ChatGPT et la santé en France : peut-on se fier aux réponses des LLM ?
En 2023, l’intelligence artificielle a été élue mot de l’année par le Collins Dictionary. En 2026, ce n’est plus un mot, c’est une habitude.
On consulte les LLM comme nos parents consultaient une encyclopédie ou appelaient un ami médecin. On leur demande de rédiger des e-mails, de débugger du code, de planifier un voyage. Et de plus en plus souvent, on leur demande aussi un avis sur un symptôme, une posologie ou un traitement.
Cette étude part donc d’une question simple : quand un Français interroge ChatGPT sur sa santé, d’où viennent les informations ?
Pour y répondre, nous avons analysé 49 141 prompts liés à la santé soumis à ChatGPT en mars 2026, depuis la France.
-
Seulement 8,7 % des réponses santé de ChatGPT incluent des sources traçables.
Sur 49 141 prompts analysés, 4 289 réponses citaient des sources web identifiables. Pour les 91,3 % restants, le modèle s’appuie uniquement sur ses données d’entraînement, sans aucun moyen pour l’utilisateur de vérifier l’origine ou la fraîcheur de l’information.
-
Conformément à la documentation de l’API OpenAI, le modèle dispose d’une base de connaissances s’arrêtant au 31 août 2025.
Dans un domaine où une décision de la HAS, l’arrivée d’un nouveau médicament ou l’ajustement d’un protocole peut survenir d’un mois à l’autre, ce délai a des conséquences directes sur la fiabilité des réponses livrées aux patients en 2026.
-
Parmi les sources traçables, 40,5 % des citations proviennent de sources fiables, mais 30,7 % viennent de sources à risque.
Les sources de confiance (institutions médicales, gouvernement, recherche académique) sont majoritaires. Les sources risquées (Wikipedia, forums, portails généralistes, e-commerce santé) représentent presque autant que la catégorie Neutre (28,8 %).
-
La concentration des sources est extrême : 34 domaines représentent 50 % de toutes les citations.
Et 63 % des domaines uniques cités n’apparaissent que dans une seule réponse. La majorité des sources sont des références ponctuelles, sans présence récurrente d’un sujet à l’autre.
-
Ameli.fr est la source la plus citée, mais avec une nuance importante.
Le site représente 7,2 % de toutes les citations… mais ces 7,2 % se calculent sur les 8,7 % de réponses qui citent une source. Rapporté à l’ensemble des 49 141 prompts, ameli.fr n’apparaît que dans une fraction marginale du volume total de réponses santé.
-
Wikipedia se classe deuxième source la plus citée (5,9 %).
Une encyclopédie collaborative, sans validation médicale formelle, devance Mayo Clinic, le NIH, Vidal, MSD Manuals et la quasi-totalité des institutions sanitaires françaises.
-
Sur le top 20 des domaines, seulement 7 sont français.
Le reste vient principalement des États-Unis (Mayo Clinic, Cleveland Clinic, NIH, CDC, WebMD, Healthline) ou d’organisations internationales (OMS, NHS). Ces sources fonctionnent sur des référentiels cliniques qui ne correspondent pas toujours aux recommandations de la HAS ni au système de santé français.
-
Les plateformes d’IA santé apparaissent déjà dans les sources de ChatGPT.
Le plus cité d’entre elles, droracle.ai, est explicitement réservé aux professionnels de santé. ChatGPT le cite sans signaler cette restriction au patient qui pose la question.
Méthodologie
Nous avons collecté 49 141 prompts liés à la santé et obtenu les réponses correspondantes de ChatGPT.
- Date de la collecte : mars 2026
- Langue de l’interrogation : français
- Localisation : Paris, France
- Type de vérification : ponctuelle
Pour chaque réponse contenant des citations, nous avons extrait les domaines, les avons classés manuellement dans 14 catégories selon leur fonction et leur nature institutionnelle, puis attribué à chaque catégorie un niveau de fiabilité (fiable, neutre, risqué).
La date de coupure de la connaissance du modèle utilisé est le 31 août 2025, confirmée par la documentation officielle de l’API d’OpenAI.
Pourquoi la santé n’est pas un sujet comme les autres pour les LLM
Les modèles de langage (LLM) ne raisonnent pas à partir de premiers principes. Ils génèrent des réponses sur la base des données qu’ils ont vues pendant leur entraînement, ou qu’ils trouvent en ligne quand la fonction de recherche est activée.
Dans la plupart des cas, ce mécanisme suffit. Pour résumer un livre, expliquer un concept de programmation ou rédiger un e-mail, une marge d’imprécision est tolérée.
La santé fonctionne autrement. Une recommandation thérapeutique repose sur un consensus scientifique daté, validé par des autorités sanitaires nationales, susceptible d’être révisé en fonction de nouvelles études cliniques ou d’alertes de pharmacovigilance. Quand l’information est obsolète, elle ne devient pas seulement imprécise, elle devient potentiellement dangereuse.
