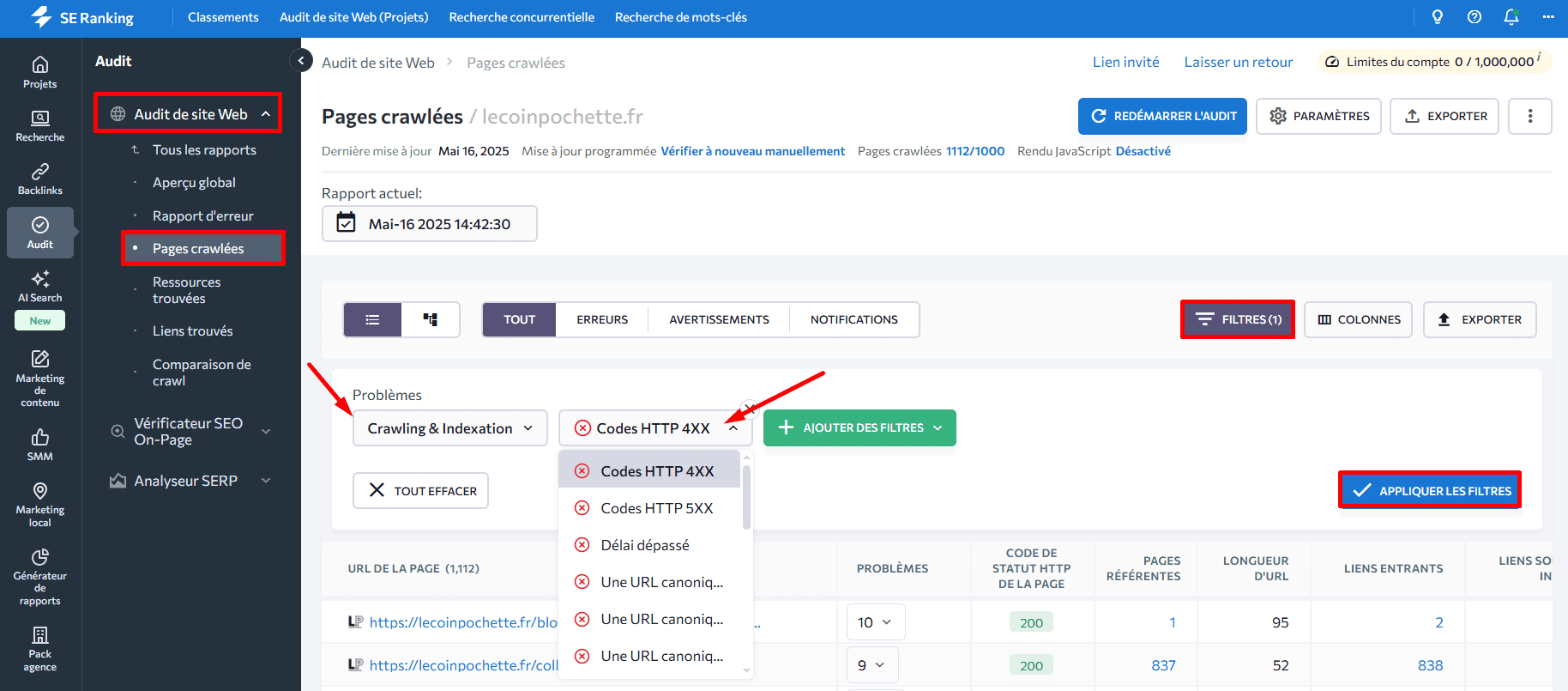
Si vous avez lancé plusieurs audits de site, utilisez la fonctionnalité Comparaison des crawls pour visualiser l’évolution des erreurs HTTP 4xx dans le temps.
Identifier les erreurs 401 et 403 grâce à l’analyse des fichiers logs
Les fichiers logs générés par les serveurs Web contiennent des informations sur chaque requête adressée au serveur, notamment les codes de réponse renvoyés.
Voici comment suivre les erreurs HTTP à partir de l’analyse des logs :
- Accès aux fichiers logs : récupérez les fichiers de logs d’accès générés par votre serveur web. Ces fichiers contiennent des enregistrements détaillés de chaque requête reçue, ainsi que les codes de réponse correspondants.
- Filtrer par code HTTP : utilisez un outil d’analyse de logs ou un script pour isoler les entrées avec les codes HTTP 401 et 403.
- Analyse temporelle des erreurs : examinez les dates et heures associées à chaque entrée pour identifier les moments où les erreurs se sont produites pour mieux comprendre leur origine.
- Analyse des adresses IP et des user agents : examinez les adresses IP et les agents utilisateurs associés aux requêtes qui génèrent des erreurs 401 ou 403. Cela permet d’identifier l’origine des tentatives d’accès et de distinguer les utilisateurs légitimes, les robots ou les menaces potentielles.