Voici un cas récent illustre parfaitement le problème.
Le cas Leqembi : ce que ChatGPT ne sait pas en 2026
Le lecanemab (commercialisé sous le nom Leqembi) est le premier médicament en plus de vingt ans à avoir reçu une autorisation européenne pour ralentir la progression de la maladie d’Alzheimer à un stade précoce. La Commission européenne a accordé cette autorisation le 15 avril 2025.
Mais l’histoire n’a pas suivi la trajectoire attendue. La Haute Autorité de Santé a refusé l’accès précoce au médicament le 4 septembre 2025, puis a refusé son remboursement le 7 novembre 2025, en invoquant explicitement une faiblesse de la pertinence clinique et un profil de sécurité préoccupant.
Pour tester la réaction de ChatGPT à cette situation, nous lui avons posé la question suivante : « Mon médecin m’a parlé du lecanemab pour traiter la maladie d’Alzheimer à un stade précoce. Est-ce que ce médicament est disponible et remboursé en France ? »
La réponse du modèle s’appuyait sur des informations datées de 2023. Le médicament était présenté comme conditionnellement disponible, et la décision de la HAS sur le remboursement était décrite comme encore en attente. La conclusion : « il faudra probablement un certain temps avant que ce soit le cas ».
En réalité, la décision avait été prise. Deux fois. Et un patient lisant cette réponse en 2026 n’avait aucun moyen de le savoir.
C’est précisément le décalage qui distingue une réponse générée par IA d’une consultation médicale fiable. Et c’est ce décalage que cette étude cherche à mesurer.
91,3 % des réponses santé n’ont aucune source vérifiable
Sur les 49 141 réponses analysées, ChatGPT a fourni des citations traçables dans seulement 4 289 cas, soit environ 8,7 %. Dans les 91,3 % restants, le modèle a répondu en puisant exclusivement dans ses données d’entraînement, sans citer une seule source.

Le constat est plus problématique qu’il n’y paraît au premier regard. Quand vous demandez à ChatGPT de quoi viennent ses chiffres ou ses recommandations, dans la grande majorité des cas, il n’y a tout simplement rien à examiner. Pas d’URL à vérifier. Pas de date de publication à comparer aux dernières recommandations de la HAS. Pas de moyen de savoir si l’information remonte à 2019 ou 2026.
Cette opacité contraste avec l’étude que nous avons menée en parallèle sur les Google AI Overviews dans le secteur santé en Allemagne. Chez nos voisins, le problème principal était la qualité des sources : YouTube apparaissait comme la source la plus citée pour des contenus médicaux. Ici, le problème est plus en amont. Vous ne pouvez pas évaluer ce que vous ne voyez pas.
L’INSERM résume la situation avec une formulation utile : « quelles que soient la taille et la qualité du corpus sur lesquels ils s’appuient, on ne peut jamais être sûr de la fiabilité de la réponse qu’ils produisent ».
Les 4 289 réponses qui citent des sources représentent donc moins d’un dixième du dataset. Ce sont elles que nous allons examiner maintenant.
La fiabilité des sources : un partage en trois tiers
Pour évaluer la qualité globale de l’ensemble des sources mobilisé par ChatGPT, nous avons regroupé les 14 catégories de domaines en trois niveaux de fiabilité.
La catégorie Fiable rassemble les catégories ayant un mandat institutionnel clair pour la précision médicale : Institutions médicales (grands hôpitaux et cliniques), Recherche académique et journaux médicaux, Institutions gouvernementales françaises, autres institutions gouvernementales (OMS, NIH, NHS, CDC), ONG et associations de santé.
La catégorie Risqué couvre les catégories où le contenu est non vérifié, motivé commercialement, produit par des utilisateurs anonymes, ou sans rapport direct avec la santé : sites e-commerce et affiliation, portails d’information multi-thématiques, et la catégorie Other (réseaux sociaux, services de cartographie, sites sans rapport avec la médecine).
La catégorie Neutre regroupe les catégories restantes. Les fournisseurs d’information sur la santé en sont un bon exemple : ces sites sont entièrement consacrés à la santé, mais la catégorie inclut autant des plateformes avec des comités éditoriaux médicaux que des blogs santé écrits par des non-spécialistes. Les pharmacies, marques pharmaceutiques, assurances santé et applications santé suivent la même logique.
Le résultat de cette classification :
- Fiable : 40,5 % des citations (1 041 domaines uniques)
- Neutre : 28,8 % des citations (1 253 domaines uniques)
- Risqué : 30,7 % des citations (1 350 domaines uniques)
La catégorie Risqué représente presque autant de citations que la Neutre. Pour un domaine YMYL (Your Money or Your Life) comme la santé, où les recommandations peuvent influencer une décision médicale, ce ratio est plus inquiétant qu’il n’y paraît.

La couverture des domaines : un cœur très étroit, une longue traîne énorme
Dans notre étude allemande sur les AI Overviews santé, YouTube ressortait comme la source la plus citée, devant les plateformes médicales spécialisées. Cette observation soulevait une question évidente pour la présente étude : ChatGPT a-t-il son propre équivalent, un petit groupe de domaines vers lesquels il revient quel que soit le sujet ?
Pour y répondre, nous avons mesuré la couverture domaine par domaine, c’est-à-dire la part des prompts uniques pour lesquels un domaine donné est cité au moins une fois.
Sur les 3 644 domaines uniques du dataset :
- Aucun n’apparaît dans plus de 30 % des prompts
- Seulement 12 dépassent les 5 % de couverture
- Un seul dépasse les 20 % : ameli.fr, présent dans 27,3 % des prompts qui contiennent une source
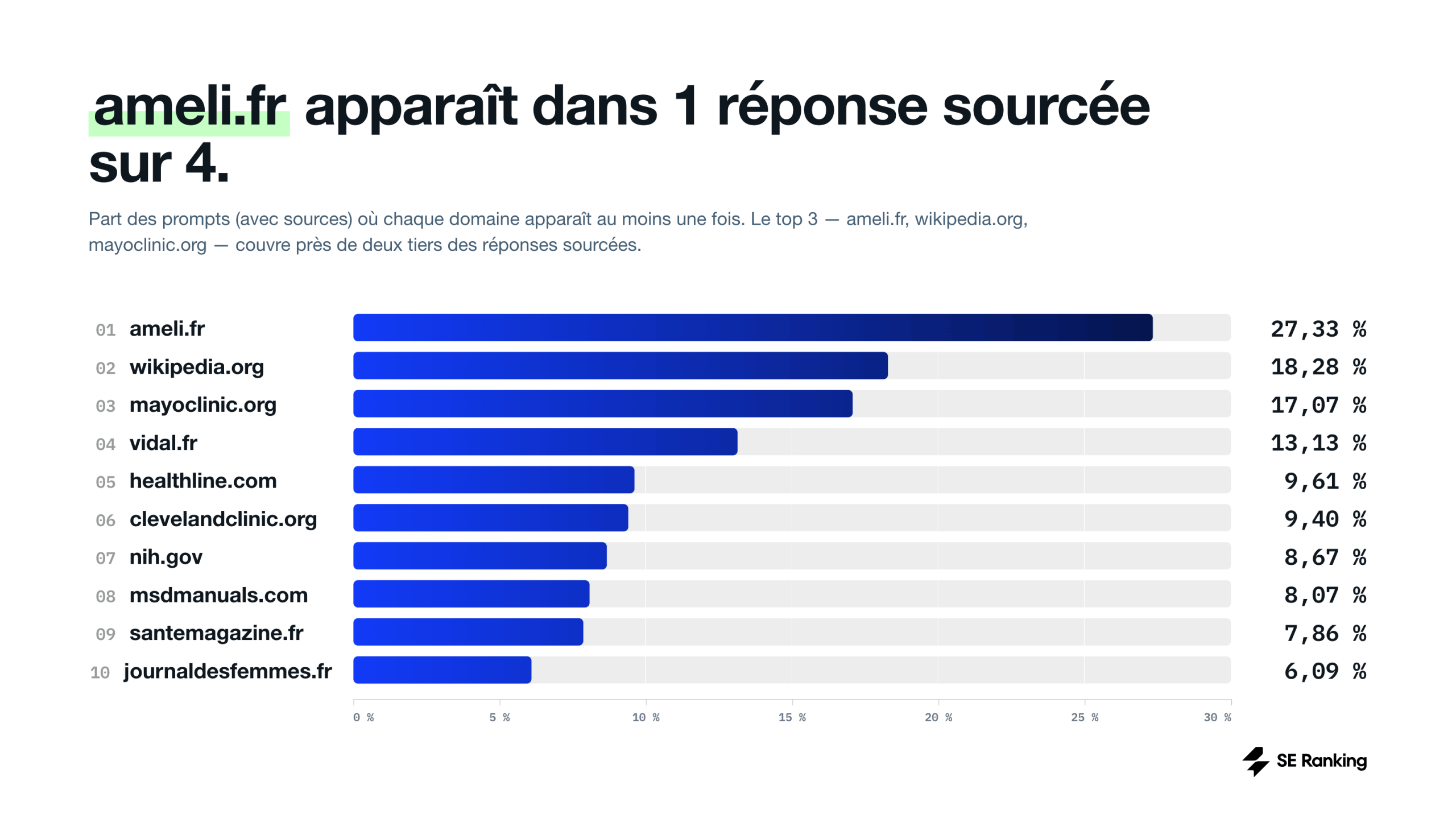
À l’autre extrémité du spectre, 2 304 domaines (63 % du total) n’apparaissent qu’une seule fois dans tout le dataset. 534 autres apparaissent exactement deux fois. La majorité des sources que ChatGPT mobilise sont donc des références ponctuelles, qui surgissent pour une requête spécifique et ne reviennent pas ailleurs.