- Analyse des URLs et des référents : analysez les URLs et les pages référentes dans les fichiers logs pour identifier les ressources qui ont généré des erreurs 401 ou 403. Cela permet de localiser précisément les problèmes d’accès.
- Erreur l’authentification utilisateur (401) : pour les erreurs 401, examinez les fichiers logs pour identifier les échecs d’authentification. Recherchez les cas où les identifiants sont incorrects, des identifiants erronés ou des sessions expirées.
- Les restrictions d’accès (403) : examinez les fichiers logs pour comprendre les causes du refus d’accès. Vérifiez les autorisations de répertoire, les règles de contrôle d’accès ou toute autre configuration pouvant bloquer l’accès à certaines ressources.
« Bloquée en raison d’une requête non autorisée (401) » dans GSC : comment corriger l’erreur 401
Avant de corriger une page signalée comme « Bloquée en raison d’une requête non autorisée (401) » dans votre site, déterminez si cette page doit réellement être indexée. Toutes les pages d’un site ne sont pas destinées à l’être, — notamment celles protégées par un identifiant. Chaque cas est spécifique, et vous pouvez avoir des raisons particulières d’indexer ce type de contenu. Filtrez les pages présentes dans votre sitemap pour identifier celles qui peuvent ou non être indexées. Vous pouvez également lancer une analyse SEO on-page pour vérifier si une URL a été indexée.
Si vous choisissez d’indexer les pages en erreur 401, vous devrez ajuster les paramètres du serveur pour permettre à Googlebot d’accéder à ces URL, et les traiter différemment des navigateurs classiques.
Attention : afficher un contenu distinct à Google peut être considéré comme du cloaking, une pratique pénalisée. Pour éviter ce risque, appliquez les bonnes pratiques de Google sur les contenus sous abonnement et utilisez des données structurées spécifiques aux pages à contenu payant.
Si vous décidez que les pages en erreur 401 ne doivent pas être indexées, bloquez leur accès dans le fichier robots.txt. Cela permettra d’optimiser le budget de crawl.
Il est également recommandé de modifier ou de supprimer les liens inutiles pointant vers une page en erreur 401 depuis les pages référentes. Cela permet de préserver la cohérence et la qualité de votre maillage interne. Utilisez l’outil Inspection d’URL dans Google Search Console pour repérer les liens qui dirigent les robots vers cette page.

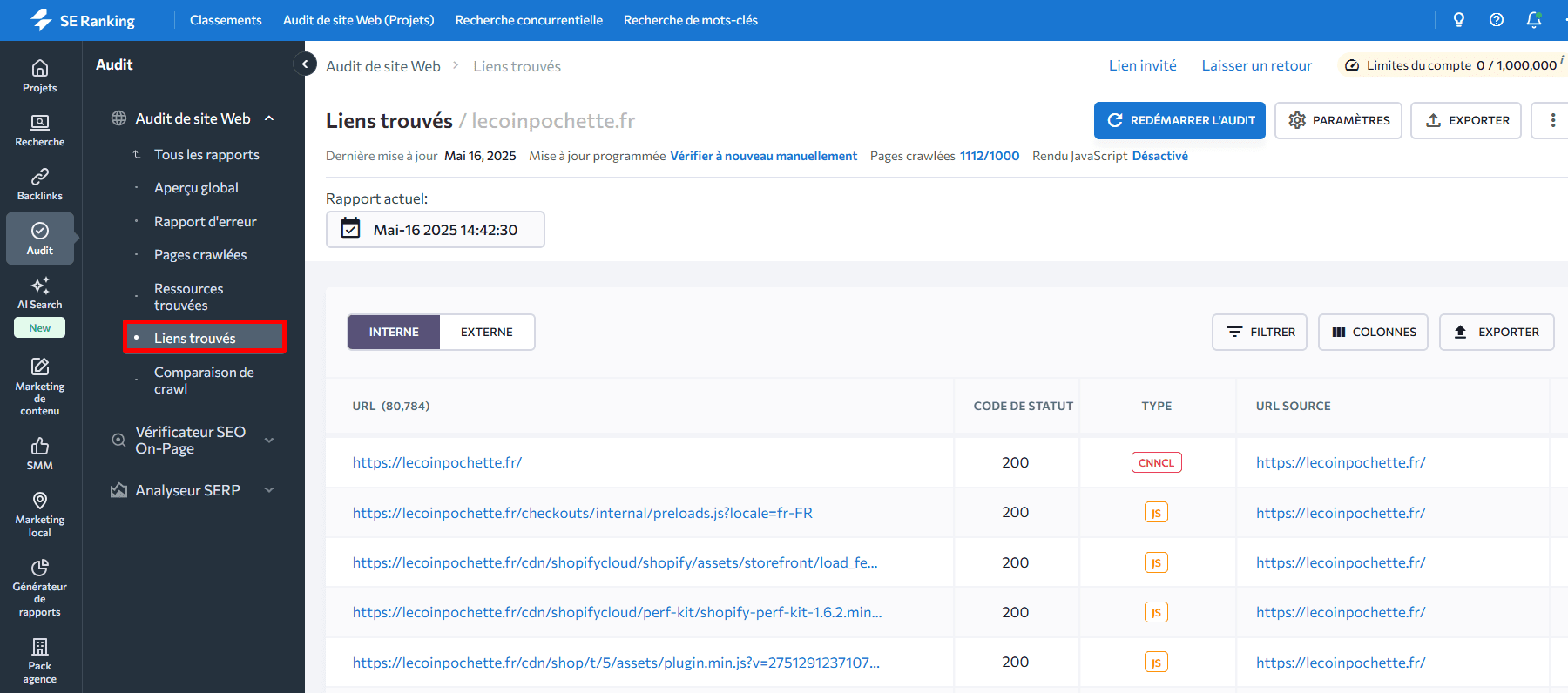
Vous pouvez également utiliser l’outil d’audit de site Web de SE Ranking pour visualiser les liens internes et externes pointant vers les pages de votre site. Accédez au rapport Liens trouvés pour consulter le tableau indiquant les URL de lien, leur code de statut, ainsi que les pages sur lesquelles ces liens ont été détectés. Utilisez les filtres pour faciliter votre recherche.
« Bloquée en raison d’un accès interdit (403) » dans GSC : comment corriger l’erreur 403