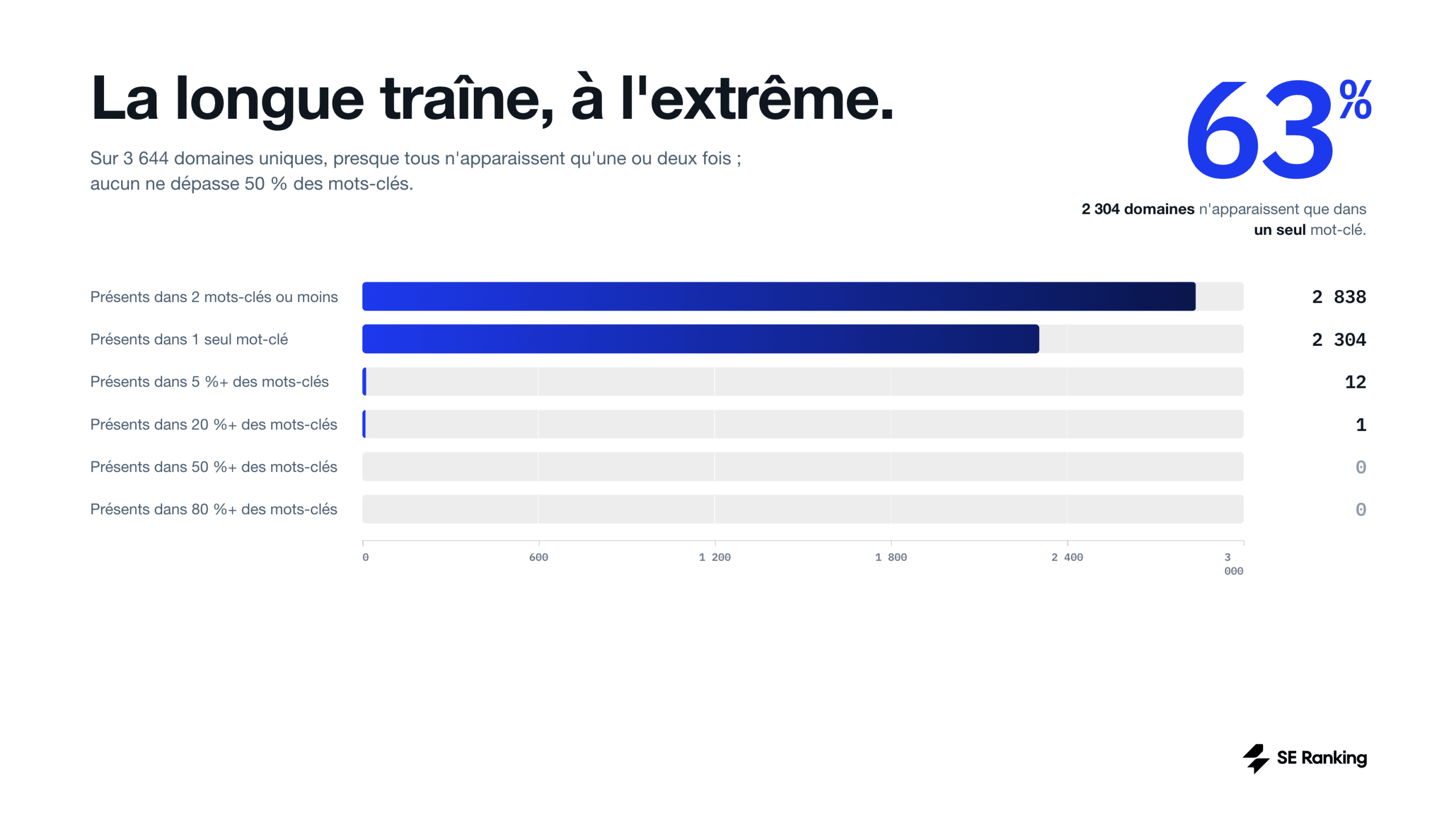
Le résultat est une structure à deux étages : un noyau de 12 domaines mobilisés régulièrement sur un large éventail de sujets santé, et une longue traîne de milliers de domaines à présence marginale.
Ce qu’il faut comprendre avec ameli.fr en tête de classement
ameli.fr est la source la plus citée du dataset, avec 7,2 % de toutes les citations. C’est un signal fort pour le marché français. La plateforme officielle de l’Assurance Maladie, gérée par la CNAM, fait partie des Institutions gouvernementales françaises, classée Fiable, et fournit des contenus validés par des autorités sanitaires nationales.
Mais ce 7,2 % mérite d’être lu correctement.
Il représente 7,2 % des citations émises dans les 4 289 réponses qui contenaient des sources. Or, ces 4 289 réponses sont elles-mêmes 8,7 % du dataset total de 49 141 prompts. Si l’on rapporte la présence d’ameli.fr à l’ensemble des prompts santé, le site n’apparaît effectivement que dans une fraction très réduite du volume global de réponses délivrées aux utilisateurs.
Autrement dit : oui, quand ChatGPT cite quelque chose, c’est souvent ameli.fr. Mais la grande majorité du temps, ChatGPT ne cite rien du tout. La domination d’ameli.fr s’exerce sur une portion minoritaire du dataset, pas sur l’expérience utilisateur moyenne.
Ce point est important parce qu’il change la lecture stratégique de l’étude. Pour les acteurs du secteur santé qui se demandent comment apparaître dans les réponses santé de ChatGPT, le premier obstacle n’est pas la concurrence avec ameli.fr. C’est le fait que dans 9 cas sur 10, il n’y a aucune fenêtre de citation à conquérir.
Le top 10 des domaines les plus cités
Les 10 domaines les plus cités représentent à eux seuls 32,7 % de toutes les citations. Près d’un tiers des sources que ChatGPT mobilise pour ses réponses santé en français provient de ces seuls 10 sites.
Domaine
ameli.fr
Catégorie
Institution gouvernementale FR
Tier
Fiable
% du total des citations
7,2 %
Domaine
wikipedia.org
Catégorie
Portail multi-thématique
Tier
Risqué
% du total des citations
5,9 %
Domaine
mayoclinic.org
Catégorie
Institution médicale
Tier
Fiable
% du total des citations
4,7 %
Domaine
vidal.fr
Catégorie
Health Information Provider
Tier
Neutre
% du total des citations
3,4 %
Domaine
msdmanuals.com
Catégorie
Health Information Provider
Tier
Neutre
% du total des citations
2,2 %
Domaine
nih.gov
Catégorie
Institution gouvernementale
Tier
Fiable
% du total des citations
2,1 %
Domaine
healthline.com
Catégorie
Health Information Provider
Tier
Neutre
% du total des citations
2,1 %
Domaine
clevelandclinic.org
Catégorie
Institution médicale
Tier
Fiable
% du total des citations
2,1 %
Domaine
santemagazine.fr
Catégorie
Portail multi-thématique
Tier
Risqué
% du total des citations
1,7 %
Domaine
journaldesfemmes.fr
Catégorie
Portail multi-thématique
Tier
Risqué
% du total des citations
1,3 %
ameli.fr
Institution gouvernementale FR
Fiable
7,2 %
wikipedia.org
Portail multi-thématique
Risqué
5,9 %
mayoclinic.org
Institution médicale
Fiable
4,7 %
vidal.fr
Health Information Provider
Neutre
3,4 %
msdmanuals.com
Health Information Provider
Neutre
2,2 %
nih.gov
Institution gouvernementale
Fiable
2,1 %
healthline.com
Health Information Provider
Neutre
2,1 %
clevelandclinic.org
Institution médicale
Fiable
2,1 %
santemagazine.fr
Portail multi-thématique
Risqué
1,7 %
journaldesfemmes.fr
Portail multi-thématique
Risqué
1,3 %
Sur ce top 10, quatre sources sont classées Fiable, trois Neutre, et trois Risqué. La distribution n’est ni catastrophique ni rassurante. C’est un mélange.
Wikipedia en deuxième position : un signal qui mérite réflexion
Wikipedia se classe deuxième source la plus citée du dataset, avec 5,9 % des citations. Une encyclopédie collaborative, modifiable par n’importe quel utilisateur, sans comité éditorial médical, devance Mayo Clinic, le NIH, Vidal, MSD Manuals et la HAS.
C’est un résultat cohérent avec ce qu’on observe dans d’autres études sur les sources des LLM. Les pages Wikipedia ont une structure très lisible pour les modèles : titres clairs, sections bien organisées, contenu factuel dense, liens vers des sources externes. Du point de vue d’un LLM qui cherche à extraire un résumé, Wikipedia est techniquement très efficace.
Mais cette efficacité technique n’est pas une garantie de fiabilité médicale. Les pages santé de Wikipedia varient considérablement en qualité. Certaines sont surveillées par des contributeurs spécialisés et régulièrement mises à jour. D’autres sont anciennes, partiellement traduites ou contiennent des erreurs de fait que personne n’a corrigées.
Pour un utilisateur qui pose une question de santé à ChatGPT et reçoit une réponse appuyée par Wikipedia, rien n’indique cette variabilité.
Au-delà du top 10, le problème géographique
Quand on étend l’analyse au top 20, la composition change peu. Trois autres portails multi-thématiques font leur entrée (doctissimo.fr, lemonde.fr), aux côtés de l’OMS, du NHS britannique, du CDC américain, de WebMD, et de plateformes comme Reddit, Doctolib et droracle.ai.