Comme pour les erreurs 401, la première étape consiste à décider si l’accès à la page doit être accordé à Googlebot. Si la page est censée rester restreinte, corriger l’erreur 403 n’est peut-être pas nécessaire. Souhaitez-vous vraiment que ces pages soient accessibles à Googlebot ?
Si vous ne souhaitez pas que ces pages soient explorées, vous pouvez en bloquer l’accès à Googlebot via le fichier robots.txt (article en anglais). Cela empêchera les robots de gaspiller des ressources sur des contenus non pertinents. Utilisez les instructions suivantes pour restreindre un dossier ou une URL précise :
- Disallow: /folder-name/
- Disallow: /page-url.html
Si certaines pages doivent être indexées dans les moteurs de recherche, mais rester inaccessibles aux utilisateurs non connectés (comme du contenu payant), il est possible d’en autoriser l’accès à Googlebot. Modifiez la configuration du serveur pour ne pas bloquer ces pages par un mur de connexion.
Attention : si le contenu visible par Googlebot diffère de celui montré aux utilisateurs, vous devez ajouter des données structurées spécifiques pour signaler qu’il s’agit d’un contenu payant. Toutefois, certaines pages de votre site peuvent être destinées à un accès public, mais renvoient actuellement un code 403 à Googlebot pour différentes raisons.
Voyons ensemble les causes et les solutions possibles :
- Erreurs dans le fichier .htaccess : désactivez le fichier .htaccess existant, puis générez-en un nouveau. Vous pourrez ensuite tester l’exploration de vos pages comme le ferait Googlebot pour vérifier si le problème a été résolu.
- Permissions des fichiers : assurez-vous que les fichiers que vous souhaitez rendre accessibles aux moteurs de recherche disposent des autorisations nécessaires. Si ce n’est pas le cas, appliquez les bons niveaux de permission pour permettre leur exploration.
- Plugins WordPress : si vous utilisez un CMS comme WordPress, certaines erreurs 403 peuvent être causées par des extensions obsolètes ou incompatibles. Assurez-vous que toutes vos extensions sont compatibles avec votre version de WordPress. Désactivez-les une par une pour identifier la source du problème.
- Adresse IP incorrecte : vérifiez que l’enregistrement A (A-record) de votre domaine ou sous-domaine pointe bien vers la bonne adresse IPv4. Une mauvaise configuration peut provoquer un accès restreint et entraîner des erreurs 403.
- Infection par le malware : vérifiez si votre site a été vérifié, ou si votre site a été compromis par un malware. En cas d’infection, supprimez immédiatement les fichiers malveillants pour rétablir un accès normal aux pages.
- Problèmes liés à l’hébergement : si aucune des solutions précédentes ne fonctionne, il est conseillé de contacter votre hébergeur. L’erreur 403 peut aussi provenir d’un dysfonctionnement de leur côté.
Conclusion
Comprendre les différences entre les erreurs 401 et 403 est essentiel pour garantir un site performant et bien optimisé. Ces codes de statut HTTP ont un impact direct sur le référencement, et influencent l’indexation, l’utilisation du budget de crawl, l’expérience utilisateur et, à terme, le positionnement dans les résultats de recherche.