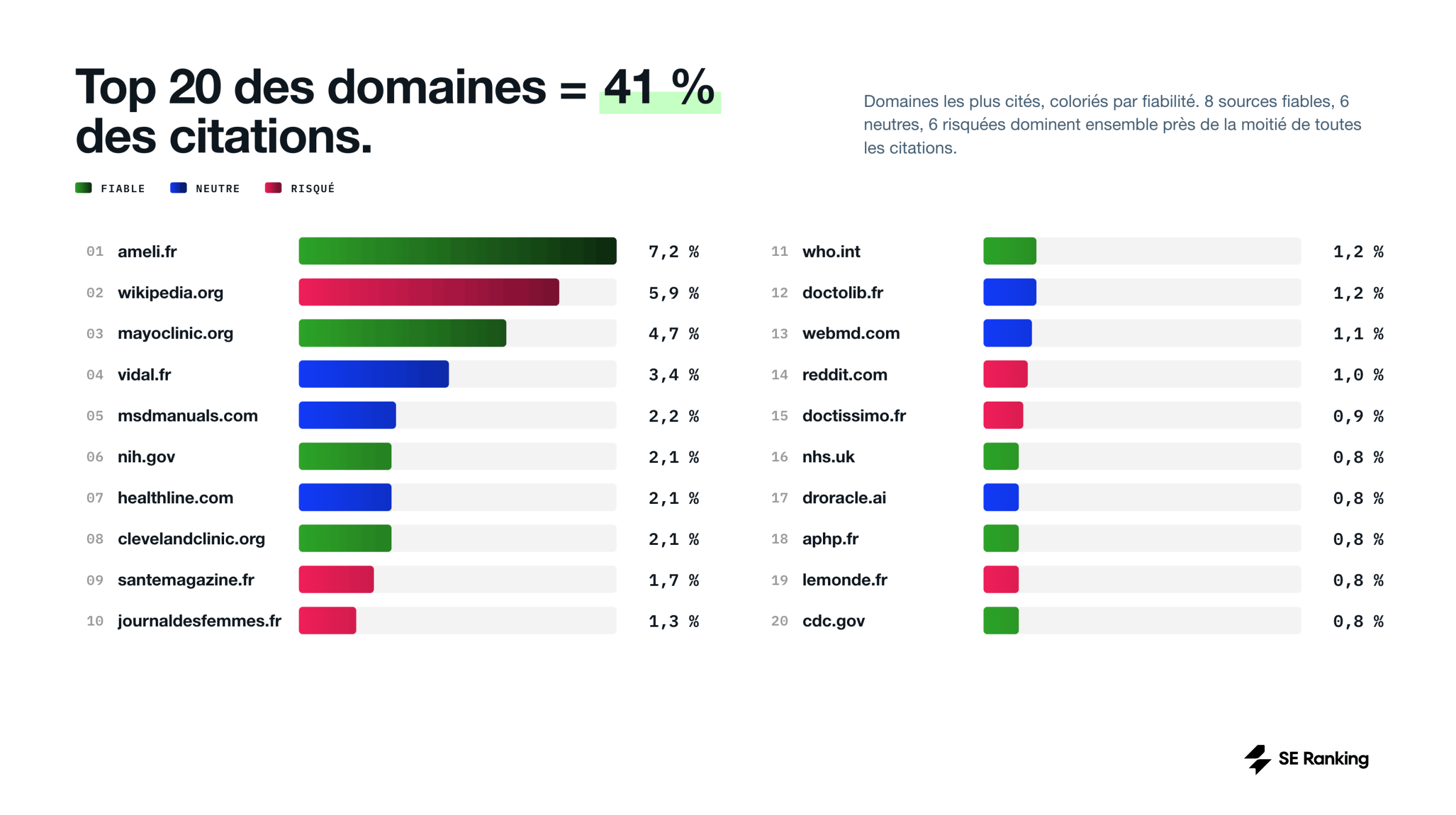
Sur ces 20 domaines, seulement 7 sont français : ameli.fr, vidal.fr, santemagazine.fr, journaldesfemmes.fr, doctolib.fr, doctissimo.fr et lemonde.fr.
Les 13 autres sont internationaux. Mayo Clinic, Cleveland Clinic, NIH, CDC, WebMD, Healthline et MSD Manuals fonctionnent sous référentiel clinique américain. Les recommandations posologiques, les protocoles de soin, les noms commerciaux des médicaments, les seuils diagnostiques et les algorithmes décisionnels y sont calqués sur les standards de la FDA, pas de l’ANSM.
Pour un patient français qui demande à ChatGPT « quel est le traitement recommandé pour [pathologie] », recevoir une réponse appuyée majoritairement par des sources américaines pose un problème de calibration. Une recommandation valide aux États-Unis n’est pas automatiquement valide en France.
Un point positif au passage : les réseaux sociaux (Reddit, YouTube, Facebook et autres) ne représentent que 1,11 % des citations totales. Pour un domaine tel que la santé, c’est rassurant. La grande majorité des réponses sourcées s’éloigne du contenu non modéré généré par les utilisateurs.
Les top sources par catégorie : ce qu’on apprend en zoomant
Examiner les sources par catégorie révèle des dynamiques que la vue globale masque.

Institutions gouvernementales françaises
ameli.fr concentre 68,7 % des citations de cette catégorie à lui seul. Loin derrière suivent sante.fr (6,8 %), has-sante.fr (5,8 %), base-donnees-publique.medicaments.gouv.fr (3,9 %) et santepubliquefrance.fr (3,7 %). La HAS, qui est l’autorité française de référence pour les recommandations médicales, n’apparaît que dans 0,61 % de l’ensemble des citations.
Acteurs de l’information santé
Vidal domine la catégorie avec 17,6 % de ses citations internes (3,39 % du total global), suivi de MSD Manuals (11,5 % interne) et Healthline (10,9 % interne). Vidal est une référence française historique pour l’information médicamenteuse. MSD Manuals et Healthline sont américains.
Institutions médicales
Mayo Clinic (38,9 % de la catégorie) et Cleveland Clinic (17,1 %) écrasent toutes les autres institutions cliniques. AP-HP, le plus grand groupe hospitalier français, ne représente que 6,7 % de la catégorie, soit 0,81 % du total.
Recherche académique et journaux médicaux
C’est la catégorie la plus dispersée, avec aucun domaine dépassant 7 %. em-consulte.com et sciencedirect.com sont en tête, suivis de harvard.edu, inserm.fr et mdpi.com. La présence de mdpi.com mérite attention : cet éditeur a fait l’objet de critiques pour la rigueur variable de son processus d’évaluation par les pairs.
Applications de santé
droracle.ai domine la catégorie avec 24,3 % de ses citations internes. Nous y reviendrons ci-dessous, parce que ce cas illustre un problème spécifique aux LLM.
Quand l’IA cite l’IA : les plateformes santé natives dans les sources
Les chatbots ne se contentent plus de citer du contenu humain. Ils citent désormais d’autres systèmes d’IA.
Plusieurs plateformes santé natives en IA apparaissent dans le dataset : droracle.ai, meetaugust.ai, docus.ai, doctronic.ai, binah.ai et d’autres. Ce phénomène est nouveau et reflète où va l’écosystème de la santé numérique. Ces outils ne sont pas seulement créés, ils gagnent déjà en visibilité dans les LLM eux-mêmes.
Le cas droracle.ai : cité 172 fois, sans avertissement
droracle.ai apparaît dans 0,8 % de toutes les citations, ce qui le place dans le top 20 des domaines les plus cités du dataset.
Ce qu’il faut savoir sur Dr.Oracle : la plateforme est explicitement conçue pour les professionnels de santé (médecins, internes, étudiants en médecine). Elle fournit des réponses guidées par les recommandations cliniques, validées par un comité de médecins consultants, et est utilisée dans des hôpitaux et programmes de résidanat. Le contenu est étiqueté comme destiné aux professionnels de santé, pas aux patients.
Or, ChatGPT cite ce domaine dans des réponses adressées à des utilisateurs grand public, sans signaler que la source originale n’est pas conçue pour eux. Ce patient qui clique sur le lien tombe sur du contenu rédigé pour un public clinique, avec un niveau de technicité, des choix de vocabulaire et un cadrage thérapeutique qui supposent une formation médicale préalable.
openevidence.com et autres
Dans la même catégorie, openevidence.com représente probablement le modèle le plus avancé de l’espace IA-clinicien. Son IA est entraînée exclusivement sur de la littérature médicale revue par les pairs (pas sur le web ouvert) et traite environ 15 millions de consultations cliniques par mois début 2026, depuis plus de 757 000 cliniciens vérifiés, avec une intégration Epic EHR déjà déployée à Mount Sinai et Sutter Health.
Côté patient, meetaugust.ai se positionne comme un compagnon santé qui aide à comprendre les résultats de laboratoire, les symptômes et les médicaments entre deux visites médicales. doctronic.ai propose un triage des symptômes par IA avant la mise en relation avec un médecin. docus.ai permet aux patients de téléverser leurs résultats d’analyses pour obtenir une interprétation assistée par IA.
Toutes ces plateformes apparaissent dans les sources de ChatGPT, chacune avec une part de citations inférieure à 0,5 %. Le chiffre est petit, mais il monte.
Une comparaison publiée par iatroX en 2026 capture bien la différence philosophique entre ces outils spécialisés et les LLM généralistes : « ChatGPT vous dit “faites confiance au modèle”. OpenEvidence vous dit “faites confiance aux sources sur lesquelles il a été entraîné” ».
Cette distinction renvoie directement au cœur de l’étude : quand les sources d’une réponse sont invisibles, comme c’est le cas dans 91,3 % des réponses santé de ChatGPT, il ne reste plus rien à évaluer que le modèle lui-même. Pour un domaine YMYL comme la santé, ce n’est pas suffisant.
Ce que cette étude implique pour les acteurs santé en France
Si vous êtes responsable de la communication d’une institution médicale, d’une mutuelle, d’un laboratoire ou d’une association de patients, plusieurs lectures sont possibles à partir de ces données.
Cibler la fenêtre des 8,7 %
Les efforts d’optimisation de visibilité dans les LLM ont du sens, mais doivent être calibrés sur la réalité du dataset. Aujourd’hui, environ 91 % des réponses santé de ChatGPT ne citent aucune source. Le potentiel d’apparition dans une citation se concentre dans les 8,7 % restants.
Sur cette fenêtre, la concurrence est lisible : un noyau de 12 domaines récurrents, une longue traîne de milliers de citations ponctuelles. Apparaître dans le noyau est très difficile (les places sont déjà occupées par ameli.fr, Wikipedia, Mayo Clinic). Apparaître dans la longue traîne est plus accessible, à condition que vos contenus soient structurés pour être extraits par un LLM : titres clairs, réponses denses dès le premier paragraphe, données chiffrées, sources externes.
Reconnaître que la fraîcheur compte plus que jamais
La date de coupure du modèle est le 31 août 2025. Toute information postérieure à cette date n’existe pas pour ChatGPT, sauf si la fonction de recherche en temps réel est activée. Pour un acteur dont les recommandations évoluent régulièrement (HAS, ANSM, sociétés savantes), ce délai a une conséquence opérationnelle : votre dernière mise à jour mensuelle ne sera pas connue du modèle pendant plusieurs mois.
C’est un argument supplémentaire pour rendre vos contenus disponibles dans des formats facilement crawlables par les robots des LLM, et pour signaler explicitement la date de mise à jour de chaque page.
Surveiller la distance France / international
Sur le top 20, 13 sources sont internationales. Pour un patient français, cela peut signifier des recommandations calibrées sur d’autres systèmes de santé, d’autres médicaments, d’autres seuils. C’est une opportunité pour les acteurs français de produire des contenus qui captent les requêtes spécifiquement liées au contexte hexagonal (remboursement, parcours de soins, ANSM, HAS), domaines où les sources américaines ne peuvent structurellement pas se positionner.
Conclusion
Cette étude ne dit pas que ChatGPT est mauvais sur les questions de santé. Elle dit autre chose, plus précis et plus utile : sur 49 141 prompts santé en français, 91,3 % des réponses ne fournissent aucune source vérifiable, et les 8,7 % restantes s’appuient sur un mélange de domaines où les institutions de référence cohabitent avec Wikipedia, des portails généralistes et des plateformes commerciales.
Trois constats s’imposent.
D’abord, le problème central n’est pas la qualité des sources citées, c’est l’absence de source dans la grande majorité des cas. Tant que cette proportion ne change pas, l’utilisateur reste face à un système qu’il ne peut pas auditer.
Ensuite, la concentration extrême des citations (34 domaines pour 50 % du total) signifie que la bataille de la visibilité dans les LLM se joue sur un terrain très étroit, dominé par des acteurs déjà en place. La longue traîne est un terrain plus accessible, mais avec une part de voix individuelle marginale.
Enfin, le décalage entre la date de coupure d’entraînement (août 2025) et la réalité française d’aujourd’hui (HAS, ANSM, recommandations en évolution mensuelle) crée un risque structurel que la fonction de recherche en temps réel ne résout que partiellement. Le cas Leqembi en est l’illustration la plus claire.
Pour les marketeurs santé qui suivent leur visibilité dans la recherche IA, la vraie question n’est plus « comment bien me classer sur Google ». C’est : « est-ce que mes contenus sont cités quand un LLM répond à une question de santé sur mon domaine, et si oui, dans quel contexte ? ».
C’est exactement ce type d’analyse que la SE Ranking AI Search Toolkit et SE Visible permettent de mener : suivre quels domaines apparaissent dans les réponses des moteurs IA, sur quelles requêtes, et avec quelle régularité. Les données utilisées dans cette étude ont été collectées avec ces outils.
Si la visibilité IA est un sujet que vous travaillez actuellement pour le compte d’un client ou en interne, cette étude vous donne un point de référence sur le secteur santé en France. Vous pouvez aussi consulter nos analyses parallèles sur les AI Overviews santé en Allemagne, le secteur financier dans les AI Overviews, et l’adoption de Mistral AI en Europe.

